Cortex-A8
关于Cortex-A8的微处理架构参考《ARM_Cortex-A8微处理器的架构和实现》
其中关于NEON有两段话摘录如下:
NEON媒体引擎拥有自己的10段流水线,它从ARM整数流水线结束处开始。由于ARM整数单元中已解决所有错误预测和异常,所以向NEON媒体引擎发送指令后,因为它不会产生异常,所以必须完成。NEON有三条SIMD整数流水线,一条加载存储/交换流水线,两条SIMD单精度浮点流水线和一个非流水线向量浮点单元(VFPLite)。
按顺序发射和收回NEON指令。数据处理指令是NEON整数指令或NEON浮点指令。Cortex-A8 NEON单元不会并行发射两条数据处理指令,这样可避免复制数据处理函数块占用太多空间,同时可避免与读写寄存器端口复用相关的计时关键路径和复杂性。
几个ARM处理器内核:
《ARM内核全解析,从ARM7,ARM9到Cortex-A7,A8,A9,A12,A15到Cortex-A53,A57》
Cortex-A76
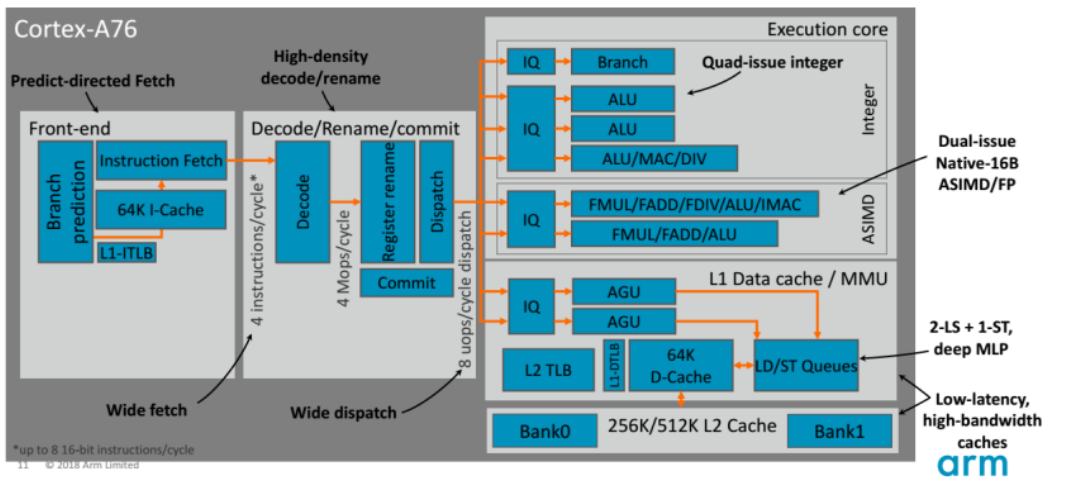
针对前端和fetch单元,为了提高带宽降低时延,把Fetch中的预测功能单独分立,所以在实际接受指令之前就进行Branch prediction,之后在Instruction Fetch上实现了每个周期4个指令。
图中uops表示微指令,mops(Million operation per second)每秒百万次计算,用来衡量CPU的运算速度。