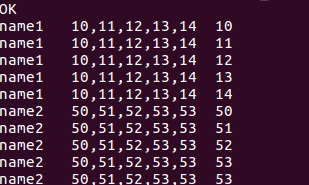
一:建表语句
drop table window_test;
create external table if not exists window_test
(
name string,
score string
)
row format delimited
fields terminated by '|'
location '/hive/table/window_test';
二:函数操作
sum与over实现定制sum
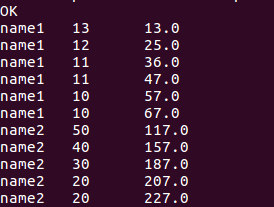
//查询当前行和下两行score总分的数据
select name, score, sum(score)over(order by name rows between current row and 2 following) from window_test;
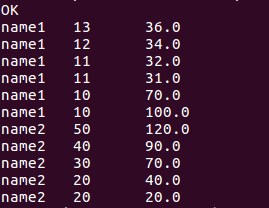
//查询当前行和上两行score总分的数据
select name, score, sum(score)over(order by name rows between 2 preceding and current row) from window_test;
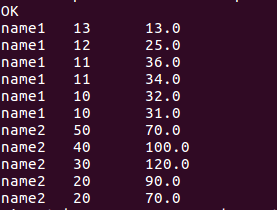
//查询当前行和以下行score总分的数据
select name, score, sum(score)over(order by name rows between current row and unbounded following) from window_test;
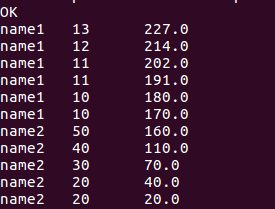
//查询当前行和以上行score总分的数据
select name, score, sum(score)over(order by name rows between unbounded preceding and current row) from window_test;
over排序
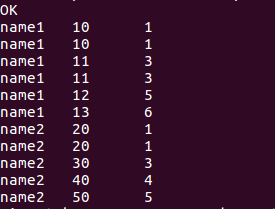
//排序函数 每一个name分组后从1开始排序,相同的数据列序号相同,后一个加一
select name, score, rank()over(partition by name order by score) from window_test;
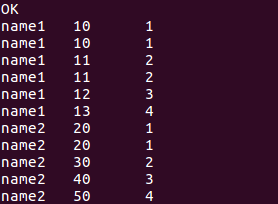
//排序函数 每一个name分组后从1开始排序,相同的数据列序号相同,后一个不加一
select name, score, dense_rank()over(partition by name order by score) from window_test;
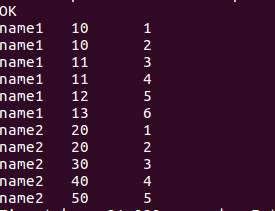
//排序函数 每一个name分组后从1开始排序,相同的数据列序号不相同
select name, score, row_number()over(partition by name order by score) from window_test;
组内最大值,最小值提取
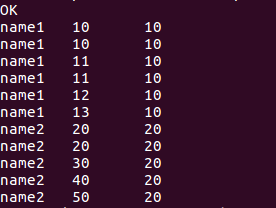
//分组内排正序取第一个score
select name, score, first_value(score)over(partition by name order by score) from window_test;
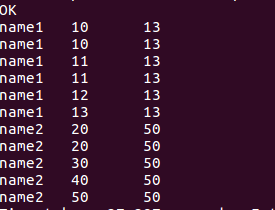
//分组内排正序取最后一个score
select name, score, last_value(score)over(partition by name order by score range between unbounded preceding and unbounded following) from window_test;
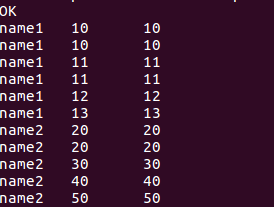
//函数的结果是错误的,必须要前面一大段
//select name, score, last_value(score)over(partition by name order by score) from window_test;
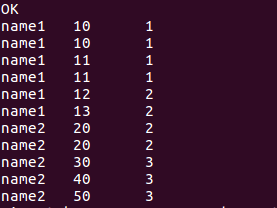
数据动态等级划分
//根据分数将数据分为三个区域
select name, score, ntile(3)over(order by score) from window_test;
上一行,下一行值提取
//下两行的score提过来,没有填充NULL
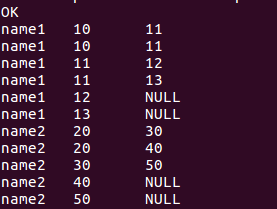
select name, score, lead(score,2)over(partition by name order by score) from window_test;
//上两行的score提过来,没有填充NULL
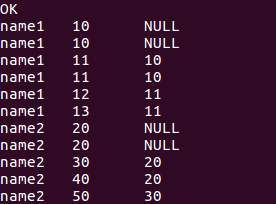
select name, score, lag(score,2)over(partition by name order by score) from window_test;
占比函数
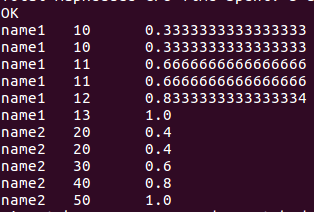
//小于当前值SCORE的人数占总人数的占比(name分组)
select name, score, cume_dist()over(partition by name order by score) from window_test;
行列转
//行转列
select name,concat_ws(',',collect_list(score)) as score_value from window_test group by name;

//列转行
select name,score,score_value from window_test lateral view explode(split(score,','))num as score_value;