Lucene 是 apache 旗下的一个顶级项目,是一个开源的全文检索引擎工具包;本文主要介绍 Lucene 基本概念及基本使用,文中使用到的软件版本:Lucene 8.9.0、jdk1.8.0_181。
1、简介
1.1、全文检索
全文检索是一种将文件中所有文本与检索项匹配的检索方法,它可以根据需要获得全文中有关章、节、段、句、词等信息。计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时根据建立的索引查找,类似于通过字典的部首字表查字的过程。
经过几年的发展,全文检索从最初的字符串匹配程序已经演进到能对超大文本、语音、图像、活动影像等非结构化数据进行综合管理的大型软件。
主要应用领域:搜索引擎(百度,搜狗)、站内搜索(微博搜索)、电商网站(京东,淘宝)。
1.2、普通数据库搜索的缺陷
数据库使用 like 关键字来搜索,有如下缺陷:
1、没有通过高效的索引方式,所以查询的速度在大量数据的情况下是很慢。
2、搜索效果比较差,只能对用户输入的完整关键字首尾位进行模糊匹配;用户搜索的结果误多输入一个字符,可能就导致查询出的结果远离用户的预期。
1.2、Lucene
1.2.1、Lucene 是什么
Lucene 是 Apache 旗下的一个开源的全文检索引擎工具包,它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene提供了一个简单却强大的应用程序接口,能够做全文索引和搜寻。
1.2.2、Lucene 与搜索引擎的区别
全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。全文检索系统是一个可以运行的系统,包括建立索引、处理查询返回结果集、增加索引、优化索引结构等功能。例如:百度搜索、淘宝网商品搜索。
搜索引擎是全文检索技术最主要的一个应用,例如:百度。搜索引擎起源于传统的信息全文检索理论,即计算机程序通过扫描每一篇文章中的每一个词,建立以词为单位的倒排文件,检索程序根据检索词在每一篇文章中出现的频率,对包含这些检索词的文章进行排序,最后输出排序的结果。全文检索技术是搜索引擎的核心支撑技术。
Lucene 和搜索引擎不同,Lucene 是一套用 Java 写的全文检索的工具包,为应用程序提供了很多个 API 接口,可以简单理解为是一套实现全文检索的类库,搜索引擎是一个全文检索系统,它是一个能够单独运行的软件。
2、使用
2.1、引入依赖
<dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>8.9.0</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>8.9.0</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-highlighter</artifactId> <version>8.9.0</version> </dependency> <dependency> <groupId>com.jianggujin</groupId> <artifactId>IKAnalyzer-lucene</artifactId> <version>8.0.0</version> </dependency>
2.2、创建索引
2.2.1、创建索引过程
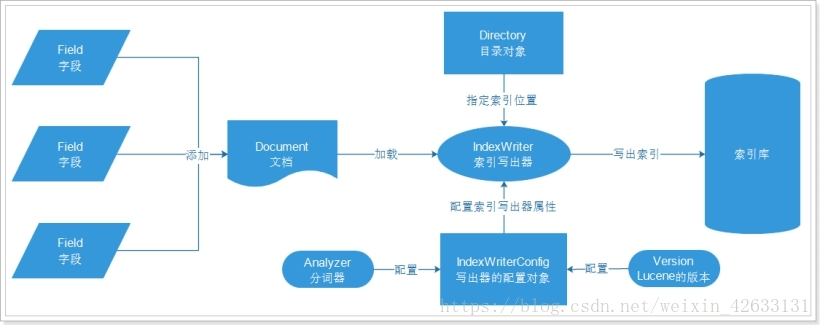
文档(Document):可理解为数据库表中一条记录
字段(Field):可理解为数据库表中的一个字段
目录对象(Directory):物理存储位置
写出器的配置对象:需要分词器
2.2.2、代码实现
/** * 创建索引 * @throws Exception */ @Test public void createIndex() throws Exception { Document document = new Document(); document.add(new LongPoint("id", 123456)); //存储用 document.add(new StoredField("id", 123456)); //排序用 document.add(new NumericDocValuesField("id", 123456)); document.add(new IntPoint("age", 20)); document.add(new StringField("name", "李白", Field.Store.YES)); document.add(new TextField("poems", "静夜思", Field.Store.YES)); document.add(new TextField("about", "字太白", Field.Store.NO)); document.add(new TextField("success", "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度", Field.Store.YES)); Document document2 = new Document(); document2.add(new LongPoint("id", 123457)); //存储用 document2.add(new StoredField("id", 123457)); //排序用 document2.add(new NumericDocValuesField("id", 123457)); document2.add(new IntPoint("age", 21)); document2.add(new StringField("name", "杜甫", Field.Store.YES)); document2.add(new TextField("poems", "登高", Field.Store.YES)); document2.add(new TextField("about", "字子美", Field.Store.NO)); document2.add(new TextField("success", "唐代伟大的现实主义文学作家,唐诗思想艺术的集大成者", Field.Store.YES)); Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); Analyzer analyzer = new IKAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter indexWriter = new IndexWriter(directory, config); //添加文档 indexWriter.addDocument(document); indexWriter.addDocument(document2); indexWriter.commit(); indexWriter.close(); }
2.3、查询索引
2.3.1、通用查询方法
通过 Query 对象来查询索引:
private void query(Query query) throws IOException { Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher = new IndexSearcher(indexReader); //查询前10条数据 TopDocs topDocs = indexSearcher.search(query, 10); logger.info("本次搜索共找到" + topDocs.totalHits.value + "条数据"); ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { Document document = indexReader.document(scoreDoc.doc); //logger.info(document.toString()); logger.info("id={},name={},poems={},success={},score={}", document.get("id"), document.get("name"), document.get("poems"), document.get("success"), scoreDoc.score); } }
2.3.2、词条查询
/** * 词条查询 * Term(词条)是搜索的最小单位,不可再分词,值必须是字符串。 */ @Test public void termQuery() throws IOException { Query query = new TermQuery(new Term("name", "李白")); query(query); }
2.3.3、通配符查询
/** * 通配符查询 * ? 代表任意一个字符 * * 代表任意多个字符 * @throws IOException */ @Test public void wildcardQuery() throws IOException { Query query = new WildcardQuery(new Term("name", "李?")); query(query); }
2.3.4、模糊查询
/** * 模糊查询 * 允许用户输错,可以设置错误的最大编辑距离 * @throws IOException */ @Test public void fuzzyQuery() throws IOException { //"李百"->"李白",只需修改一次,故可以搜索到数据;"里百"则搜索不到数据 Query query = new FuzzyQuery(new Term("name", "里百"), 1); query(query); }
2.3.5、数值查询
/** * 数值查询 * @throws IOException */ @Test public void numberQuery() throws IOException { //精确查询 Query query = LongPoint.newExactQuery("id", 123456); query(query); //符围查询 query = LongPoint.newRangeQuery("id", 123L, 12345678L); query(query); }
2.3.6、组合查询
/** * 组合查询 * Occur.MUST:必须满足,相当于and * Occur.SHOULD:应该满足,但是不满足也可以,相当于or * Occur.MUST_NOT:必须不满足,相当于not */ @Test public void booleanQuery() throws IOException { Query query1 = new TermQuery(new Term("name", "李白")); Query query2 = new TermQuery(new Term("name", "杜甫")); BooleanQuery.Builder builder = new BooleanQuery.Builder(); builder.add(query1, BooleanClause.Occur.SHOULD); builder.add(query2, BooleanClause.Occur.SHOULD); BooleanQuery booleanQuery = builder.build(); query(booleanQuery); }
2.3.7、权重查询
/** * 设置查询权重,影响查询结果排序 * @throws IOException */ @Test public void boostQuery() throws IOException { Query query1 = new BoostQuery(new TermQuery(new Term("name", "李白")), 1.5f); Query query2 = new BoostQuery(new TermQuery(new Term("name", "杜甫")), 1.6f); BooleanQuery.Builder builder = new BooleanQuery.Builder(); builder.add(query1, BooleanClause.Occur.SHOULD); builder.add(query2, BooleanClause.Occur.SHOULD); BooleanQuery booleanQuery = builder.build(); query(booleanQuery); }
2.3.8、分词查询
/** * 分词查询 * @throws Exception */ @Test public void queryParserQuery() throws Exception { QueryParser queryParser = new QueryParser("name", new IKAnalyzer()); Query query = queryParser.parse("李白和杜甫"); query(query); //多字段查询 MultiFieldQueryParser multiFieldQueryParser = new MultiFieldQueryParser(new String[]{"name", "about"}, new IKAnalyzer()); query = multiFieldQueryParser.parse("李白和子美"); query(query); }
2.4、删除索引
/** * 删除索引 * 删除匹配的文档,更新或删除文档对应的索引。更新是更新索引与文档的对关系 * @throws IOException */ @Test public void deleteIndex() throws IOException { Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); Analyzer analyzer = new IKAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter indexWriter = new IndexWriter(directory, config); indexWriter.deleteDocuments(new Term("name", "李白")); //indexWriter.deleteAll(); indexWriter.commit(); indexWriter.close(); }
2.5、更新索引
/** * 更新索引,会先删除索引,再添加索引 * 相当于 deleteIndex() 和 createIndex() * @throws IOException */ @Test public void updateIndex() throws IOException { Document document = new Document(); document.add(new LongPoint("id", 123456)); document.add(new StoredField("id", 123456)); document.add(new IntPoint("age", 20)); document.add(new StringField("name", "李白", Field.Store.YES)); document.add(new TextField("poems", "望天门山", Field.Store.YES)); document.add(new TextField("about", "号青莲居士", Field.Store.NO)); Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); Analyzer analyzer = new IKAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter indexWriter = new IndexWriter(directory, config); indexWriter.updateDocument(new Term("name", "李白"), document); indexWriter.commit(); indexWriter.close(); }
2.6、高亮显示
/** * 高亮显示,增加html标签,根据需要针对标签设置自定义的样式 * @throws Exception */ @Test public void highlighter() throws Exception { Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher = new IndexSearcher(indexReader); QueryParser queryParser = new QueryParser("success", new IKAnalyzer()); Query query = queryParser.parse("文学"); TopDocs topDocs = indexSearcher.search(query, 10); logger.info("本次搜索共找到" + topDocs.totalHits.value + "条数据"); Formatter formatter = new SimpleHTMLFormatter("<em>", "</em>"); QueryScorer queryScorer = new QueryScorer(query); Highlighter highlighter = new Highlighter(formatter, queryScorer); ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { Document document = indexReader.document(scoreDoc.doc); String success = document.get("success"); String successHL = highlighter.getBestFragment(new IKAnalyzer(), "success", success); logger.info("id={},name={},poems={},success={},score={}", document.get("id"), document.get("name"), document.get("poems"), successHL, scoreDoc.score); } }
2.7、排序
/** * 排序 * @throws Exception */ @Test public void sort() throws Exception { Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher = new IndexSearcher(indexReader); QueryParser queryParser = new QueryParser("success", new IKAnalyzer()); Query query = queryParser.parse("文学"); Sort sort = new Sort(new SortField("id", SortField.Type.LONG, false)); TopDocs topDocs = indexSearcher.search(query, 10, sort); logger.info("本次搜索共找到" + topDocs.totalHits.value + "条数据"); ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { Document document = indexReader.document(scoreDoc.doc); logger.info("id={},name={},poems={},success={},score={}", document.get("id"), document.get("name"), document.get("poems"), document.get("success"), scoreDoc.score); } }
2.8、完整代码
上面例子的完整代码:


package com.abc.demo.general.lucene; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.document.*; import org.apache.lucene.index.*; import org.apache.lucene.queryparser.classic.MultiFieldQueryParser; import org.apache.lucene.queryparser.classic.QueryParser; import org.apache.lucene.search.*; import org.apache.lucene.search.highlight.Formatter; import org.apache.lucene.search.highlight.Highlighter; import org.apache.lucene.search.highlight.QueryScorer; import org.apache.lucene.search.highlight.SimpleHTMLFormatter; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.junit.Test; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.wltea.analyzer.lucene.IKAnalyzer; import java.io.IOException; import java.nio.file.Paths; /** * Lucene 使用列子 */ public class LuceneCase { private static Logger logger = LoggerFactory.getLogger(LuceneCase.class); /** * 创建索引 * @throws Exception */ @Test public void createIndex() throws Exception { Document document = new Document(); document.add(new LongPoint("id", 123456)); //存储用 document.add(new StoredField("id", 123456)); //排序用 document.add(new NumericDocValuesField("id", 123456)); document.add(new IntPoint("age", 20)); document.add(new StringField("name", "李白", Field.Store.YES)); document.add(new TextField("poems", "静夜思", Field.Store.YES)); document.add(new TextField("about", "字太白", Field.Store.NO)); document.add(new TextField("success", "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度", Field.Store.YES)); Document document2 = new Document(); document2.add(new LongPoint("id", 123457)); //存储用 document2.add(new StoredField("id", 123457)); //排序用 document2.add(new NumericDocValuesField("id", 123457)); document2.add(new IntPoint("age", 21)); document2.add(new StringField("name", "杜甫", Field.Store.YES)); document2.add(new TextField("poems", "登高", Field.Store.YES)); document2.add(new TextField("about", "字子美", Field.Store.NO)); document2.add(new TextField("success", "唐代伟大的现实主义文学作家,唐诗思想艺术的集大成者", Field.Store.YES)); Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); Analyzer analyzer = new IKAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter indexWriter = new IndexWriter(directory, config); //添加文档 indexWriter.addDocument(document); indexWriter.addDocument(document2); indexWriter.commit(); indexWriter.close(); } /** * 词条查询 * Term(词条)是搜索的最小单位,不可再分词,值必须是字符串。 */ @Test public void termQuery() throws IOException { Query query = new TermQuery(new Term("name", "李白")); query(query); } /** * 通配符查询 * ? 代表任意一个字符 * * 代表任意多个字符 * @throws IOException */ @Test public void wildcardQuery() throws IOException { Query query = new WildcardQuery(new Term("name", "李?")); query(query); } /** * 模糊查询 * 允许用户输错,可以设置错误的最大编辑距离 * @throws IOException */ @Test public void fuzzyQuery() throws IOException { //"李百"->"李白",只需修改一次,故可以搜索到数据;"里百"则搜索不到数据 Query query = new FuzzyQuery(new Term("name", "里百"), 1); query(query); } /** * 数值查询 * @throws IOException */ @Test public void numberQuery() throws IOException { //精确查询 Query query = LongPoint.newExactQuery("id", 123456); query(query); //符围查询 query = LongPoint.newRangeQuery("id", 123L, 12345678L); query(query); } /** * 组合查询 * Occur.MUST:必须满足,相当于and * Occur.SHOULD:应该满足,但是不满足也可以,相当于or * Occur.MUST_NOT:必须不满足,相当于not */ @Test public void booleanQuery() throws IOException { Query query1 = new TermQuery(new Term("name", "李白")); Query query2 = new TermQuery(new Term("name", "杜甫")); BooleanQuery.Builder builder = new BooleanQuery.Builder(); builder.add(query1, BooleanClause.Occur.SHOULD); builder.add(query2, BooleanClause.Occur.SHOULD); BooleanQuery booleanQuery = builder.build(); query(booleanQuery); } /** * 设置查询权重,影响查询结果排序 * @throws IOException */ @Test public void boostQuery() throws IOException { Query query1 = new BoostQuery(new TermQuery(new Term("name", "李白")), 1.5f); Query query2 = new BoostQuery(new TermQuery(new Term("name", "杜甫")), 1.6f); BooleanQuery.Builder builder = new BooleanQuery.Builder(); builder.add(query1, BooleanClause.Occur.SHOULD); builder.add(query2, BooleanClause.Occur.SHOULD); BooleanQuery booleanQuery = builder.build(); query(booleanQuery); } /** * 分词查询 * @throws Exception */ @Test public void queryParserQuery() throws Exception { QueryParser queryParser = new QueryParser("name", new IKAnalyzer()); Query query = queryParser.parse("李白和杜甫"); query(query); //多字段查询 MultiFieldQueryParser multiFieldQueryParser = new MultiFieldQueryParser(new String[]{"name", "about"}, new IKAnalyzer()); query = multiFieldQueryParser.parse("李白和子美"); query(query); } private void query(Query query) throws IOException { Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher = new IndexSearcher(indexReader); //查询前10条数据 TopDocs topDocs = indexSearcher.search(query, 10); logger.info("本次搜索共找到" + topDocs.totalHits.value + "条数据"); ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { Document document = indexReader.document(scoreDoc.doc); //logger.info(document.toString()); logger.info("id={},name={},poems={},success={},score={}", document.get("id"), document.get("name"), document.get("poems"), document.get("success"), scoreDoc.score); } } /** * 删除索引 * 删除匹配的文档,更新或删除文档对应的索引。更新是更新索引与文档的对关系 * @throws IOException */ @Test public void deleteIndex() throws IOException { Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); Analyzer analyzer = new IKAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter indexWriter = new IndexWriter(directory, config); indexWriter.deleteDocuments(new Term("name", "李白")); //indexWriter.deleteAll(); indexWriter.commit(); indexWriter.close(); } /** * 更新索引,会先删除索引,再添加索引 * 相当于 deleteIndex() 和 createIndex() * @throws IOException */ @Test public void updateIndex() throws IOException { Document document = new Document(); document.add(new LongPoint("id", 123456)); document.add(new StoredField("id", 123456)); document.add(new IntPoint("age", 20)); document.add(new StringField("name", "李白", Field.Store.YES)); document.add(new TextField("poems", "望天门山", Field.Store.YES)); document.add(new TextField("about", "号青莲居士", Field.Store.NO)); Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); Analyzer analyzer = new IKAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter indexWriter = new IndexWriter(directory, config); indexWriter.updateDocument(new Term("name", "李白"), document); indexWriter.commit(); indexWriter.close(); } /** * 高亮显示,增加html标签,根据需要针对标签设置自定义的样式 * @throws Exception */ @Test public void highlighter() throws Exception { Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher = new IndexSearcher(indexReader); QueryParser queryParser = new QueryParser("success", new IKAnalyzer()); Query query = queryParser.parse("文学"); TopDocs topDocs = indexSearcher.search(query, 10); logger.info("本次搜索共找到" + topDocs.totalHits.value + "条数据"); Formatter formatter = new SimpleHTMLFormatter("<em>", "</em>"); QueryScorer queryScorer = new QueryScorer(query); Highlighter highlighter = new Highlighter(formatter, queryScorer); ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { Document document = indexReader.document(scoreDoc.doc); String success = document.get("success"); String successHL = highlighter.getBestFragment(new IKAnalyzer(), "success", success); logger.info("id={},name={},poems={},success={},score={}", document.get("id"), document.get("name"), document.get("poems"), successHL, scoreDoc.score); } } /** * 排序 * @throws Exception */ @Test public void sort() throws Exception { Directory directory = FSDirectory.open(Paths.get("d:/temp/luceneIndex")); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher = new IndexSearcher(indexReader); QueryParser queryParser = new QueryParser("success", new IKAnalyzer()); Query query = queryParser.parse("文学"); Sort sort = new Sort(new SortField("id", SortField.Type.LONG, false)); TopDocs topDocs = indexSearcher.search(query, 10, sort); logger.info("本次搜索共找到" + topDocs.totalHits.value + "条数据"); ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { Document document = indexReader.document(scoreDoc.doc); logger.info("id={},name={},poems={},success={},score={}", document.get("id"), document.get("name"), document.get("poems"), document.get("success"), scoreDoc.score); } } }
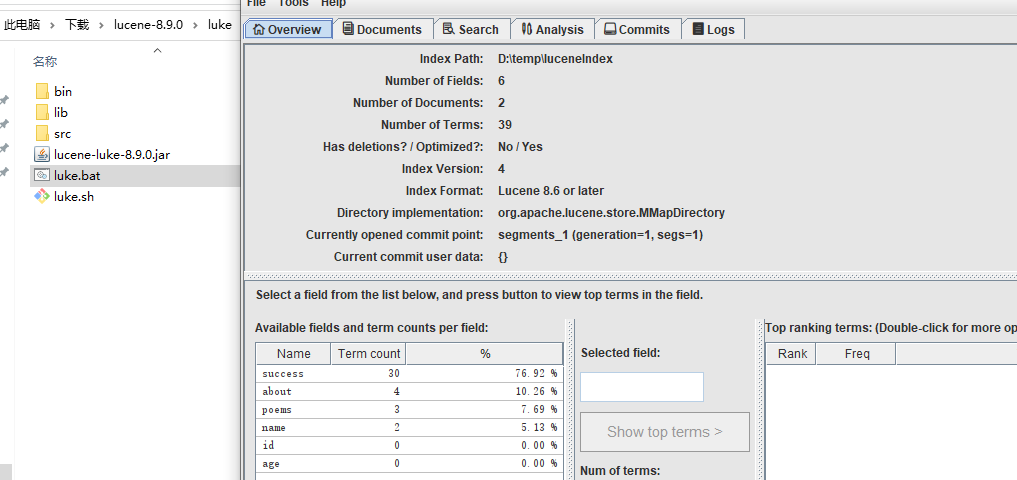
2.9、Luke 工具查看索引
下载的 Lucene 包里包含了 Luke 工具,运行 $LUCENE_HOME/luke/luke.bat,即可打开工具,选择索引目录后即可查看索引了: