CRF的进化
https://flystarhe.github.io/2016/07/13/hmm-memm-crf/参考:
http://blog.echen.me/2012/01/03/introduction-to-conditional-random-fields/
说明:因为MEMM只在局部做归一化,所以容易陷入局部最优,而CRF模型中,统计了全局概率,在做归一化时,考虑数据在全局的分布,而不是仅仅在局部归一化,解决了MEMM中的标记偏置的问题,可以得到全局最优;CRF没有HMM那样严格的独立性假设条件,因而可以容纳任意的上下文信息,特征设计灵活。但是CRF有明显的缺点:训练代价大、复杂度高。
补充说明:首先,CRF,HMM(隐马模型),MEMM(最大熵隐马模型)都常用来做序列标注的建模,像词性标注,True casing。但隐马模型一个最大的缺点就是由于其输出独立性假设,导致其不能考虑上下文的特征,限制了特征的选择,而最大熵隐马模型则解决了这一问题,可以任意的选择特征,但由于其在每一节点都要进行归一化,所以只能找到局部的最优值,同时也带来了标记偏见的问题(label bias),即凡是训练语料中未出现的情况全都忽略掉,而条件随机场则很好的解决了这一问题,他并不在每一个节点进行归一化,而是所有特征进行全局归一化,因此可以求得全局的最优值。目前,条件随机场的训练和解码的开源工具还只支持链式的序列,复杂的尚不支持,而且训练时间很长,但效果还可以。
标记偏置问题:MEMM最大熵马尔可夫模型
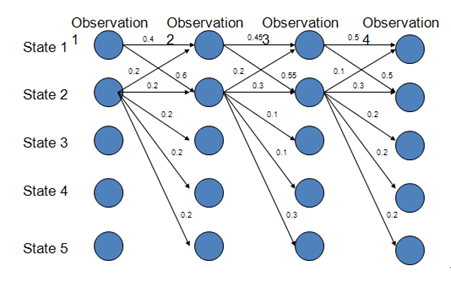
路径1-1-1-1的概率:0.4*0.45*0.5=0.09
路径2-2-2-2的概率:0.2*0.3*0.3=0.018
路径1-2-1-2的概率:0.6*0.2*0.5=0.06
存在的问题:State 1中每个结点都倾向于转移到State 2,由于MEMM的局部归一化特性,使得转出概率的分布不均衡,最终导致状态的转移存在不公平的情况
如果把每个节点转出概率和为1的限制去掉,比如我们简单把图中State 2中每个结点出发的边的概率值×10
路径1-1-1-1的概率:0.4*0.45*0.5=0.09
路径2-2-2-2的概率:2*3*3=18
路径1-2-1-2的概率:0.6*2*0.5=0.6
HMM,MEMM,CRF
HMM模型中两个假设:一是输出观察值之间严格独立,二是状态的转移过程中当前状态只与前一状态有关(一阶马尔可夫模型)
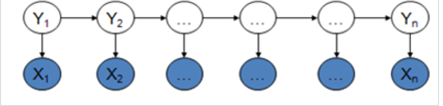
MEMM模型克服了观察值之间严格独立产生的问题

CRF模型解决了标注偏置问题

CRF的部分推导
CRF的特征函数
对分数进行标准化和归一化:


CRF的求解
优化采用的是带惩罚项的极大似然估计


求解可以用梯度上升,牛顿法,BFGS
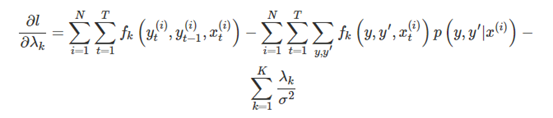
CRF和HMM之间的联系
HMM的定义:(每个HMM都能对应莫个CRF)
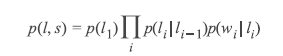

CRF可以定义数量更多,种类更丰富的特征函数。HMM模型具有天然具有局部性,就是说,在HMM模型中,当前的单词只依赖于当前的标签,当前的标签只依赖于前一个标签。这样的局部性限制了HMM只能定义相应类型的特征函数,我们在上面也看到了。但是CRF却可以着眼于整个句子s定义更具有全局性的特征函数,如这个特征函数:
CRF可以使用任意的权重 将对数HMM模型看做CRF时,特征函数的权重由于是log形式的概率,所以都是小于等于0的,而且概率还要满足相应的限制