Π-Model、Temporal Ensembling 和 Mean Teacher 三者都是利用一致性正则(consistency regularization)来进行半监督学习(semi-supervised learning)。
一致性正则要求一个模型对相似的输入有相似的输出,即给输入数据注入噪声,模型的输出应该不变,模型是鲁棒的。
Π-Model

Π-Model 可以说是最简单的一致性正则半监督学习方法了,训练过程的每一个 epoch 中,同一个无标签样本前向传播(forward)两次,通过 data augmentation 和 dropout 注入扰动(或者说随机性、噪声),同一样本的两次 forward 会得到不同的 predictions,Π-Model 希望这两个 predictions 尽可能一致,即模型对扰动鲁棒。
Temporal Ensembling for Semi-Supervised Learning 这篇文章应该是正式提出 Π-Model 的论文,Semisupervised learning with ladder networks 这篇提出的是 Γ-model,Π-Model 是其简化版。Π-Model 在一个 epoch 对每个无标签样本只 forward 两次,而如果是 forward 多次,那么就是 transformation/stability 方法,所以 Π-Model 是 transformation/stability 方法的特例。
Temporal Ensembling

Temporal Ensembling 对 Π-Model 的改进在于,训练过程的每一个 epoch 中,同一个无标签样本前向传播(forward)一次。那么另一次怎么办呢?Temporal Ensembling 使用之前 epochs 得到的 predictions 来充当,具体做法是用指数滑动平均(Exponentially Moving Average,EMA)的方式计算之前 epochs 的 predictions,使得 forward 的次数减少一半,速度提升近两倍。
Temporal Ensembling 的 ensembling在哪?通过 EMA 来平均之前 epochs 的模型的输出,这隐式地利用了集成学习的思想。
一个问题,利用 EMA 能得到当前 epoch 下模型准确的 prediction 吗?在训练前期,模型经过一个 epoch 训练提升就很大,这个时候很可能就是不准的,即使 EMA 有集成学习的思想;在训练后期,模型效果一个 epoch 提升不明显或者较小,这个时候 EMA 得到的 prediction 和当前 epoch 下的 prediction 应该就相近了。而随训练过程逐渐增大无标签样本权重 (w(t)) 可以缓解这个问题。
Mean Teacher
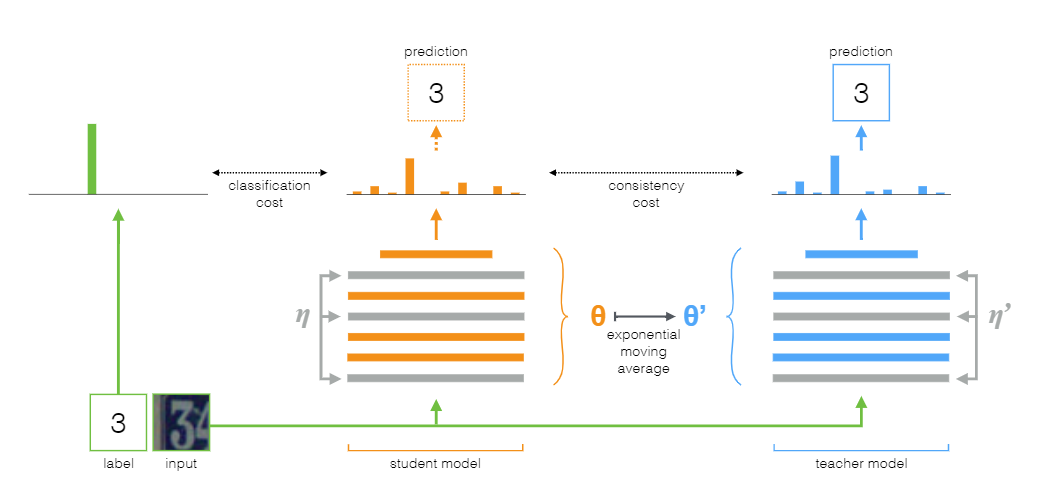
Mean Teacher 则是 Temporal Ensembling 的改进版,Mean Teacher 认为 Temporal Ensembling 对模型的预测 predictions 进行指数滑动平均(Exponentially Moving Average,EMA)并不好,因为 Temporal Ensembling 每个 epoch 才进行一次 EMA,而如果改成对模型权重进行 EMA 的话,每个 step 就可以进行一次,这样岂不是更好。(在 mini-batch 训练模式中,一个 epoch 有很多 steps,一个 step 理解为模型权重的一次更新。batch size 一定时,数据集越大,一个 epoch 含有的 step 数越多。)
Mean Teacher 顾名思义,就是有一个进行了平均(EMA)的 teacher 模型。有了 teacher 自然有 student,这个概念在知识蒸馏和模型压缩领域经常能看见。Mean Teacher 中的 student 模型就是我们正常训练的模型,而 teacher 模型的权重则是由 student 模型的权重进行 EMA 而得,teacher 模型不参与反向传播(back-propagation)过程。
Mean Teacher 需要对每个 unlabelled instance 进行 两次 forward,一次 student,一次 teacher。
Mean Teacher 在原论文中设定,在 ramp-up 阶段设置 EMA decay 为 0.99,而在之后的训练中设为 0.999。这是因为初始时 student 模型训练的很快,而 teacher 需要忘记之前的、不正确的 student 权重;在 student 提升很慢的时候, teacher 记忆越长越好。
References
[1] Laine, S., Aila, T. (2016). Temporal Ensembling for Semi-Supervised Learning arXiv https://arxiv.org/abs/1610.02242
[2] Rasmus, A., Valpola, H., Honkala, M., Berglund, M., Raiko, T. (2015). Semi-Supervised Learning with Ladder Networks arXiv https://arxiv.org/abs/1507.02672
[3] Sajjadi, M., Javanmardi, M., Tasdizen, T. (2016). Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning arXiv https://arxiv.org/abs/1606.04586
[4] Tarvainen, A., Valpola, H. (2017). Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results arXiv https://arxiv.org/abs/1703.01780