response= requests.get(url) # 获取请求 response.text # 获取文本 response.content # 获取内容 response.encoding # 解码 response.aparent_encoding # 转码 response.status_code # 状态码
soup = beautifulsoup(id= ‘ ~~~‘, features = 'html.parser') # 得到这个id区域的对象
v1 = soup.find('div') # 查找这个对象的一个对象
v2 = soup.find_all(’div‘) # 查找这个对象的所有对象得到一个列表
obj = v1
obj = v2[0] # 获取列表第一个对象数据
obj.text # 获取数据
obj.attrs # 获取标签属性的内容
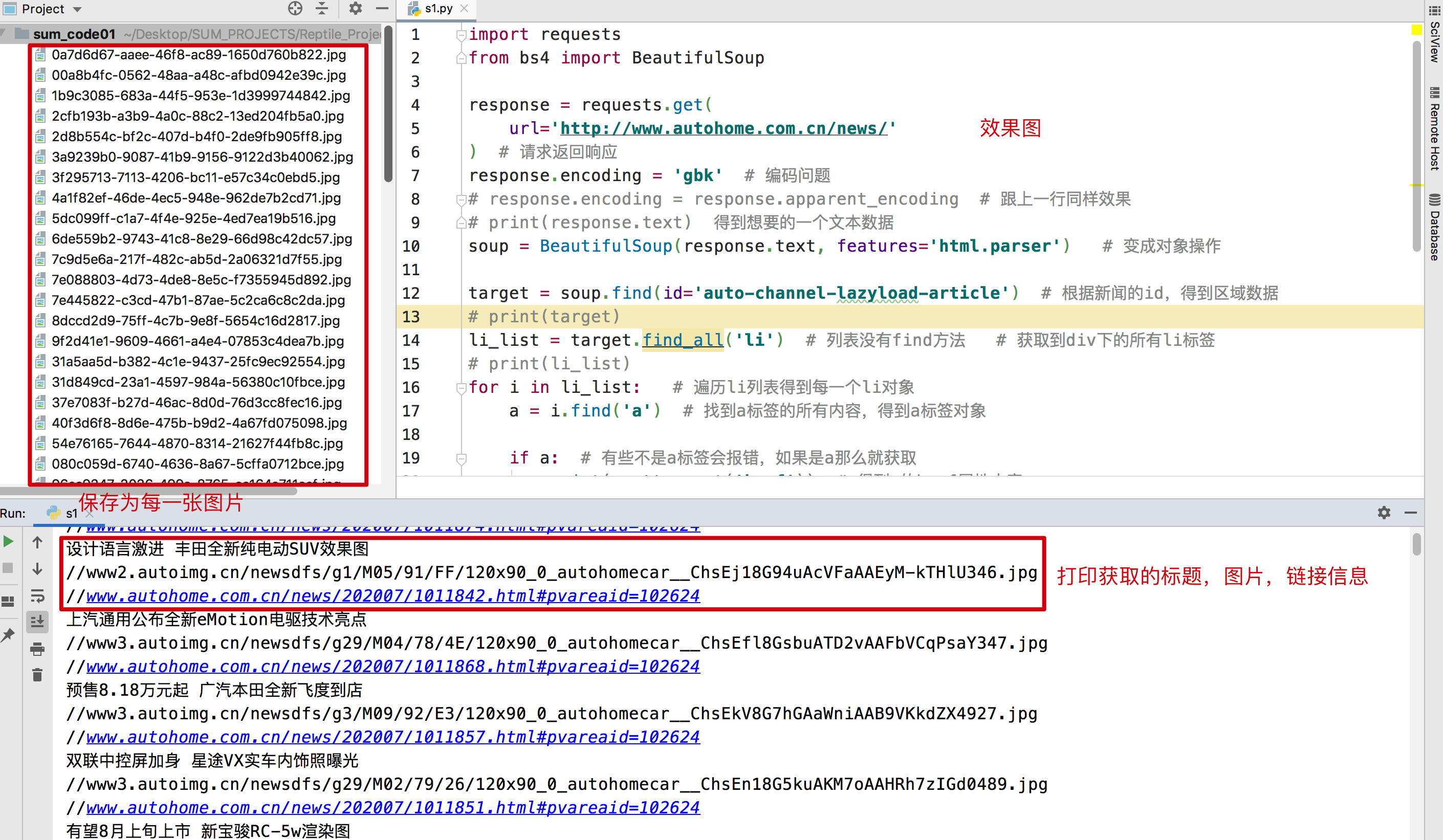
import requests from bs4 import BeautifulSoup response = requests.get( url='http://www.autohome.com.cn/news/' ) # 请求返回响应 response.encoding = 'gbk' # 编码问题 # response.encoding = response.apparent_encoding # 跟上一行同样效果 # print(response.text) 得到想要的一个文本数据 soup = BeautifulSoup(response.text, features='html.parser') # 变成对象操作 target = soup.find(id='auto-channel-lazyload-article') # 根据新闻的id,得到区域数据 # print(target) li_list = target.find_all('li') # 列表没有find方法 # 获取到div下的所有li标签 # print(li_list) for i in li_list: # 遍历li列表得到每一个li对象 a = i.find('a') # 找到a标签的所有内容,得到a标签对象 if a: # 有些不是a标签会报错,如果是a那么就获取 print(a.attrs.get('href')) # 得到a的href属性内容 txt = a.find('h3').text # 什么类型 对象 没有.text 是对象,获取h3的文本内容 print(txt) img_url = a.find('img').attrs.get('src') # 获取img的src属性,得到img链接 print(img_url) img_url = 'http:' + img_url # 由于爬取下来没有http:所以拼接一个完整的url img_response = requests.get(url=img_url) # 请求所有的img_url import uuid # 导包uuid file_name = str(uuid.uuid4()) + '.jpg' # 生成随机的文件名 .jpg 图片名字后缀 with open(file_name, 'wb') as f: # 打开文件名,写入数据 f.write(img_response.content)
效果图
爬取中遇到的错误
图片链接是不完整的,所以前面拼接了http:
总结:通过这个案例,学会使用BeautiSoup模块。学会请求和分析网页。