JVM 启动流程
当jvm启动时,是用java命令或者是javaw命令启动的。我们启动jvm时步骤如下:
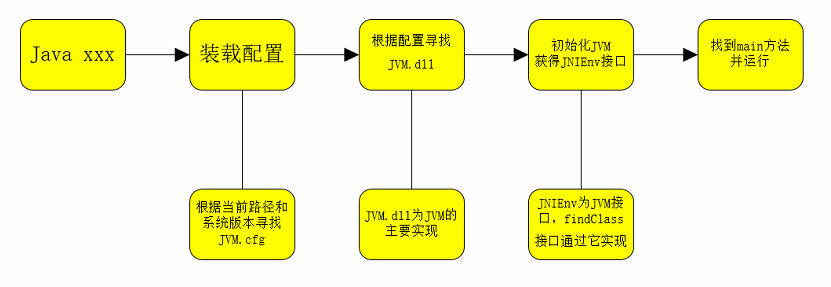
- 使用java命令后面接启动类,类中必须要有main方法。
- 装载配置,根据当前路径和系统版本寻找jvm的配置文件jvm.cfg文件。
- 找到配置文件后回去定位所需要的dll,而JVM.dll就是JVM的主要实现。
- 找到当前版本匹配的dll之后就会去初始化虚拟机。获取相关的接口,比如JNIEnv,这个接口提供了大量的与jvm交互的操作
- 找到main方法开始运行
JVM 基本结构
在了解JVM基本结构前,我们有必要先来了解一下操作系统的内存结构。操作系统的内存结构是由PC寄存器,栈,堆,和硬盘组成。而JVM 相当于一个微型的操作系统,它的内存结构跟操作系统的内存结构大致相似,是由pc寄存器,堆,栈,方法区组成。下图为操作系统和jvm的组成图。
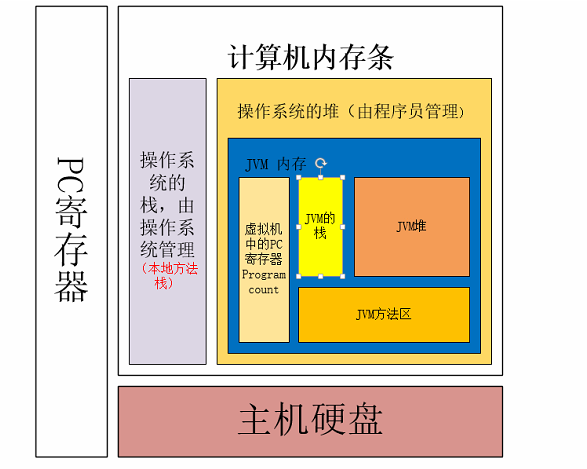
为什么jvm的内存是分布在操作系统的堆中呢??因为操作系统的栈是操作系统管理的,它随时会被回收,所以如果jvm放在栈中,那java的一个null对象就很难确定会被谁回收了,那gc的存在就一点意义都莫有了,而要对栈做到自动释放也是jvm需要考虑的,所以放在堆中就最合适不过了。
上面为操作系统和jvm的内存结构,下面我们来只看JVM的内存结构:
首先,当一个程序启动之前,它的class会被类装载器装入方法区,执行引擎读取方法区的字节码自适应解析,边解析就边运行(其中一种方式),然后pc寄存器指向了main函数所在位置,虚拟机开始为main函数在java栈中预留一个栈帧(每个方法都对应一个栈帧),然后开始跑main函数,main函数里的代码被执行引擎映射成本地操作系统里相应的实现,然后调用本地方法接口,本地方法运行的时候,操纵系统会为本地方法分配本地方法栈,用来储存一些临时变量,然后运行本地方法,调用操作系统API等等。

- PC寄存器
①. 每个线程都拥有一个PC寄存器
②. PC寄存器在线程创建时创建
③. PC寄存器的作用是指向下一条指令的地址
④. 执行本地方法时,PC寄存器的值为undefined - 方法区
①. 通常跟永久区(Perm)关联在一起(保存一些相对静止,相对稳定的数据)
②. 保存装载的类信息(常量池、字段方法信息、方法字节码)
③. 主要由java虚拟机进行维护
注意:在JDK6时,String等常量的信息是存在方法区中的,而在JDK7时将String等常量移动到了堆中 - java 堆
①. 和程序开发密切相关
②. 应用系统对象都保存在java堆中
③. 所有线程共享java堆
④. 堆分代GC来说,堆是分代的
⑤. 是GC的主要工作区间 - java 栈
①. 线程私有的
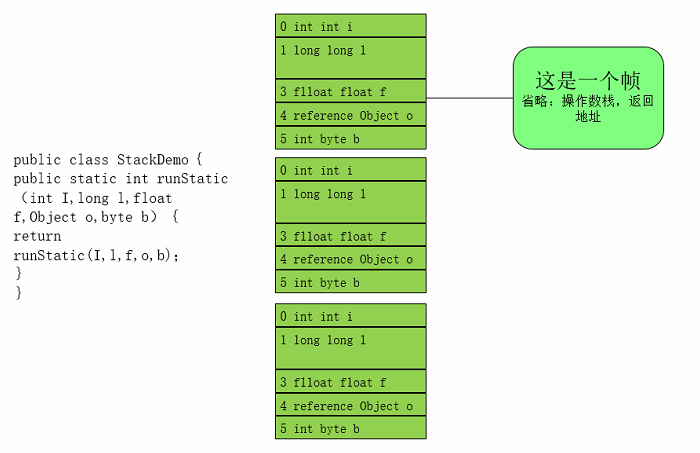
②. 栈由一系列的帧组成(因此java栈也叫做帧栈)
③. 帧保存一个方法的局部变量、操作数栈、常量池指针
④. 每一个方法调用创建一个帧,并压栈
⑤. 局部变量表(包含参数和局部变量),每一个变量都会存在一个巢位,每一个巢位的长度为32位,例如long类型就占两个巢位。实例方法与静态方法有一点区别就是局部变量表的第一个为this它本身

⑥.函数调用,组成帧栈(每次调用方法就会产生一个帧,将帧压入栈中,直到栈溢出为止,而每执行结束一个方法,帧也会被移除)
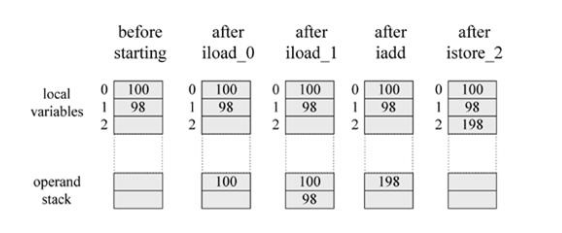
⑦. 操作数栈(java没有寄存器,所有参数传递使用操作数栈)
public static int add(){ int c = 0; c = a + b; return c; } //反编译的代码 0:iconst_0 //将0压栈 1:istore_2 //弹出int,存于局部变量2中 2:iload_0 //将局部变量0压栈 3:iload_1 //将局部变量1压栈 4:iadd //弹出2个变量,求和,并将结果压入栈中 5:istore_2 //弹出结果,放于局部变量中 6:iload_2 //将局部变量2压栈 7:ireturn //返回
⑧. 栈上分配(一般是小对象,十几个bytes左右,在没有逃逸(除了在这个方法中使用,在其他地方也有使用)的的情况下,可以直接在栈上分配,直接分配在栈上可以自动回收,可以减轻GC的压力,但是大对象或者逃逸对象是无法在栈上分配的)
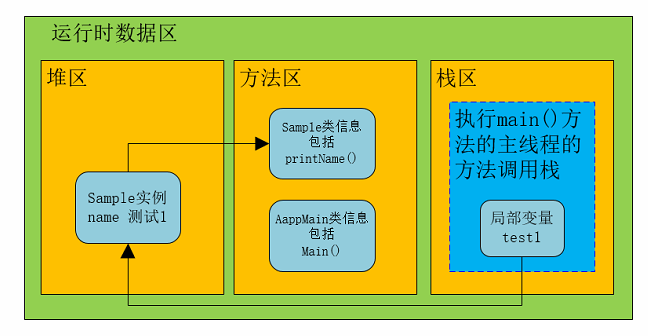
- 栈、堆、方法区之间的交互
//运行时,jvm将AppMain的信息放入方法区 public class AppMain{ public static void main(String[] agrs){ //test1,test2是引用,所以放在堆中,Sample是自定义对象,实例应放在堆中 Sample test1 = new Sample("测试1"); Sample test2 = new Sample("测试2"); test1.printName(); test1.printName(); } } //运行时,jvm将Sample的信息放入方法区 public class Sample{ //创建实例后name的引用放入栈中,name的对象放入堆中 private name; public Sample(String name){ this.name = name; } //方法本身放入方法区中 public void printName(){ System.out.println(name); } }
JVM 内存模型
在开始学习内存模型之前,我们来看这样一个问题:为了能让递归函数调用的次数更多一些,应该怎么做?
每一个线程有一个工作内存和主存独立,而工作内存存放贮存中的变量的值的拷贝。当数据从主内存复制到工作存储时,就必须出现两个动作,首先由主内存执行读操作(read),然后工作内存执行load操作。当数据从工作内存拷贝到主内存时,也需要两个动作,首先工作内存执行存储操作(store),主内存执行write操作。而且其中个的每一个操作都是原子的,执行过程中不会被中断,但是在操作与操作之间是可以被中断的。
对于普通变量,一个线程中更新的值不一定会马上反应到其他的变量中,如果需要线程之间可见,就需要使用volatile关键字。
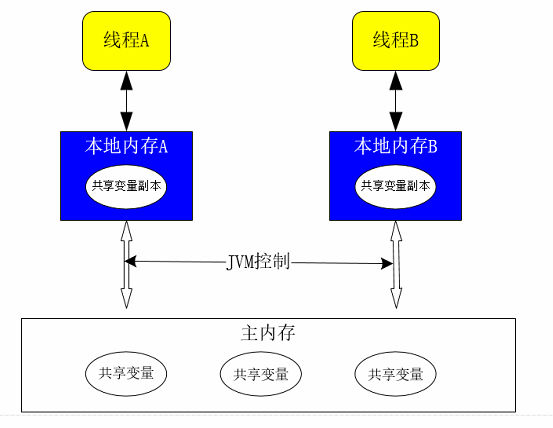
当2个线程在共同执行时,线程A的变量是保存在线程A工作内存中的,而线程B的变量是保存在线程B的工作内存中的,当两个线程共同使用了主线程中的变量时,他们都会将共用的变量复制到自己的工作内存中去,当A线程在执行时变量发生变化时不会立刻去更新主内存中的变量的值,那么,此时B线程就没有获取到更新之后的变量。如果要使B线程获取最新的变量的值,就需要使用volatile关键字修饰这个变量,那么,每次变量发生变化时都会将值更新到主内存中,并且线程在读取变量的值时是需要去主内存中读取的。
volatile不能代替锁,因为volatile不是线程安全的。一般认为volatile比锁的性能好(不绝对)。
我们看下面例子:
public class VolatileStopThread extends Thread{ private volatile boolean stop = false; public void stopMe() { stop = true; } public void run() { int i = 0; while (stop) { i++; } System.out.println("stop thread"); } public static void main(String[] args) throws InterruptedException { VolatileStopThread t = new VolatileStopThread(); t.start(); Thread.sleep(1000); t.stopMe(); Thread.sleep(1000); } }
如果stop变量不使用volatile关键字修饰,并且使用-server方式去运行,则程序永远无法停止。
- 可见性
当一个线程修改了某个共享变量时,其他线程立刻知道。 - 保证可见性的方法
①. volatile关键字
②. synchronized(unlock之间将变量的值写入主内存)
③. final(一旦初始化,其他线程就可以立刻知道) - 有序性
①. 在本线程中,操作都是有序的。
②. 在线程外观察,操作都是无序的。(有可能是指令重排序,也有可能时线程工作内存和主内存之间存在延时,导致其他线程看到的时候指令是无序的) - 指令重排序
①. 线程内串行语义
写后读 a=1;b=a;写一个变量后,再读这个位置。
写后写 a=1;a=2 写一个变量之后,再写这个变量。
读后写 a=b;b=1 读一个变量之后再写这个变量。
以上的几个语句类型是不可以重排序的。
编译器只会考虑在同一个线程中的方法重排序后结果与串行执行的结果一致,的才会去重排序。不会去考虑多线程之间的语义。
我们看下面例子:
class OrderExample{ int a = 0; boolean flag = false; private void writer() { a = 1; flag = true; } private void reader() { if (flag) { int i = a + 1; } } }
在上面这个例子中,如果让A线程调用writer()方法,B线程调用reader()方法,因为A线程中a=1和flag=true是有可能发生指令重排序的,那么就有可能B线程执行时发现flag的值为true而此时a的值还为0,如何解决这一问题呢?就需要使用到synchronized去给两个方法加锁,使得两个线程调用两个方法时是串行的。
- 指令重排序基本原则
①. 程序顺序原则:一个线程内保证语义串行性
②. volatile规则:volatile变量的写,先发生于读
③. 锁规则:解锁(unlock)必然发生在随后的加锁(lock)前
④. 传递性:A先于B,B先于C,那么必然A先于C
⑤. 线程的start方法先于它的每一个动作
⑥. 线程的所有操作先于线程的终结(Thread.join())
⑦. 线程的中断(interrupt())先于被中断线程的代码
⑧. 对象的构造函数执行结束先于finalize()方法
编译和解释运行
- 解释运行
解释执行以解释方式运行字节码,解释执行的意思就是,读一句执行一句。 - 编译运行(JIT)
①. 将字节码编译成机器码
②. 直接诶执行机器码
③. 运行时编译
④. 编译后性能有数量级的提升
-------------------- END ---------------------
最后附上作者的微信公众号地址和博客地址
公众号:wuyouxin_gzh

Herrt灬凌夜:https://www.cnblogs.com/wuyx/
版权说明:欢迎以任何方式进行转载,但请在转载后注明出处!