
1. 原始信号f是什么?我采集的是原始信号f还是y = Af得到的y?
记原始信号为f,我们在sensor方得到的原始信号就是n*1的信号f,而在receiver方采集到的信号是y。针对y=Af做变换时,A(m*n )是一个随机矩阵(真的很随机,不用任何正交啊什么的限定)。通过由随机矩阵变换内积得到y,我们的目标是从y中恢复f。由于A是m*n(m<n)的,所以原信号f(n*1)信号被压缩到y(m*1)。
2. 有的地方写 y =Ax, 有的地方写 y=Dx,这里A和D只是符号的区别吗?压缩感知问题中的字典是什么?
不是只有符号区别!详见开始我写的参考文献中公式(4)(5),f可以通过矩阵分解(SVD/QR)得到正交矩阵的线性组合,即:f = ψx
这里ψ是n*n的正交矩阵,x是与ψ内积能够得到f的n*1向量,相当于系数。这里终于出现了稀疏的定义!!!假定x是稀疏的(注意是x而非f)!
为什么要把f分解呢?因为A是非常随机的随机矩阵啊!竟然随机!?这样如果A非常稀疏,那么y还能恢复的出来?
对!所以我们要将f分解为正交阵和向量的线性组合。
好,带入y=Af,得y = Aψx
因为A是随机矩阵,ψ是n*n的正交矩阵,所以A乘以ψ相当于给A做了一个旋转变换,其结果Aψ还是一个随机矩阵。这里的Aψ才是D,也就是字典!于是乎,形成了y = Dx,D = Aψ
其中x假设是稀疏的,但并非最初的采样值,D是恢复(重建)矩阵。
这就是D与A的区别。
3. 为什么在MP和OMP算法中,要用一个随机矩阵乘以一个正交傅里叶矩阵?
在“压缩感知” 之 “Hello World”这篇文章中,我们采用OMP算法求取稀疏矩阵x,用了一个随机矩阵A和傅里叶正变换矩阵ψ相乘得到字典D,但事实上这只是一个例子而已,我们还可以有很多其他选择,包括随机矩阵的选取和什么样的正交阵,都可以有变化。
上面我们假定了y=Dx中x是稀疏的,就可以应用压缩感知的理论,通过Matching pursuit或者basis pursuit进行x重建了。
重建之后呢,由于x并非原始信号f,只需将ψ与恢复出的信号x进行内积,就可以恢复出原始信号f。
4.有几种常用的测量方式?
三种:
A. 产生一个随机矩阵(Gaussian /Bernoulli Distribution),与原始信号f相乘
B. 在fourier变换域采样
C. 线积分(即拉当变换(Radon)),广泛用于断层扫描。在不同方向对信号(想成图像好了)做积分,形成的不同曲线即为不同测量。
5. 有误差或者噪声的时候Compressive Sensing还管用吗?
在实际情况中呢,我们获得的数据含有噪声。相应的,用含有噪声的模型:

所以说,y是干净样本和噪声样本的叠加。
这里噪声e可以假定具有高斯分布或者什么分布具体情况具体分析。
实际样本的目标函数有以下两种:

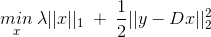
这两种目标函数的本质是一样的,
- 对于第一种,约束项就是误差。当误差小于一个threshold(δ)时,即AE这个噪声符合理论前提条件时,进行optimize
- 对于第二种,就直接把误差项写入目标函数(loss function)
6. 压缩感知问题怎样确定稀疏度?
稀疏度是CS中一个很头痛的问题,这里仅给出基本思路,因为我也没有具体实践过。
Method:
% 1-D信号压缩传感的实现(正交匹配追踪法Orthogonal Matching Pursuit)
% 测量数M>=K*log(N/K),K是稀疏度,N信号长度,可以近乎完全重构
% 编程人--香港大学电子工程系 沙威 Email: wsha@eee.hku.hk
% 编程时间:2008年11月18日
% 文档下载: http://www.eee.hku.hk/~wsha/Freecode/freecode.htm
% 参考文献:Joel A. Tropp and Anna C. Gilbert
% Signal Recovery From Random Measurements Via Orthogonal Matching
% Pursuit,IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 53, NO. 12,
% DECEMBER 2007.
clc;clear
%% 1. 时域测试信号生成
K=7; % 稀疏度(做FFT可以看出来)
N=256; % 信号长度
M=64; % 测量数(M>=K*log(N/K),至少40,但有出错的概率)
f1=50; % 信号频率1
f2=100; % 信号频率2
f3=200; % 信号频率3
f4=400; % 信号频率4
fs=800; % 采样频率
ts=1/fs; % 采样间隔
Ts=1:N; % 采样序列
x=0.3*cos(2*pi*f1*Ts*ts)+0.6*cos(2*pi*f2*Ts*ts)+0.1*cos(2*pi*f3*Ts*ts)+0.9*cos(2*pi*f4*Ts*ts); % 完整信号,由4个信号叠加而来
%% 2. 时域信号压缩传感
Phi=randn(M,N); % 测量矩阵(高斯分布白噪声)64*256的扁矩阵,Phi也就是文中说的D矩阵
s=Phi*x.'; % 获得线性测量 ,s相当于文中的y矩阵
%% 3. 正交匹配追踪法重构信号(本质上是L_1范数最优化问题)
%匹配追踪:找到一个其标记看上去与收集到的数据相关的小波;在数据中去除这个标记的所有印迹;不断重复直到我们能用小波标记“解释”收集到的所有数据。
m=2*K; % 算法迭代次数(m>=K),设x是K-sparse的
Psi=fft(eye(N,N))/sqrt(N); % 傅里叶正变换矩阵
T=Phi*Psi'; % 恢复矩阵(测量矩阵*正交反变换矩阵)
hat_y=zeros(1,N); % 待重构的谱域(变换域)向量
Aug_t=[]; % 增量矩阵(初始值为空矩阵)
r_n=s; % 残差值
for times=1:m; % 迭代次数(有噪声的情况下,该迭代次数为K)
for col=1:N; % 恢复矩阵的所有列向量
product(col)=abs(T(:,col)'*r_n); % 恢复矩阵的列向量和残差的投影系数(内积值)
end
[val,pos]=max(product); % 最大投影系数对应的位置,即找到一个其标记看上去与收集到的数据相关的小波
Aug_t=[Aug_t,T(:,pos)]; % 矩阵扩充
T(:,pos)=zeros(M,1); % 选中的列置零(实质上应该去掉,为了简单我把它置零),在数据中去除这个标记的所有印迹
aug_y=(Aug_t'*Aug_t)^(-1)*Aug_t'*s; % 最小二乘,使残差最小
r_n=s-Aug_t*aug_y; % 残差
pos_array(times)=pos; % 纪录最大投影系数的位置
end
hat_y(pos_array)=aug_y; % 重构的谱域向量
hat_x=real(Psi'*hat_y.'); % 做逆傅里叶变换重构得到时域信号
%% 4. 恢复信号和原始信号对比
figure(1);
hold on;
plot(hat_x,'k.-') % 重建信号
plot(x,'r') % 原始信号
legend('Recovery','Original')
norm(hat_x.'-x)/norm(x) % 重构误差



好了,有了OMP算法,开始对应解释代码:
for col=1:N; % 恢复矩阵的所有列向量
product(col)=abs(T(:,col)'*r_n); % 恢复矩阵的列向量和残差的投影系数(内积值)
end
这个循环是让矩阵T的每一列与残差求内各,T一共有N列,这里得到N个内积值存在product里面。内积值最大的即为相关性最强T(:,col)为M*1列向量,r_n初如化为s,是M*1列向量,这里让T(:,col)转置后再与r_n相乘,即一个1*M的行向量与一个M*1的列向量相乘,根据矩阵运算规则结果为一个数(即1*1的矩阵)。
[val,pos]=max(product); 这句话的关键是得到pos,即得到T中的哪一列与残差r_n的内积值最大,也就是哪一列与残差r_n相关性最强。此即英文步骤中的第二步。Aug_t=[Aug_t,T(:,pos)]; 此即英文步骤中的第三步,将刚刚得到的与残差r_n内积值最大的列存到Aug_t中,这个矩阵随着循环次数(迭代次数)的变换而变化,是M*times的矩阵。
T(:,pos)=zeros(M,1); 这一句是为了下一次迭代做准备的,这次找到了与残差最相关的列,将残差更新后,下次再找与残差仅次于这一列的T的另外一列;
aug_y=(Aug_t'*Aug_t)^(-1)*Aug_t'*s; 这一句即英文步骤中的第四步,这句加上后面一句也是困扰了我好久两句代码,所以得说说:
首先我们针对的是s=T*hat_y,现在是已知s要求hat_y,现在假如说矩阵T为N*N方阵且满秩(即N个未知数,N个独立的方程),那么很容易知道hat_y=T^-1 * s,其中T^-1表示矩阵T的逆矩阵。但是现在T是一个M*N的扁矩阵,矩阵T没有常规意义上的逆矩阵,这里就有“广义逆”的概念(详情参见国内矩阵分析教材),hat_y的解可能是不存在的,我们这里要求的是最小二乘解aug_y,最小二乘解aug_y将使s-T*aug_y这个列向量2范数最小。
对于用矩阵形式表达的线性方程组:

它的最小二乘解为:
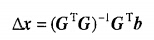
其中
![]() 即为矩阵G的最小二乘广义逆(广义逆的一种)。
即为矩阵G的最小二乘广义逆(广义逆的一种)。
有了这些知识背景后代码就容易理解了,在第三步中,得到矩阵T中的与残差r_n最相关的列组成的矩阵Aug_t,而第四步实际上就是在求方程组Aug_t*Aug_y=s的最小二乘解。
pos_array(times)=pos; 把与T中与残差最相关的列号记下来,恢复时使用。
到此,主要的for循环就说完了。
hat_x=real(Psi'*hat_y.');此即:  这里用hat_x以与原如信号x区分,x为原信号,hat_x为恢复的信号。代码中对hat_y取了转置是因为hat_y应该是个列向量,而在代码中的前面hat_y=zeros(1,N); 将其命成了行向量,所以这里转置了一下,没什么大不了的。
这里用hat_x以与原如信号x区分,x为原信号,hat_x为恢复的信号。代码中对hat_y取了转置是因为hat_y应该是个列向量,而在代码中的前面hat_y=zeros(1,N); 将其命成了行向量,所以这里转置了一下,没什么大不了的。