写在前面
提到淘宝,很多人会惊叹淘宝的营销能力,淘宝上货种类很全,很便宜。但我作为一个将来的从业人员,我一直对于淘宝如何处理如此庞大的数据感到好奇。在我自己的开发中,我的数据量到一万条左右搜索就要完全崩溃了,更别提淘宝那几十亿的搜索量。在网上冲浪的偶然间,发现了这本《淘宝技术这十年》,虽然距今已经有七年了,但对于了解其中的软件工程思想和技术还是有所帮助的。(本文的图均来自书中插图)
从光棍节说起
在2011年11月11日,淘宝商城与淘宝网交易额之和突破了52亿人民币。在淘宝这样的盛况下,是淘宝背后十分强大的技术力的体现。正是由于淘宝具有能够承担起这种流量的技术力,才能真正的做好这些。
淘宝的创立和基本发展
根据这本书所说,早期的淘宝其实就是从别人那里买来的LAMP网站(linux+Apache+mysql+php),可以看到早期的淘宝也是购买的别人的系统,他们在这套系统的基础上加上了自己的需求————对数据库进行了一个修改,把数据库分成一个主库,两个从库。并且读写分离。这时候的淘宝就有了自己的第一套基本架构:
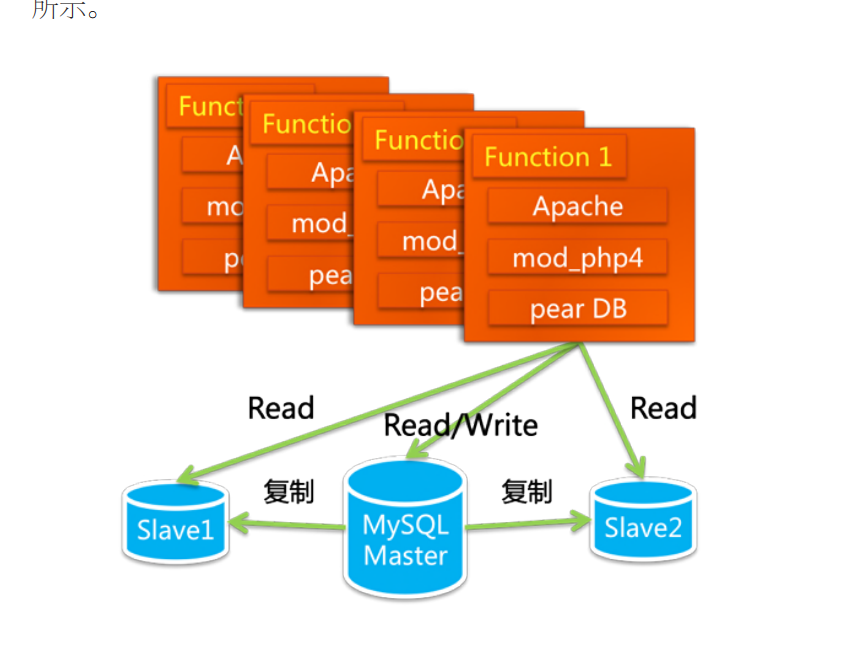
在这个基本架构中,我们可以看到这个架构与我们常规的设计相比,最大的区别便是将数据库分了两个子库,一个读一个写。
随着访问人数的提升,mysql这样的轻量级数据库不再能满足淘宝的需求。于是淘宝试用了Oracle数据库,并对架构进行了一些革新:

这里使用了SQL Relay这样的数据库连接池,以更好的提升数据库的性能。在这样的架构下,淘宝的性能又进一步提升了。