1. 进程的所有信息对该进程内的所有线程都是共享的
包括 可执行的程序文本、程序全局内存、堆内存以及文件描述符
线程包含了表示进程内执行环境必需的信息,包括线程ID、寄存器值、栈、调度优先级和策略、信号屏蔽字、线程私有数据
判断线程相等时 采用 pthread_equal 函数
线程创建时并不能保证哪个线程会先执行,不能在线程调度上做出任何假设
#include <unistd.h> #include <stdio.h> #include <pthread.h> void printid(const char* str) { pid_t pid = getpid(); pthread_t tid = pthread_self(); fprintf(stdout, "%s pid:%u,tid:%u ", str, (unsigned int)pid, (unsigned int)tid); } void* thread_func(void* arg) { printid("new thread: "); return (void*)0; } int main(int argc, char* argv[]) { pthread_t tid; int ret = pthread_create(&tid, NULL, thread_func, NULL); if (ret != 0) { fprintf(stderr, "pthread_create error "); return -1; } printid("main thread: "); sleep(1); return 0; }
这段代码中需要两个地方需要处理主线程和新线程之间的竞争:
(1)主线程需要休眠,如果主线程不休眠,就可能在新线程有机会运行之前就退出终止了
(2)新线程通过 pthread_self 函数获取自己的线程ID,而不是从共享内存读出或者从线程的启动例程以参数的形式接收到
pthread_create 会通过第一个参数返回新建线程的线程ID,而新线程并不能安全的使用这个ID,因为 新线程可能在 主线程调用 pthread_create 回填线程ID之前就运行了,这时新线程使用的是未经初始化的ID,并不是正确的线程ID
#include <pthread.h> #include <stdio.h> #include <unistd.h> #include <assert.h> #define NTHREADS 5 void* PrintHello(void* threadId) { int tid = ((int)threadId); fprintf(stdout, "Hello world, thread %d ", tid); pthread_exit(NULL); } int main(int argc, char* argv[]) { pthread_t threads[NTHREADS]; int rc = 0; for (int i = 0; i < NTHREADS; ++i) { fprintf(stdout, "In main: creating thread %d ", i); rc = pthread_create(&threads[i], NULL, PrintHello, (void*)i); if (rc != 0) { fprintf(stderr, "error:return code from pthread_create is %d ", rc); exit(-1); } } pthread_exit(NULL); }
上述代码,我们创建了5个线程,每个线程打印一条包含线程编号的语句
可以预想到:每次运行程序时,结果不尽相同。因为 线程创建时并不能保证哪个线程会先执行,不能在线程调度上做出任何假设
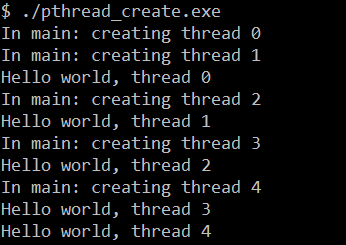
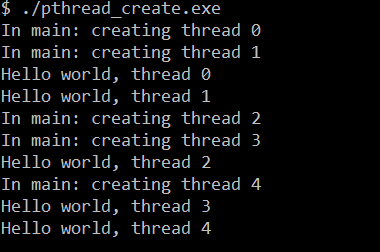
假如我们将上述代码中
rc = pthread_create(&threads[i], NULL, PrintHello, (void*)i);
void* PrintHello(void* threadId) { int tid = ((int)threadId); fprintf(stdout, "Hello world, thread %d ", tid); pthread_exit(NULL); }
改为以下:
rc = pthread_create(&threads[i], NULL, PrintHello, (void*)&i);
void* PrintHello(void* threadId) { int tid = *((int*)threadId); fprintf(stdout, "Hello world, thread %d ", tid); pthread_exit(NULL); }
仅有的差别就是线程执行函数的参数传递不同,执行改过之后的程序:
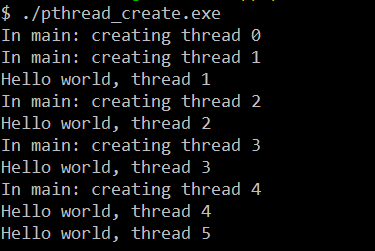
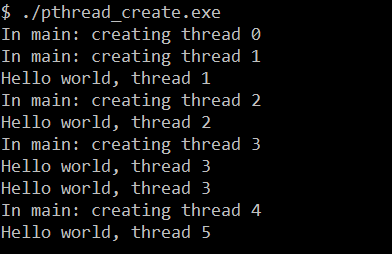
我们可以看到程序执行结果完全不同并且不正确
对于修改前:直接传递 变量i 的值,这是值语义,之后线程操作的只是 变量i 的副本,跟原来的 变量i 没有任何关系,没有竞争出现
对于修改后:传递的是 变量i 的地址(地址),这是引用语义,之后线程操作的是 原变量i,这时多个线程就出现了竞争,
因为这时 变量i 的地址是共享内存,对所有线程可见,其余5个线程通过共享内存在读这个变量i,而主线程通过 i++在写这个变量值
这之间并没有任何同步,所以5个线程读取的值并不正确
#include <stdio.h> #include <unistd.h> #include <pthread.h> #include <stdlib.h> #include <assert.h> #include <math.h> #define NTHREADS 5 void* busywork(void* ptr) { int tid = (int)ptr; fprintf(stdout, "Thread %d starting... ", tid); double result = 0.0; for (int i = 0; i < 1000000; ++i) { result = result + sin(i) * tan(i); } fprintf(stdout, "Thread %d done. Result = %e ", tid, result); pthread_exit((void*)ptr); } int main(int argc, char* argv[]) { pthread_t thread[NTHREADS]; pthread_attr_t attr; /* Initialize and set thread detached attribute */ pthread_attr_init(&attr); pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE); for (int i = 0; i < NTHREADS; ++i) { fprintf(stdout, "Main: creating thread %d ", i); int rc = pthread_create(&thread[i], &attr, busywork, (void*)i); if (rc != 0) { fprintf(stderr, "error:return code from pthread_create is %d ", rc); exit(-1); } } /* Free attribute and wait for the other threads */ void* status; pthread_attr_destroy(&attr); for (int i = 0; i < NTHREADS; ++i) { int rc = pthread_join(thread[i], &status); if (rc != 0) { fprintf(stderr, "error:return code from pthread_join id %d ", rc); exit(-1); } fprintf(stdout, "Main:completed join with thread %d having a status of %d ", i, (int)status); } fprintf(stdout, "Main: program completed. Exiting "); pthread_exit(NULL); }
2.线程可以通过phread_cancel函数来请求取消同一进程中的其它线程
3.进程原语和线程原语的比较
在默认情况下,线程的终止状态会保存到对该线程调用pthread_join,如果线程已经处于分离状态,那么不能用pthread_join函数等待它的终止状态。
3.线程同步
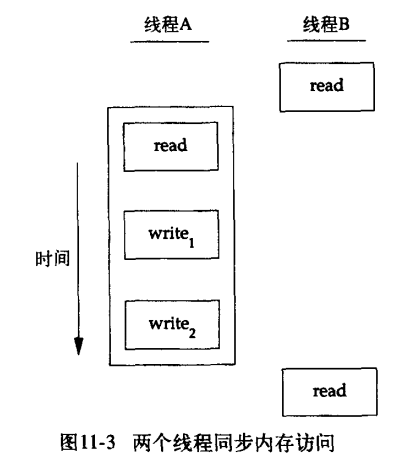
当多个控制线程共享相同的内存时,需要确保每个线程都看到一致的数据视图
(1)读写互斥
在变量修改时间多于1个存储器访问周期的处理器结构中,当存储器读与存储器写这两个周期交叉时,就有潜在的不一致性

为了解决这个问题,线程必须使用锁,在同一时间只允许一个线程访问该变量
(2)写写互斥
当多个线程在同一时间修改同一变量时,也需要同步
变量递增操作:
a.从内存单元读入寄存器
b.在寄存器中进行变量值的增加
c.把新值写回内存单元
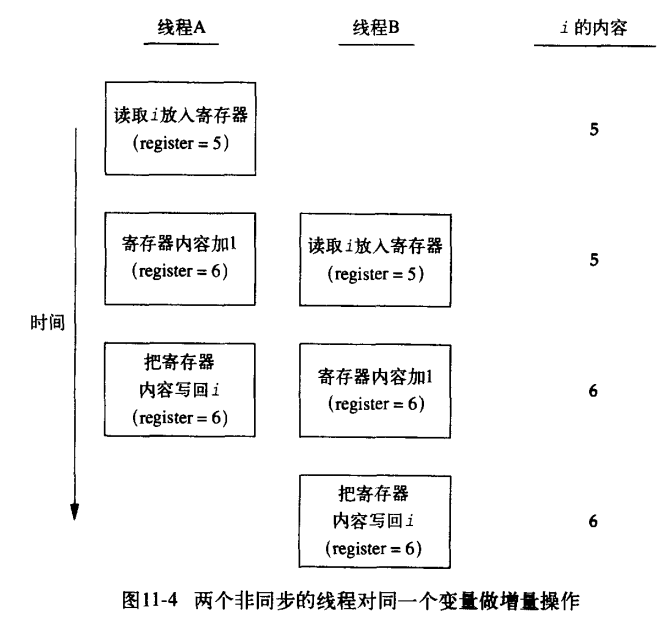
如果修改操作是原子操作,那么就不存在竞争。然而在现代计算机系统中,存储器访问需要多个总线周期,通常在多个处理器上交叉进程
(3) 互斥量
对互斥量进行加锁以后,任何其它试图再次对互斥量加锁的线程将会被阻塞直到当前线程释放该互斥锁
#include <unistd.h> #include <stdio.h> #include <stdlib.h> #include <pthread.h> struct foo { int f_count; pthread_t f_lock; /* more stuff here... */ }; struct foo* foo_alloc(void) { struct foo* fp = malloc(sizeof(struct foo)); if (fp != NULL) { fp->f_count = 1; int ret = pthread_mutex_init(&fp->f_lock, NULL); if (ret != 0) { free(fp); return NULL; } } return fp; } /* increase a reference to the object */ void foo_increase(struct foo* fp) { assert(fp != NULL); pthread_mutex_lock(&fp->f_lock); fp->f_count++; pthread_mutex_unlock(&fp->f_lock); } /* decrease a reference to the object */ void foo_decrease(struct foo* fp) { assert(fp != NULL); pthread_mutex_lock(&fp->f_lock); if (--fp->f_count == 0) { pthread_mutex_unlock(&fp->f_lock); pthread_mutex_destroy(&fp->f_lock); free(fp); } else { pthread_mutex_unlock(&fp->f_lock); } }
4.避免死锁
两个线程都在相互请求另一个线程拥有的资源,这两个线程都无法向前运行,就产生了死锁
1 #include <unistd.h> 2 #include <stdio.h> 3 #include <stdlib.h> 4 #include <assert.h> 5 #include <pthread.h> 6 7 #define NHASH 29 8 #define HASH(fp) (((unsigned long)(fp)) % NHASH) 9 10 pthread_mutex_t hashlock = PTHREAD_MUTEX_INITIALIZER; 11 12 struct foo { 13 struct foo* f_next; 14 int f_count; 15 pthread_mutex_t f_lock; 16 int f_id; 17 /* more stuff here... */ 18 }; 19 20 struct foo* fh[NHASH]; 21 22 struct foo* foo_alloc(void) 23 { 24 struct foo* fp = malloc(sizeof(struct foo)); 25 if (fp != NULL) { 26 fp->f_count = 1; 27 int ret = pthread_mutex_init(&fp->f_lock, NULL); 28 if (ret != 0) { 29 free(fp); 30 return NULL; 31 } 32 int idx = HASH(fp); 33 pthread_mutex_lock(&hashlock); 34 fp->f_next = fh[idx]; 35 fh[idx] = fp->f_next; 36 pthread_mutex_lock(&fp->f_lock); 37 pthread_mutex_unlock(&hashlock); 38 39 /* continue initialization...... */ 40 pthread_mutex_unlock(&fp->f_lock); 41 } 42 return fp; 43 } 44 45 /* increase a reference to the object */ 46 void foo_increase(struct foo* fp) 47 { 48 assert(fp != NULL); 49 pthread_mutex_lock(&fp->f_lock); 50 fp->f_count++; 51 pthread_mutex_unlock(&fp->f_lock); 52 } 53 54 /* find an existing object */ 55 struct foo* foo_find(int id) 56 { 57 struct foo* fp; 58 int idx = HASH(fp); 59 pthread_mutex_lock(&hashlock); 60 for (fp = fh[idx]; fp != NULL; fp = fp->f_next) { 61 if (fp->f_id == id) { 62 foo_increase(fp); 63 break; 64 } 65 } 66 pthread_mutex_unlock(&hashlock); 67 return fp; 68 } 69 70 /* decrease a reference to the object */ 71 void foo_decrease(struct foo* fp) 72 { 73 assert(fp != NULL); 74 struct foo* tfp = NULL; 75 int idx = 0; 76 pthread_mutex_lock(&fp->f_lock); 77 if (fp->f_count == 1) { 78 pthread_mutex_unlock(&fp->f_lock); 79 pthread_mutex_lock(&hashlock); 80 pthread_mutex_lock(&fp->f_lock); 81 /* need to recheck the condition */ 82 if (fp->f_count != 1) { 83 fp->f_count--; 84 pthread_mutex_unlock(&fp->f_lock); 85 pthread_mutex_unlock(&hashlock); 86 return; 87 } 88 89 /* remove from list */ 90 idx = HASH(fp); 91 tfp = fh[idx]; 92 if (tfp == fp) { 93 fh[idx] = fp->f_next; 94 } else { 95 while (tfp->f_next != fp) { 96 tfp = tfp->f_next; 97 } 98 tfp->f_next = fp->f_next; 99 } 100 pthread_mutex_unlock(&hashlock); 101 pthread_mutex_unlock(&fp->f_lock); 102 pthread_mutex_destroy(&fp->f_lock); 103 free(fp); 104 105 } else { 106 fp->f_count--; 107 pthread_mutex_unlock(&fp->f_lock); 108 } 109 }
上述代码描述了两个互斥量的使用方法
当同时需要两个互斥量时,总是让它们以相同的顺序加锁,以避免死锁
hashlock维护着一个用于跟踪foo数据结构的散列列表,这样就保护foo结构中的fh散列表和f_next散列链字段
foo结构中的f_lock互斥量保护对foo结构中的其他字段的访问
在foo_decrease函数中,首先需要读取 f_count 这个时候我们必须对其加锁访问,防止其它线程在此过程中修改此变量
互斥读取到f_count变量后,如果它是最后一个引用,则需要从散列表中删除这个结构,这时需要读取全局的数据结构fh结构体数组,我们必须先对 结构体互斥量解锁(第78行),才可以重新获得散列表锁(第79行),然后重新获取结构体互斥量(第80行),因为 两个互斥量的加锁顺序必须保持绝对一致。线程可能为了满足锁顺序而阻塞,其它线程可能就在此阻塞过程中对结构引用计数加1,所以必须重新检查条件。也就是说在第78行至80行之间,其它线程是可以对结构体引用计数加1的。
上述代码过于复杂,可以简化如下:
1 #include <unistd.h> 2 #include <stdio.h> 3 #include <stdlib.h> 4 #include <assert.h> 5 #include <pthread.h> 6 7 #define NHASH 29 8 #define HASH(fp) (((unsigned long)(fp)) % NHASH) 9 10 struct foo { 11 struct foo* f_next; /* protected by hashlock */ 12 int f_count; /* protected by hashlock */ 13 pthread_mutex_t f_lock; 14 int f_id; 15 /* more stuff here */ 16 }; 17 18 struct foo* fh[NHASH]; 19 pthread_mutex_t hashlock = PTHREAD_MUTEX_INITIALIZER; 20 21 struct foo* foo_alloc(void) 22 { 23 int idx = 0; 24 struct foo* fp = malloc(sizeof(struct foo)); 25 if (fp != NULL) { 26 fp->f_count = 1; 27 int ret = pthread_mutex_init(&fp->f_lock, NULL); 28 if (ret != 0) { 29 free(fp); 30 return NULL; 31 } 32 idx = HASH(fp); 33 pthread_mutex_lock(&hashlock); 34 fp->f_next = fh[idx]; 35 fh[idx] = fp->f_next; 36 pthread_mutex_lock(&fp->f_count); 37 pthread_mutex_unlock(&hashlock); 38 /* continue initialization */ 39 } 40 return fp; 41 } 42 43 void foo_increase(struct foo* fp) 44 { 45 assert(fp != NULL); 46 pthread_mutex_lock(&hashlock); 47 fp->f_count++; 48 pthread_mutex_unlock(&hashlock); 49 } 50 51 struct foo* foo_find(int id) 52 { 53 struct foo* fp = NULL; 54 int idx = HASH(fp); 55 pthread_mutex_lock(&hashlock); 56 for (fp = fh[idx]; fp != NULL; fp = fp->f_next) { 57 if (fp->f_id == id) { 58 fp->f_count++; 59 break; 60 } 61 } 62 pthread_mutex_unlock(&hashlock); 63 return fp; 64 } 65 66 void foo_decrease(struct foo* fp) 67 { 68 assert(fp != NULL); 69 struct foo* tfp = NULL; 70 int idx = 0; 71 72 pthread_mutex_lock(&hashlock); 73 if (--fp->f_count == 0) { 74 idx = HASH(fp); 75 tfp = fh[idx]; 76 if (tfp == fp) { 77 fh[idx] = fp->f_next; 78 } else { 79 while (tfp->f_next != fp) { 80 tfp = tfp->f_next; 81 } 82 tfp->f_next = fp->f_next; 83 } 84 pthread_mutex_unlock(&hashlock); 85 pthread_mutex_destroy(&fp->f_lock); 86 free(fp); 87 } else { 88 pthread_mutex_unlock(&hashlock); 89 } 90 }
如果锁的粒度太粗,就会出现很多线程阻塞等待相同的锁,源自并发性的改善微乎其微
如果锁的粒度太细,那么过多的锁会使系统性能开销受到影响,而且代码变得相当复杂
5.读写锁
互斥量要么是锁住状态,要么是不加锁状态,而且一次只有一个线程可以对其加锁
读写锁有三种状态:读状态加锁,写状态加锁,不加锁。一次只有一个线程可以占有 写状态锁,多个线程可以同时占有多个读状态锁
读写锁非常适合于对数据结构读的次数远大于写的情况
读写锁也叫做 共享-独占锁
6.条件变量
7. 线程属性
#include<pthread.h> int pthread_attr_init(pthread_attr_t* attr); int pthread_attr_destroy(pthread_attr_t* attr);

如果对现有的某个线程的终止状态不感兴趣的话,可以使用pthread_detach函数让操作系统在线程退出时回收它所占用的资源
pthread_attr_getstack pthread_attr_setstack 这两个函数可以用于管理stackaddr线程属性
pthread_attr_getstacksize pthread_attr_setstacksize 这两个函数可以用于管理stacksize线程属性
8.互斥量属性
#include <pthread.h> int pthread_mutexattr_init(pthread_mutexattr_t* attr); int pthread_mutexattr_destroy(pthread_mutexattr_t* attr);
9.重入、线程安全
如果一个函数在同一时刻可以被多个线程安全地调用,则该函数是线程安全的。