字典
字典由花括号表示{ },元素是key:value的键值对,元素之间用逗号隔开
特点:1、字典中key是不能重复的 且是不可变的数据类型,因为字典是使用hash算法来计算key的哈希值,然后用哈希值来存储键值对数据
2、字典中元素是无序的
3、value值可以是任意类型的数据
注:字典中的key是可hash的,可hash的数据的都是不可变的数据类型
已知的可哈希(不可变)的数据类型: int, str, tuple(元组), bool
不可哈希(可变)的数据类型: list(列表), dict(字典), set(集合)
增删改查
创建一个空字典---两种方式:
dic ={}
dic = dict()
新增(两种方式)
dic[key] = value # 可以新增也可修改已有key的value值
dic.setdefault(key, value) # 如果key是没有的,新增;如果key已存在 保持原值(这个方法是分两步的 在查询会细说)
删除(四种方式)
pop(key) # 必须指定一个key 删除指定元素
popitems( ) # 随机删除一个值(字典是无序的) 但是在3.6版本里效果是删除字典最后一个元素--->原因 3.5之前字典打印输出是无序的,但在3.6之后字典打印输出是按照元素添 加的顺序的,所以感觉用这个方法时是删除的最后一个元素,但是这个方法的源码里还是随机删除的
del dic[key] # 删除指定元素
dic.clear() # 清空字典
修改(两种)
dic[key] = new value #赋一个新值
dic.update(dic2) #将dic2更新到dic中
查询(三种)
dic[key] #查询指定元素 key不存在时报错
dic.get(key,[xxx]) # 查询key的value key不存在时返回xxx,如果不写xxx,默认返回None
dic.setdefault(key,[value]) # 执行逻辑 第一步,看key是否存在,key存在, 不添加也不修改value;不存在,添加key:value键值对,value没有时默认为None
第二步,返回key对应的value值
常用操作
dic.keys() 返回所有的键 返回的是一个可迭代对象,形式像列表但又不是列表
1 dic = {"意大利":"西西里的美丽传说", "意大利2":"天堂电影院", "美国":'美国往事', "美国电视剧":"越狱"}
2
3 print(dic.keys()) #dict_keys(['意大利', '意大利2', '美国', '美国电视剧'])
4
5 for k in dic.keys(): # 可以迭代。 拿到的是每一个key
6 print(k)
dic.values() 返回所有的值
dic = {"意大利":"西西里的美丽传说", "意大利2":"天堂电影院", "美国":'美国往事', "美国电视剧":"越狱"}
print(dic.values()) #dict_values(['西西里的美丽传说', '天堂电影院', '美国往事', '越狱'])
for value in dic.values():
print(value)
dic.items() 返回所有的键值对

1 dic = {"意大利":"西西里的美丽传说", "意大利2":"天堂电影院", "美国":'美国往事', "美国电视剧":"越狱"}
2
3 print(dic.items()) #dict_items([('意大利', '西西里的美丽传说'), ('意大利2', '天堂电影院'), ('美国', '美国往事'), ('美国电视剧', '越狱')])
4 for k ,v in dic.items():
5 print(k ,v)
6
7 #遍历字典最好的方案
8 for k, v in dic.items(): # 拿到的是元组(key, value) 这是解包操作
9 print(k,v) #直接拿到key和value
字典嵌套
wf = {
"name":"汪峰",
"age":42,
"hobby":"抢头条",
"代表作":["春天里","怒放的生命","北京 北京"],
"wife_now":{
'name':"章子怡",
"age":62,
"爱好":"打麻将"
},
"children": [{'id':1,"name":"汪涵"},{"id":2,"name":"汪才子"}]
}
print(wf['wife_now']['爱好']) #打麻将
print(wf["wife_now"]["name"]) #章子怡
print(wf["children"][0]["name"]) #汪涵
# 汪峰的小儿子改名成 汪晓峰
wf['children'][1]['name'] = "汪晓峰"
print(wf)
一、小数据池
注意大前提!!!!
小数据池只针对整数、字符串和bool值,因为这些数据是不可变的,这样数据的共享才安全
小数据池也称为小整数缓存机制或驻留机制,是指在不同代码块创建部分小数据对象(具体规则官方文档也没说明,老男孩的老师总结了一些常见规则,看下图,这个了解就行)时,数据缓存共享的现象。
它的作用是在创建这些小数据对象时提升效率,减少内存浪费
小数据驻留规则:

二、再谈编码
ascii: 数字,字母, 特殊字符。 8bit,1 byte
gbk: 国标码。16bit, 2byte
unicode: 万国码。32bit, 4byte
utf-8:可变长度的unicode
英文: 8bit,1byte
欧洲文字: 16bit,2byte
中文: 24bit, 3byte
在之前Python2中内存使用的是ASCII码,python3中内存使用的是Unicode,但Unicode不利于存储和传输,所以在存储和传输时要转换成其他的编码方式。
因为不同编码字符集是不同的,所以不同的编码之间是不能直接转换的,要通过中间量,这个中间量就是unicode
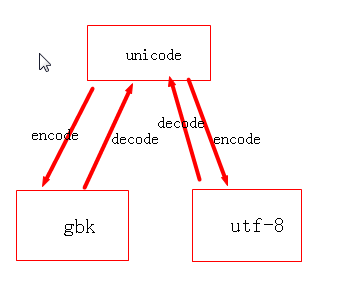
比如 str是用gbk编码的字符串,如果想转成utf-8 需要先解码成unicode再编码成utf-8
s = str.decode(gbk)
str2 = s.encode(utf-8)
str2就是utf-8格式的了
注意:编码和解码之后数据是bytes类型的,形式是 b'xxx' , bytes是python中的最小数据单元。数据传输和存储时都是bytes类型
字符串如果传输:
1、传输端 编码encode(编码形式) ,结果是bytes类型
2、接收端 接受到bytes之后,需要解码decode(编码形式) !!!传输端和接受端用的编码形式要一致