单向LSTM笔记, LSTM做minist数据集分类
先介绍下torch.nn.LSTM()这个API
1.input_size: 每一个时步(time_step)输入到lstm单元的维度.(实际输入的数据size为[batch_size, input_size])
2. hidden_size: 确定了隐含状态hidden_state的维度. 可以简单的看成: 构造了一个权重, 隐含状态
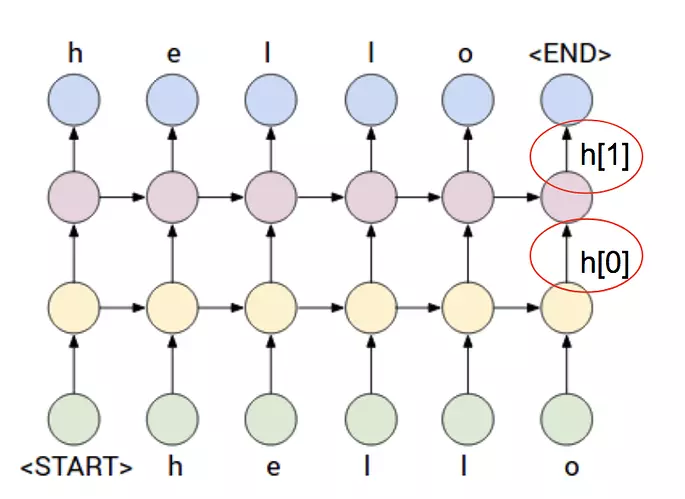
3 . num_layers: 叠加的层数。如图所示num_layers为 3
4. batch_first: 输入数据的size为[batch_size, time_step, input_size]还是[time_step, batch_size, input_size]
使用单向LSTM对MNIST进行分类,我是在pytorch0.4.1坂本上运行的。
1 ########################## pytorch 用LSTM做minist数据分类 ################## 2 ########################################################################## 3 import torch 4 import torch.utils.data as Data 5 import torchvision 6 import matplotlib.pyplot as plt 7 import numpy as np 8 9 BATCH_SIZE = 50 10 11 12 class RNN(torch.nn.Module): 13 def __init__(self): 14 super().__init__() 15 self.rnn = torch.nn.LSTM( 16 input_size=28, 17 hidden_size=64, 18 num_layers=1, 19 batch_first=True 20 ) 21 self.out = torch.nn.Linear(in_features=64, out_features=10) 22 23 def forward(self, x): 24 # 一下关于shape的注释只针对单向 25 # output: [batch_size, time_step, hidden_size] 26 # h_n: [num_layers,batch_size, hidden_size] # 虽然LSTM的batch_first为True,但是h_n/c_n的第一维还是num_layers 27 # c_n: 同h_n 28 output, (h_n, c_n) = self.rnn(x) 29 #print(output.size()) 30 # output_in_last_timestep=output[:,-1,:] # 也是可以的 31 output_in_last_timestep = h_n[-1, :, :] 32 # print(output_in_last_timestep.equal(output[:,-1,:])) # ture 33 x = self.out(output_in_last_timestep) 34 return x 35 36 37 if __name__ == "__main__": 38 # 1. 加载数据 39 training_dataset = torchvision.datasets.MNIST("./mnist", train=True, 40 transform=torchvision.transforms.ToTensor(), download=True) 41 dataloader = Data.DataLoader(dataset=training_dataset, 42 batch_size=BATCH_SIZE, shuffle=True, num_workers=2) 43 # showSample(dataloader) 44 test_data = torchvision.datasets.MNIST(root="./mnist", train=False, 45 transform=torchvision.transforms.ToTensor(), download=False) 46 test_dataloader = Data.DataLoader( 47 dataset=test_data, batch_size=1000, shuffle=False, num_workers=2) 48 testdata_iter = iter(test_dataloader) 49 test_x, test_y = testdata_iter.next() 50 test_x = test_x.view(-1, 28, 28) 51 # 2. 网络搭建 52 net = RNN() 53 # 3. 训练 54 # 3. 网络的训练(和之前CNN训练的代码基本一样) 55 optimizer = torch.optim.Adam(net.parameters(), lr=0.001) 56 loss_F = torch.nn.CrossEntropyLoss() 57 for epoch in range(3): # 数据集只迭代一次 58 for step, input_data in enumerate(dataloader): 59 x, y = input_data 60 pred = net(x.view(-1, 28, 28)) 61 loss = loss_F(pred,y) # 计算loss 62 optimizer.zero_grad() 63 loss.backward() 64 optimizer.step() 65 if step % 50 == 49: # 每50步,计算精度 66 with torch.no_grad(): 67 test_pred = net(test_x) 68 prob = torch.nn.functional.softmax(test_pred, dim=1) 69 pred_cls = torch.argmax(prob, dim=1) 70 acc = (pred_cls == test_y).sum().numpy() / pred_cls.size()[0] 71 print(f"{epoch}-{step}: accuracy:{acc}")
由上面代码可以看到输出为:output,(h_n,c_n)=self.rnn(x),解释下代码中的第28行。
-
output: 如果num_layer为3,则output只记录最后一层 --------- 第三层的输出。
- 对应图中向上的h_t
- 其size根据
batch_first而不同。可能是[batch_size, time_step, hidden_size]或[time_step, batch_size, hidden_size]
-
h_n: 各个层的最后一个时步的隐含状态
h.- size为
[num_layers,batch_size, hidden_size] - 对应图中向右的h_t. 可以看出对于单层单向的LSTM, 其
h_n最后一层输出h_n[-1,:,:],和output最后一个时步的输出output[:,-1,:]相等。在示例代码中print(h_n[-1,:,:].equal(output[:,-1,:]))会打印True
- size为
-
c_n: 各个层的最后一个时步的隐含状态
C- c_n可以看成另一个隐含状态,size和
h_n相同
- c_n可以看成另一个隐含状态,size和
我运行了3个epoch效果如下:
0-49: accuracy:0.3 0-99: accuracy:0.596 0-149: accuracy:0.697 0-199: accuracy:0.734 0-249: accuracy:0.769 0-299: accuracy:0.782 0-349: accuracy:0.751 0-399: accuracy:0.843 0-449: accuracy:0.859 0-499: accuracy:0.87 0-549: accuracy:0.857 0-599: accuracy:0.89 0-649: accuracy:0.88 0-699: accuracy:0.883 0-749: accuracy:0.905 0-799: accuracy:0.905 0-849: accuracy:0.902 0-899: accuracy:0.901 0-949: accuracy:0.908 0-999: accuracy:0.921 0-1049: accuracy:0.917 0-1099: accuracy:0.906 0-1149: accuracy:0.941 0-1199: accuracy:0.935 1-49: accuracy:0.935 1-99: accuracy:0.936 1-149: accuracy:0.941 1-199: accuracy:0.923 1-249: accuracy:0.94 1-299: accuracy:0.936 1-349: accuracy:0.941 1-399: accuracy:0.948 1-449: accuracy:0.937 1-499: accuracy:0.939 1-549: accuracy:0.949 1-599: accuracy:0.949 1-649: accuracy:0.953 1-699: accuracy:0.947 1-749: accuracy:0.918 1-799: accuracy:0.944 1-849: accuracy:0.957 1-899: accuracy:0.959 1-949: accuracy:0.947 1-999: accuracy:0.944 1-1049: accuracy:0.961 1-1099: accuracy:0.964 1-1149: accuracy:0.961 1-1199: accuracy:0.952 2-49: accuracy:0.95 2-99: accuracy:0.952 2-149: accuracy:0.957 2-199: accuracy:0.945 2-249: accuracy:0.957 2-299: accuracy:0.953 2-349: accuracy:0.956 2-399: accuracy:0.942 2-449: accuracy:0.946 2-499: accuracy:0.962 2-549: accuracy:0.956 2-599: accuracy:0.957 2-649: accuracy:0.953 2-699: accuracy:0.958 2-749: accuracy:0.963 2-799: accuracy:0.959 2-849: accuracy:0.954 2-899: accuracy:0.961 2-949: accuracy:0.959 2-999: accuracy:0.961 2-1049: accuracy:0.962 2-1099: accuracy:0.958 2-1149: accuracy:0.955 2-1199: accuracy:0.964
主要参考:https://www.jianshu.com/p/043083d114d4