Python-函数编程
1,基本介绍
定义:函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可。简单一点,命令打包,然后提高了协作性,想在哪里执行就在哪里执行。
特性:
- 减少重复代码,增加复用性
- 使程序变的可拓展性
- 使程序变得易维护
- 灵活清晰
语法:
def functionname( parameters ): # 函数名 "函数_文档字符串" functionname() # 调用函数,函数名只是指向相应地址,这个括号的作用才是要执行那段代码
也可以带参数
# 下面这段代码
a,b = 5,8
c = a**b
print(c)
# 改成用函数写
def calc(x,y):
res = x**y
return res # 返回函数执行结果
c = calc(a,b) # 结果赋值给c变量
print(c)
在定义函数的过程中,需要注意以下几点:
- 函数代码块以
def关键词开头,一个空格之后接函数标识符名称和圆括号(),再接个冒号。 - 任何传入的参数必须放在圆括号中。
- 函数的第一行语句后可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- 使用return结束函数。默认返回None。
- return语句依然在函数体内部,不能回退缩进。直到函数的所有代码写完,才回退缩进,表示函数体结束。
2,函数参数
参数可以让你的函数更灵活,不只能做死的动作,还可以根据调用时传参的不同来决定函数内部的执行流程。
1.0 形参变量
只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
1.1 实参
可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值

2.0 默认参数
def stu_register(name, age, country, course):
print('------学生注册信息-------')
print('姓名:', name)
print('age:', age)
print('国籍:', country)
print('课程:', course)
stu_register("王山炮",22, 'CN', 'python_devops')
stu_register("张角春", 21, 'CN', 'Linux')
stu_register("刘老根", 25, 'CN', 'Linux')
这里出现了很多的 'CN',可以设置默认参数,就可以直接替代
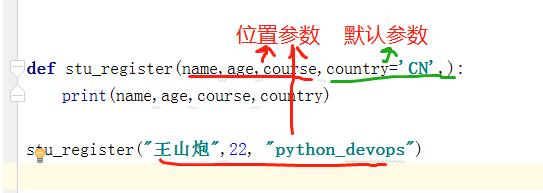
def stu_register(name, age, course, country = 'CN'): # 这里的默认参数放在最后面
print('------学生注册信息-------')
print('姓名:', name)
print('age:', age)
print('国籍:', country)
print('课程:', course)
stu_register("王山炮",22, 'python_devops', 'UN') # 如果不想使用默认参数的值,可以在最后面自定义想要的参数的值
stu_register("张角春", 21, 'Linux')
stu_register("刘老根", 25, 'Linux')


------学生注册信息------- 姓名: 王山炮 age: 22 国籍: UN 课程: python_devops ------学生注册信息------- 姓名: 张角春 age: 21 国籍: CN 课程: Linux ------学生注册信息------- 姓名: 刘老根 age: 25 国籍: CN 课程: Linux
这里的country默认参数一定要写在最后面,否则会报错,为什么呢?
因为如果设置默认参数,实际上排序上面就会造成一定的乱序,为了不乱序,python里头设定默认参数就是放在最后面,有这样的设定,就不会出现乱序啦
2.1位置参数
调用函数时根据函数定义的参数位置来传递参数称为位置参数。
2.2关键参数
正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可(指定了参数名的参数就叫关键参数),但记住一个要求就是,关键参数必须放在位置参数(以位置顺序确定对应关系的参数)之后


关键参数就是位置参数带有参数名,两者结合为关键参数。第二个关键参数不能在位置参数的前面。第三个不能重复赋值
3.1非固定参数 *arg(参数):元组
如果参数中出现,*users,传递的参数就可以不是固定个数参数,传过来的参数打包成元组
# 报警, 1个运维人员
def send_alert(mgs, user):
pass
send_alert('出现error,请处理', 'alex')
# 报警,10个运维人员
def send_alert(mgs, *users): #('alex', 'xxx', 'ttt')
for u in users:
print('%s->%s'%(mgs,u))
send_alert('出现error,请处理', 'alex', 'xxx','ttt')
# 运行结果 出现error,请处理->alex 出现error,请处理->xxx 出现error,请处理->ttt
3.2如果传过来的是list,会把他作为元组的第一个元素
# 报警,10个运维人员
def send_alert(mgs, *users): # ('alex', 'xxx','ttt')---> (['alex', 'xxx', 'ttt'])
for u in users:
print('%s->%s'%(mgs,u))
#send_alert('出现error,请处理', 'alex', 'xxx','ttt')
send_alert('出现error,请处理', ['alex', 'xxx','ttt'])
# 运行结果 出现error,请处理->['alex', 'xxx', 'ttt']
3.3传入list,使用一个星号
不光列表,任何序列类型数据对象,比如字符串、元组都可以通过这种方式将内部元素逐一作为参数,传递给函数。而字典,则会将所有的key逐一传递进去。
def send_alert(mgs, *users): # ('alex', 'xxx','ttt')---> ('alex', 'xxx', 'ttt')
print(users)
for u in users:
print('%s->%s'%(mgs,u))
send_alert('出现error,请处理', *['alex', 'xxx','ttt'])
# 运行结果
('alex', 'xxx', 'ttt')
出现error,请处理->alex
出现error,请处理->xxx
出现error,请处理->ttt
def send_alert(mgs, *users, age):
for u in users:
print('%s->%s' % (mgs, u),age)
send_alert('出现error,请处理', 'alex', 'rain', age=22)
# 如果在第四行age不指定等于22,则会报错,因为此时*users作为非固定参数,可以传多个值进去,而在第一行将age放在*users后面,则传值的时候必须带上参数,否则位置参数只能放在非固定参数的前面。
# 执行结果
# 出现error,请处理->alex 22
# 出现error,请处理->rain 22
3.4非固定参数,**kwargs 字典
def func(name, degree, *args, **kwargs):
print(name, degree, args, kwargs)
func('xiaoqiu', 'dortor', 'sichuan', 'beijing', addr = 'shanxi')
# 这里*args对应下面的'sichuan','beijing'可以变为一个元组
# 这里**kwargs对应下面的addr = 'shanxi' 可以变为一个字典
# 执行结果
# xiaoqiu dortor ('sichuan', 'beijing') {'addr': 'shanxi'}
4.0 “万能”参数
当*args和**kwargs组合起来使用,理论上能接受任何形式和任意数量的参数,在很多代码中我们都能见到这种定义方式。需要注意的是,*args必须出现在**kwargs之前。
def func(*args, **kwargs):
for arg in args:
print(arg)
for kwg in kwargs:
print(kwg, kwargs[kwg])
lis = [1, 2, 3]
dic = {'k1': 'v1', 'k2': 'v2'}
func(*lis, **dic)
# 执行结果
# 1
# 2
# 3
# k1 v1
# k2 v2
5.0 拆包
- 把元组拆成一个个,当成参数传递
- 把字典拆成一对对键值对,当成参数传递
###### 拆包之前
def test(a,b,c=33,*args,**kwargs):
print(a)
print(b)
print(c)
print(args)
print(kwargs)
A = (44,55,66)
B = {"name":"alex","age":18}
test(11,22,33,A,B)
#### 运行结果
11 22 33
((44, 55, 66), {'age': 18, 'name': 'alex'}) #A,B是传递的参数
{} #没有传入命名参数
#### 拆包之后
def test(a,b,c=33,*args,**kwargs):
print(a)
print(b)
print(c)
print(args)
print(kwargs)
A = (44,55,66)
B = {"name":"alex","age":18}
test(11,22,33,*A,**B)
#### 运行结果
11
22
33
(44, 55, 66)
{'age': 18, 'name': 'alex'}
3,return,返回值
1,return语句
函数外部的代码想要获取函数的执行结果,就可以在函数里用return语句把结果或对象返回。并且表示函数执行到此结束。有时候,函数不需要返回任何值,此时可以不需要return语句,它在后台默认给你返回个None,并且不给任何提示
但是更多的时候我们还是需要return一些东西。一旦函数执行过程遇到return语句,那么之后函数体内的所有代码都会被忽略,直接跳出函数体。哪怕你现在正在一个循环内。
def stu_register(name, age, country, course):
print('------学生注册信息-------')
print(name, age, country, course)
return None # 这里的return None可加可不加,后面结果都是返回None
print('nihao') # 即使这里还有内容没有输出,因为return在这之前,所以到return这里立即终止执行
# 所以,执行return的时候相当于直接跳出了函数体
# return 1 # 这里也不执行
status = stu_register("王山炮",29, 'CN', 'python_devops')
print(status)
# 执行结果
------学生注册信息-------
王山炮 29 CN python_devops
None
一旦函数执行过程遇到return语句,那么之后函数体内的所有代码都会被忽略,直接跳出函数体。
def stu_register(name, age, country, course):
print('------学生注册信息-------')
print(name, age, country, course)
if age > 22:
return False
else:
return True
status = stu_register("王山炮",29, 'CN', 'python_devops')
print(status)
# 执行结果
------学生注册信息-------
王山炮 29 CN python_devops
False
函数只能返回一个值,但是在return后面也能返回一个元组或者是一个字典
# 接着上面例子
return False,age
#执行结果
('False',24)
# 再例如
return [False,age]
# 执行结果
['False',24]
2,return返回值的类型
return可以返回什么类型的值,看下面顺便总结一下,函数可以return几乎任意python对象
什么都不返回,仅仅return:return 数字/字符串/任意数据类型: return 'hello' 一个表达式:return 1+2 一个判断语句:return 100 > 99 一个变量:return a 一个函数调用:return func() 甚至是返回自己!:return self 多个返回值,以逗号分隔:return a, 1+2, "hello"
3,如何接收函数返回值?
我们在调用函数的时候,可以将函数的返回值保存在变量中。
def func():
pass
return "something"
result = func()
而对于同时返回多个值的函数,需要相应个数的变量来接收,变量之间以逗号分隔:
def func():
return 1, [2, 3], "haha"
a, b, c = func()
4,全局变量,局部变量
4.1两者的作用与关系
全局变量:定义在函数外部一级代码(没有缩进)的变量,这个变量全局都能使用(到那时要注意顺序)
局部变量:指定义在函数里面的变量,只能在局部生效。
name = 'beauty'
def change_name():
name = '这个是里面的美女'
print(name, id(name))
change_name()
print(name, id(name))
# 这里第一个name是一个全局变量,而第二个name是一个局部变量,它们作用的范围不一样,局部变量只对函数内部产生了影响,而全局变量对外面这个大的环境产生了影响。
#执行结果
这个是里面的美女 2038317628272
beauty 2038317363864
# 通过输出两个name的id可以看出,他们所指向的地址是不一样的
如果在函数内部没有定义一个局部变量,则函数会使用全局变量;
如果局部和全局变量都定义了,则函数内部会优先使用局部变量。所以两者之间存在一个由内而外的使用顺序。但是两个函数内部的局部变量又是不能共同使用的,互不干扰。
name = 'beauty'
def change_name():
# name = '这个是里面的美女'
print(name, id(name))
change_name()
print(name, id(name))
# 这里直接执行全局变量定义的一个name,函数里面能调用全局变量,但是函数外面不能调用局部变量
# 执行结果
beauty 1868336181912
beauty 1868336181912
4.2在函数里面修改全局变量
一般情况下不建议使用这种方法,在函数里面修改以后,如果后面要引用全局变量的话,就不知道这个全局变量是已经被修改过了
name = 'beauty'
def change_name():
global name # 引用修改全局变量一定要在局部变量之前
name = '美女'
print(name, '这个是里面打印的', id(name))
change_name()
print(name, '这个是外面打印的', id(name))
# 注意:这里的指定在函数内部的全局变量一定要在局部变量之前,否则会报错
# 所以,在函数里面修改全局变量,以后引用global,就把全局放在上面,不能放在下面
#执行结果
美女 这个是里面打印的 2114053808040
美女 这个是外面打印的 2114053808040
4.3在函数里修改列表数据
先创建两个列表,运行结果和变量类似
nums = [11, 22, 33, 44]
def change_num():
nums = [11, 22, 33]
print(nums)
change_num()
print(nums)
# 执行结果
[11, 22, 33]
[11, 22, 33, 44]
# 这里的运行结果和变量是差不过的
要修改整个列表的,也要用global来修改
# 对列表数据进行修改
nums = [11, 22, 33, 44]
def change_num():
del nums[3]
nums[2] = 99
print(nums)
change_num()
print(nums)
# 执行结果
# [11, 22, 99]
# [11, 22, 99]
# 对于函数外面的nums,每个列表整体都有一个内存地址,列表里面的每个元素又都有一个
# 地址相对应,在函数里面调用整体的nums的内存地址是不能够被修改的,只能引用它,相
# 当于给列表整体赋值是不能够改的,单个元素可以修改
# 可以修改的类型:列表,字典,集合,对象,类,里面有一串的是可以修改的
# 不可以修改的,数字,字符串
nums = [11, 22, 33, 44]
def change_num():
global nums
nums = ['我', '是', '在', '里', '面', '的']
print(nums)
change_num()
print(nums)
# 执行结果
['我', '是', '在', '里', '面', '的']
['我', '是', '在', '里', '面', '的']
# 对于修改,通用可以采用global进行修改
5,嵌套函数
嵌套函数(用于先准备一个函数,即外层函数执行完后,内层函数仍可以使用外层函数的变量),装饰器就是这种应用
注意:①函数内部可以再次定义函数。②执行需要被调用才能执行
③执行顺序,由内而外,一层一层往上
def line_conf(a, b):
def line(x):
return a*x + b
return line
line1 = line_conf(1, 1)
line2 = line_conf(4, 5)
print line1(5)
print line2(5)
#######
6
25
# 详细见高阶函数装饰器
# 嵌套函数
def func1():
print('qiuma')
def func2():
print('qiuma2')
func2()
func1()
# 执行结果
# qiuma
# qiuma2
# 因为这里首先func2是在func1里面的,按照print顺序,所以先得到qiuma
def func1():
def func2():
print('qiuma2')
func2()
print('qiuma')
func1()
# 执行结果
qiuma2
qiuma
再举几个例子,来理解嵌套函数
# example01
age = 19
def func1():
age = 73
def func2():
print(age)
func2()
func1()
# 执行结果为73
# example02
age = 19
def func1():
def func2():
print(age)
age = 73
func2()
func1()
# 执行结果为73
# example03
age = 19
def func1():
def func2():
print(age)
func2()
age =73
func1()
# 执行结果:报错,此时func2里面的age不知道应该找那个age,所以,报错
# example04
age = 19
def func1():
global age # 此时age已经等于19了,所以后面的age=73就不能赋值进去了
def func2():
print(age)
func2()
age = 73 # 这个时候age=73影响到了全局,所以最后一个print为age=73
func1()
print(age)
# 执行结果为 19 73
# example05
age = 19
def func1():
global age # 这个age = 19
def func2():
print(age)
age = 73 # 这里的定义其实是已经将全局变量改为73了
func2()
func1()
# 执行结果73
# 因为func2里面有age=73,后面又执行使得全局age=73了
6,作用域
作用域(scope),程序设计概念,通常来说,一段程序代码中所用到的名字并不总是有效/可用的,而限定这个名字的可用性的代码范围就是这个名字的作用域。
在之前学习变量的作用域时,经常会提到局部变量和全局变量,之所有称之为局部、全局,就是因为他们的自作用的区域不同,这就是作用域。
python中一个函数就是一个作用域。
所有的局部变量其实是放置于(当前函数的)作用域里面。
定义完成后,作用域已经生成,作用域链向上查找。
age = 18
def func1():
age = 73
def func2():
print(age)
return func2 # 这里将函数名当作了返回值
val = func1()
val()
# 定义完成后,作用域已经生成,作用域链向上查找。
# 只要是函数的作用域定义好了,无论这个函数被调用到哪里,还是会回来找这个函数定义的时候的作用域
7,lambda-匿名函数
特点加上与def普通函数的区别:
1)def创建的方法是有名称的,而lambda没有。
2)lambda会返回一个函数对象,但这个对象不会赋给一个标识符,而def则会把函数对象赋值给一个变量(函数名)。
3)lambda只是一个表达式,而def则是一个语句。
4)lambda表达式” : “后面,只能有一个表达式,def则可以有多个。
5)lambda一般用来定义简单的函数,而def可以定义复杂的函数。
6)lambda函数不能共享给别的程序调用,def可以。
lambda语法格式:
lambda 变量 : 要执行的语句
作用:通常与三元运算一起搭配
1.节省代码量
2.装B
def calc(x, y):
if x < y:
return x * y
else:
return x / y
func = lambda x, y: x*y if x < y else x/y # 声明一个匿名函数
print(func(16, 8))
print(calc(16, 8))
搭配map使用,下面代码3-5=6,节省代码量
data = list(range(10)) print(data) # for index,i in enumerate(data): # data[index] = i*i # print(data) print(list(map(lambda x: x*x, data))) # map 里面跟上一个函数加上一个数据集
8,高阶函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
编写高阶函数,就是让函数的参数能够接收别的函数。
只需满足以下任意一个条件,即是高阶函数
接受一个或多个函数作为输入
return 返回另外一个函数本身
# 接受一个或多个函数作为输入
def add(x, y, f):
return f(x)+f(y)
val = add(5, 6, abs) # 参数可以接受函数
print(val)
# return返回另外一个函数本身
def calc(x, y):
return x+y
def add2():
return calc # return可以返回另一个函数
val2 = add2()
print(val2(3, 6))
9,递归函数
1.什么是递归
递归,就是在函数的执行过程中调用自己。
代码示例
def recursion(n):
print(n)
recursion(n+1)
recursion(1)
# 从这个函数在不断的调用自己,每次调用就n+1,相当于循环了。执行结果就是从0一直打印到997然后报错。
但是为什么会出错呢?
通俗来讲,是因为每个函数在调用自己的时候 还没有退出,占内存,多了肯定会导致内存崩溃。
本质上讲呢,在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。
查看递归的深度是?
import sys print(sys.getrecursionlimit()) # 执行结果为 1000
2.递归深层次理解
下面程序能够说明递归存下的数字,然后再执行完函数之后一个一个再调出来。
def calc(n):
print(n) # 这里打印一次n
if int(n/2) > 0:
calc(int(n/2))
else:
print('-----')
print(n) # 这里打印一次n
calc(10)
# 执行结果
10
5
2
1
-----
1
2
5
10
为何结果先打印了10、5、2、1,然后又打印了1、2、5、10呢?打印10、5、2、1你可以理解,因为函数在一层层的调用自己嘛,但1、2、5、10是什么逻辑呢? 因为当前函数在执行过程中又调用了自己一次,当前这次函数还没结束,程序就又进了入第2层的函数调用,第2层没结束就又进入了第3层,只到n/2 > 0不成立时才停下来, 此时问你,程序现在直接结束么?no,no,no, 现在递归已经走到了最里层,最里层的函数不需要继续递归了,会执行下面2句

打印的是1, 然后最里层的函数就结束了,结束后会返回到之前调用它的位置。即上一层,上一层打印的是2,再就是5,再就是10,即最外层函数,然后结束,总结,这个递归就是一层层进去,还要一层层出来。

通过上面的例子,我们可以总结递归几个特点:
①必须有一个明确的结束条件,要不就会变成死循环了,最终撑爆系统
②每次进入更深一层递归时,问题规模相比上次递归都应有所减少
③递归执行效率不高,递归层次过多会导致栈溢出
3.递归实际案例
3.0 求阶乘
任何大于1的自然数n阶乘表示方法:
n!=1×2×3×……×n
或
n!=n×(n-1)!
即举例:4! = 4x3x2x1 = 24
用递归代码来实现
def factorial(n):
if n == 0: #是0的时候,就运算完了
return 1
return n * factorial(n-1) # 每次递归相乘,n值都较之前小1
d = factorial(4)
print(d)
3.1 二分查找
我们首先引入这样一个问题:如果规定某一科目成绩分数范围:[0,100],现在小明知道自己的成绩,他让你猜他的成绩,如果猜的高了或者低了都会告诉你,用最少的次数猜出他的成绩,你会如何设定方案?(排除运气成分和你对小明平时成绩的了解程度) ①最笨的方法当然就是从0开始猜,一直猜到100分,考虑这样来猜的最少次数:1(运气嘎嘎好),100(运气嘎嘎背); ②其实在我们根本不知道对方水平的条件下,我们每一次的猜测都想尽量将不需要猜的部分去除掉,而又对小明不了解,不知道其水平到底如何,那么我们考虑将分数均分, 将分数区间一分为2,我们第一次猜的分数将会是50,当回答是低了的时候,我们将其分数区域从【0,100】确定到【51,100】;当回答高了的时候,我们将分数区域确定到【0,49】。这样一下子就减少了多余的50次猜想(从0数到49)(或者是从51到100)。 ③那么我们假设当猜完50分之后答案是低了,那么我们需要在【51,100】分的区间内继续猜小明的分数,同理,我们继续折半,第二次我们将猜75分,当回答是低了的时候,我们将其分数区域从【51,100】确定到【76,100】;当回答高了的时候,我们将分数区域确定到【51,74】。这样一下子就减少了多余的猜想(从51数到74)(或者是从76到100)。 ④就此继续下去,直到回复是正确为止,这样考虑显然是最优的 转换成代码 在一个已排序的数组data_set中,使用二分查找n,假如这个数组的范围是[low...high],我们要的n就在这个范围里。查找的方法是拿low到high的正中间的值,我们假设是mid,来跟n相比,如果mid>n,说明我们要查找的n在前数组data_set的前半部,否则就在后半部。无论是在前半部还是后半部,将那部分再次折半查找,重复这个过程,知道查找到n值所在的地方。
data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35]
def binary_search(dataset,find_num):
print(dataset)
if len(dataset) >1:
mid = int(len(dataset)/2)
if dataset[mid] == find_num: #find it
print("找到数字",dataset[mid])
elif dataset[mid] > find_num :# 找的数在mid左面
print("�33[31;1m找的数在mid[%s]左面�33[0m" % dataset[mid])
return binary_search(dataset[0:mid], find_num)
else:# 找的数在mid右面
print("�33[32;1m找的数在mid[%s]右面�33[0m" % dataset[mid])
return binary_search(dataset[mid+1:],find_num)
else:
if dataset[0] == find_num: #find it
print("找到数字啦",dataset[0])
else:
print("没的分了,要找的数字[%s]不在列表里" % find_num)
3.2 深度查询
menus = [
{
'text': '北京',
'children': [
{'text': '朝阳', 'children': []},
{'text': '昌平', 'children': [
{'text': '沙河', 'children': []},
{'text': '回龙观', 'children': []},
]},
]
},
{
'text': '上海',
'children': [
{'text': '宝山', 'children': []},
{'text': '金山', 'children': [
{'text': 'wps', 'children': []},
{'text': '毒霸', 'children': []},
]},
]
}
]
# 深度查询
# 1.打印所有的节点
# 2.输入一个节点名字
# 沙河,你要遍历找,找到了,就打印ta,并返回True
4.尾递归
增加函数执行效率,我们说递归效率不高,因为每递归一次,就多了一层栈,递归次数太多还会导致栈溢出,这也是为什么python会默认限制递归次数的原因。但有一种方式是可以实现递归过程中不产生多层栈的,即尾递归,
如果一个函数中所有递归形式的调用都出现在函数的末尾,我们称这个递归函数是尾递归的。当递归调用是整个函数体中最后执行的语句且它的返回值不属于表达式的一部分时,这个递归调用就是尾递归。尾递归函数的特点是在回归过程中不用做任何操作,这个特性很重要,因为大多数现代的编译器会利用这种特点自动生成优化的代码。
当编译器检测到一个函数调用是尾递归的时候,它就覆盖当前的活动记录而不是在栈中去创建一个新的。编译器可以做到这点,因为递归调用是当前活跃期内最后一条待执行的语句,于是当这个调用返回时栈帧中并没有其他事情可做,因此也就没有保存栈帧的必要了。通过覆盖当前的栈帧而不是在其之上重新添加一个,这样所使用的栈空间就大大缩减了,这使得实际的运行效率会变得更高。
下面为尾递归例子
def calc(n):
print(n - 1)
if n > -50:
return calc(n-1)
我们之前求的阶乘是尾递归么?下面这个不是尾递归,因为最后一个n是依赖于上一个n的返回值。存在依赖关系
def factorial(n):
if n == 0: #是0的时候,就运算完了
return 1
return n * factorial(n-1) # 每次递归相乘,n值都较之前小1
d = factorial(4)
print(d)
上面的这种递归计算最终的return操作是乘法操作。所以不是尾递归。因为每个活跃期的返回值都依赖于用n乘以下一个活跃期的返回值,因此每次调用产生的栈帧将不得不保存在栈上直到下一个子调用的返回值确定
10,内置方法
