Python是一门面向对象的语言,所以在Python中创建一个类和对象是很容易的。接下来了解一下面像对象的一些基本特征。
面向对象技术简介
- 类(class):描述具有相同的属性和方法的对象的集合。定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 类变量:类变量在整个实例中的对象是公用的,对于类的变量定义在类中且在函数体之外。类通常不作为实例变量使用。
- 数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
- 方法重载:如果从父类继承的方法不能满足之类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重载。
- 实例变量:定义在方法中的变量,只作用于当前实例的类。
- 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,在是模拟“是一个(is-a)”关系(例图,Dog是一个Animal)。
- 实例化:创建一个类的实例,类的具体对象。
- 方法:类中定义的函数。
- 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
| 创建类和对象 |
类就是一个模版,模版里可以包含多个函数,函数里实现一些功能

使用class为关键词来创建一个新类,class之后为类的名称并以冒号结尾,
如下实例:
class Foo:
def Bar(self):
print 'Bar'
def Hello(self, name):
print 'i am %s' %name
# 根据类Foo创建对象obj
obj = Foo()
obj.Bar() #执行Bar方法
obj.Hello('wulaoer') #执行Hello方法
- 面向对象:【创建对象】 【通过对象执行方法】
- 函数编程:【执行函数】
面向对象的三大特性是指:封装、继承和多态。
| 一、封装 |
封装就是将内容封装到某个地方,在调用的时候直接调用即可。所以在使用面向对象的封装特性时,需要:
- 将内容封装到某处
- 从某处调用被封装的内容

self 是一个形式参数,当执行 obj1 = Foo('wulaoer', 18 ) 时,self 等于 obj1
当执行 obj2 = Foo('wulaoer1', 19 ) 时,self 等于 obj2
所以,内容其实被封装到了对象obj1和obj2中,每个对象中都有name和age属性,在内存里类似与:

第二步:从某出调用被封装的内容


def __init__(self, name, age):
self.name = name
self.age = age
obj1 = Foo('wulaoer', 18)
print obj1.name # 直接调用obj1对象的name属性
print obj1.age # 直接调用obj1对象的age属性
obj2 = Foo('wulaoer1', 19)
print obj2.name # 直接调用obj2对象的name属性
print obj2.age # 直接调用obj2对象的age属性
def __init__(self, name, age):
self.name = name
self.age = age
def detail(self):
print self.name
print self.age
obj1 = Foo('wulaoer', 18)
obj1.detail() # Python默认会将obj1传给self参数,即:obj1.detail(obj1),所以,此时方法内部的 self = obj1,即:self.name 是 wulaoer ;self.age 是 18
obj2 = Foo('wulaoer1', 73)
obj2.detail() # Python默认会将obj2传给self参数,即:obj1.detail(obj2),所以,此时方法内部的 self = obj2,即:self.name 是 wulaoer1 ; self.age 是 19
综上所述,对于面向对象的封装来说,其实就是使用构造方法将内容封装到 对象 中,然后通过对象直接或者self间接获取被封装的内容。
- 小明,10岁,男,上山去砍柴
- 小明,10岁,男,开车去东北
- 小明,10岁,男,最爱大保健
- 老李,90岁,男,上山去砍柴
- 老李,90岁,男,开车去东北
- 老李,90岁,男,最爱大保健
- 老张...
print "%s,%s岁,%s,上山去砍柴" %(name, age, gender)
def qudongbei(name, age, gender):
print "%s,%s岁,%s,开车去东北" %(name, age, gender)
def dabaojian(name, age, gender):
print "%s,%s岁,%s,最爱大保健" %(name, age, gender)
kanchai('小明', 10, '男')
qudongbei('小明', 10, '男')
dabaojian('小明', 10, '男')
kanchai('老李', 90, '男')
qudongbei('老李', 90, '男')
dabaojian('老李', 90, '男')
def __init__(self, name, age ,gender):
self.name = name
self.age = age
self.gender = gender
def kanchai(self):
print "%s,%s岁,%s,上山去砍柴" %(self.name, self.age, self.gender)
def qudongbei(self):
print "%s,%s岁,%s,开车去东北" %(self.name, self.age, self.gender)
def dabaojian(self):
print "%s,%s岁,%s,最爱大保健" %(self.name, self.age, self.gender)
xiaoming = Foo('小明', 10, '男')
xiaoming.kanchai()
xiaoming.qudongbei()
xiaoming.dabaojian()
laoli = Foo('老李', 90, '男')
laoli.kanchai()
laoli.qudongbei()
laoli.dabaojian()
根据上述可以看出,使用函数式编程,需要在每次执行函数时传入相同的参数,如果参数多的话,有需要复制粘贴了...;而对于面向对象只需要在创建对象时,将所有需要的参数封装到当前对象中,之后使用时在调用,通过self间接去当前对象中取值即可。
1、创建三个游戏人物,分别是:
- 苍井井,女,18,初始战斗力1000
- 东尼木木,男,20,初始战斗力1800
- 波多多,女,19,初始战斗力2500
- 草丛战斗,消耗200战斗力
- 自我修炼,增长100战斗力
- 多人游戏,消耗500战斗力
# ##################### 定义实现功能的类 #####################
class Person:
def __init__(self, na, gen, age, fig):
self.name = na
self.gender = gen
self.age = age
self.fight =fig
def grassland(self):
"""注释:草丛战斗,消耗200战斗力"""
self.fight = self.fight - 200
def practice(self):
"""注释:自我修炼,增长100战斗力"""
self.fight = self.fight + 200
def incest(self):
"""注释:多人游戏,消耗500战斗力"""
self.fight = self.fight - 500
def detail(self):
"""注释:当前对象的详细情况"""
temp = "姓名:%s ; 性别:%s ; 年龄:%s ; 战斗力:%s" % (self.name, self.gender, self.age, self.fight)
print temp
# ##################### 开始游戏 #####################
cang = Person('苍井井', '女', 18, 1000) # 创建苍井井角色
dong = Person('东尼木木', '男', 20, 1800) # 创建东尼木木角色
bo = Person('波多多', '女', 19, 2500) # 创建波多多角色
cang.incest() #苍井空参加一次多人游戏
dong.practice()#东尼木木自我修炼了一次
bo.grassland() #波多多参加一次草丛战斗
#输出当前所有人的详细情况
cang.detail()
dong.detail()
bo.detail()
cang.incest() #苍井空又参加一次多人游戏
dong.incest() #东尼木木也参加了一个多人游戏
bo.practice() #波多多自我修炼了一次
#输出当前所有人的详细情况
cang.detail()
dong.detail()
bo.detail()
| 二、继承 |
面向对象的编程带来的主要好处之一是代码的重用,实现这种重用的方法之一是通过继承机制。继承完全可以理解成类之间的类型和子类型关系。
需要注意的地方:继承语法class派生类名(基类名)://...基类名写作括号里,基本类是在类定义的时候,在元组之中指明的。
在python中继承中的一些特点:
- 1:在继承中积累的构造(__init__()方法) 不会被自动调用,它需要在其派生类的构造中亲自专门调用。
- 2:在调用基类的方法时,需要加上基类的类名前缀,且需要带上self参数变量。区别于在类中调用普通函数时并不需要带上self参数
- 3:python总是首先查找对应类型的方法,如果它不能在派生类中找到对应的方法,它才开始在基类中逐个查找。(先在本类中查找调用的方法,找不到才去基类中找)。
例如:
猫可以:喵喵叫、吃、喝、拉、撒
狗可以:汪汪叫、吃、喝、拉、撒
def 喵喵叫(self):
print '喵喵叫'
def 吃(self):
# do something
def 喝(self):
# do something
def 拉(self):
# do something
def 撒(self):
# do something
class 狗:
def 汪汪叫(self):
print '喵喵叫'
def 吃(self):
# do something
def 喝(self):
# do something
def 拉(self):
# do something
def 撒(self):
# do something
上述代码可以看出,吃、喝、拉、撒是猫和狗都具有的功能,而我们却分别的猫和狗的类中编写了两次。如果使用 继承 的思想,如下实现:
动物:吃、喝、拉、撒
def 吃(self):
# do something
def 喝(self):
# do something
def 拉(self):
# do something
def 撒(self):
# do something
# 在类后面括号中写入另外一个类名,表示当前类继承另外一个类
class 猫(动物):
def 喵喵叫(self):
print '喵喵叫'
# 在类后面括号中写入另外一个类名,表示当前类继承另外一个类
class 狗(动物):
def 汪汪叫(self):
print '喵喵叫'
def eat(self):
print "%s 吃 " %self.name
def drink(self):
print "%s 喝 " %self.name
def shit(self):
print "%s 拉 " %self.name
def pee(self):
print "%s 撒 " %self.name
class Cat(Animal):
def __init__(self, name):
self.name = name
self.breed = '猫'
def cry(self):
print '喵喵叫'
class Dog(Animal):
def __init__(self, name):
self.name = name
self.breed = '狗'
def cry(self):
print '汪汪叫'
# ######### 执行 #########
c1 = Cat('小白家的小黑猫')
c1.eat()
c2 = Cat('小黑的小白猫')
c2.drink()
d1 = Dog('胖子家的小瘦狗')
d1.eat()

用代码来描述阿狗阿毛的功能:
def eat(self):
print "%s 吃 " %self.name
def drink(self):
print "%s 喝 " %self.name
def shit(self):
print "%s 拉 " %self.name
def pee(self):
print "%s 撒 " %self.name
class Cat(Animal):
def __init__(self, name):
self.name = name
self.breed = '猫'
def cry(self):
print '喵喵叫'
class Dog(Animal):
def __init__(self, name):
self.name = name
self.breed = '狗'
def cry(self):
print '汪汪叫'
# ######### 执行 #########
c1 = Cat('小白家的小黑猫')
c1.eat()
c2 = Cat('小黑的小白猫')
c2.drink()
d1 = Dog('胖子家的小瘦狗')
d1.eat()
多继承

- 当类是经典类时,多继承情况下,会按照深度优先方式查找
- 当类是新式类时,多继承情况下,会按照广度优先方式查找


def bar(self):
print 'D.bar'
class C(D):
def bar(self):
print 'C.bar'
class B(D):
def bar(self):
print 'B.bar'
class A(B, C):
def bar(self):
print 'A.bar'
a = A()
# 执行bar方法时
# 首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去D类中找,如果D类中么有,则继续去C类中找,如果还是未找到,则报错
# 所以,查找顺序:A --> B --> D --> C
# 在上述查找bar方法的过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
a.bar()
def bar(self):
print 'D.bar'
class C(D):
def bar(self):
print 'C.bar'
class B(D):
def bar(self):
print 'B.bar'
class A(B, C):
def bar(self):
print 'A.bar'
a = A()
# 执行bar方法时
# 首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去C类中找,如果C类中么有,则继续去D类中找,如果还是未找到,则报错
# 所以,查找顺序:A --> B --> C --> D
# 在上述查找bar方法的过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
a.bar()
| 三、多态 |
Pyhon不支持多态并且也用不到多态,多态的概念是应用于Java和C#这一类强类型语言中,而Python崇尚“鸭子类型”。
pass
class S1(F1):
def show(self):
print 'S1.show'
class S2(F1):
def show(self):
print 'S2.show'
# 由于在Java或C#中定义函数参数时,必须指定参数的类型
# 为了让Func函数既可以执行S1对象的show方法,又可以执行S2对象的show方法,所以,定义了一个S1和S2类的父类
# 而实际传入的参数是:S1对象和S2对象
def Func(F1 obj):
"""Func函数需要接收一个F1类型或者F1子类的类型"""
print obj.show()
s1_obj = S1()
Func(s1_obj) # 在Func函数中传入S1类的对象 s1_obj,执行 S1 的show方法,结果:S1.show
s2_obj = S2()
Func(s2_obj) # 在Func函数中传入Ss类的对象 ss_obj,执行 Ss 的show方法,结果:S2.show
pass
class S1(F1):
def show(self):
print 'S1.show'
class S2(F1):
def show(self):
print 'S2.show'
def Func(obj):
print obj.show()
s1_obj = S1()
Func(s1_obj)
s2_obj = S2()
Func(s2_obj)
| 四、类的成员 |
类的成员分为三大类:字段、方法和属性
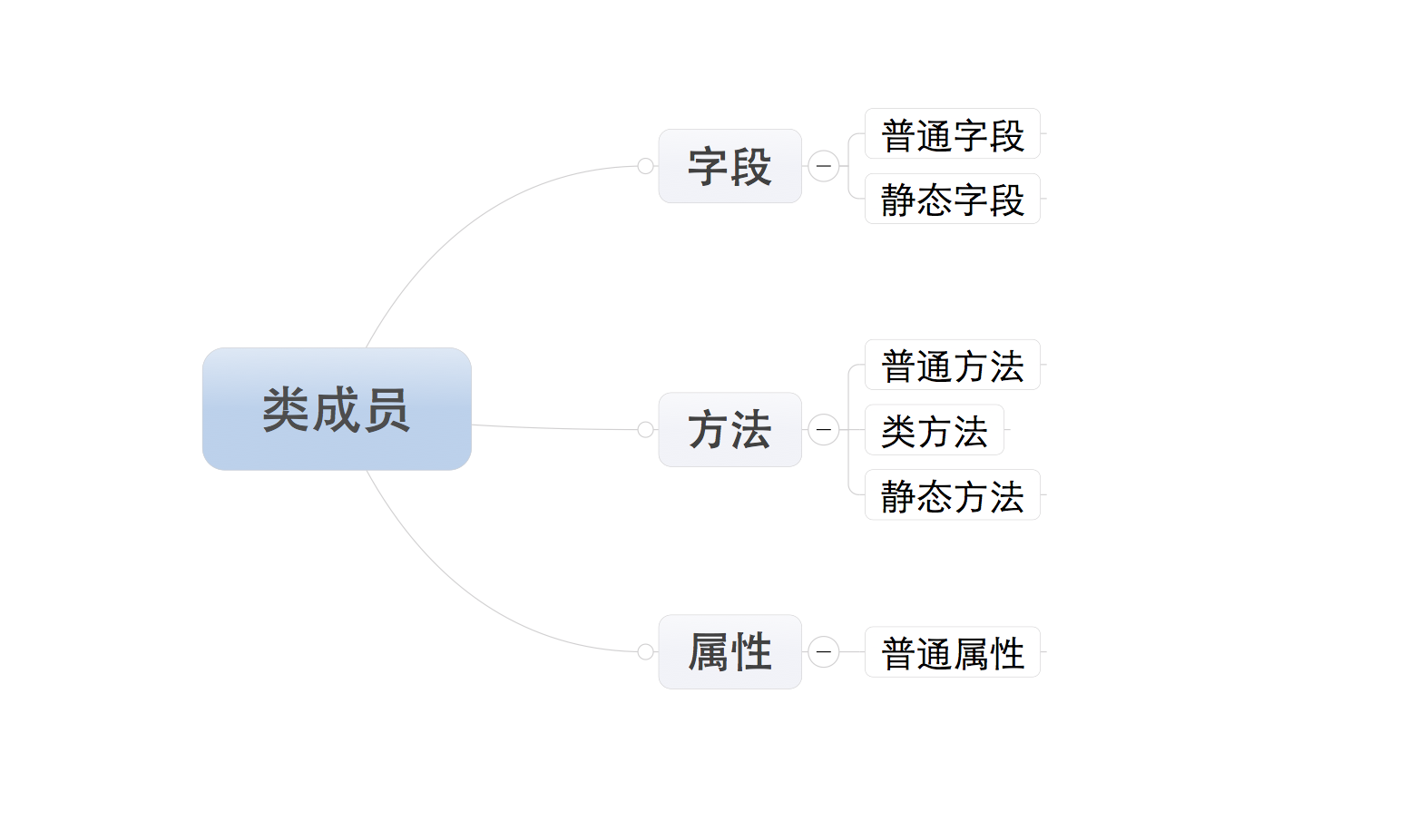
注:所有成员中,只有普通字段的内容保存对象中,即:根据此类创建了多少对象,在内存中就有多少个普通字段。而其他的成员,则都是保存在类中,即:无论对象的多少,在内存中只创建一份。
字段
- 普通字段属于对象
- 静态字段属于类
# 静态字段
country = '中国'
def __init__(self, name):
# 普通字段
self.name = name
# 直接访问普通字段
obj = Province('河北省')
print obj.name
# 直接访问静态字段
Province.country
由上述代码可以看出【普通字段需要通过对象来访问】【静态字段通过类访问】,在使用上可以看出普通字段和静态字段的归属是不同的。其在内容的存储方式类似如下图:

由上图可是:
- 静态字段在内存中只保存一份
- 普通字段在每个对象中都要保存一份
- 普通方法:由对象调用;至少一个self参数;执行普通方法时,自动将调用该方法的对象赋值给self;
- 类方法:由类调用; 至少一个cls参数;执行类方法时,自动将调用该方法的类复制给cls;
- 静态方法:由类调用;无默认参数;
def __init__(self, name):
self.name = name
def ord_func(self):
""" 定义普通方法,至少有一个self参数 """
# print self.name
print '普通方法'
@classmethod
def class_func(cls):
""" 定义类方法,至少有一个cls参数 """
print '类方法'
@staticmethod
def static_func():
""" 定义静态方法 ,无默认参数"""
print '静态方法'
# 调用普通方法
f = Foo()
f.ord_func()
# 调用类方法
Foo.class_func()
# 调用静态方法
Foo.static_func()

- 属性的基本使用
- 属性的两种定义方式
class Foo:
def func(self):
pass
# 定义属性
@property
def prop(self):
pass
# ############### 调用 ###############
foo_obj = Foo()
foo_obj.func()
foo_obj.prop #调用属性

- 定义时,在普通方法的基础上添加 @property 装饰器;
- 定义时,属性仅有一个self参数
- 调用时,无需括号
- 根据用户请求的当前页和总数据条数计算出 m 和 n
- 根据m 和 n 去数据库中请求数据
class Pager:
def __init__(self, current_page):
# 用户当前请求的页码(第一页、第二页...)
self.current_page = current_page
# 每页默认显示10条数据
self.per_items = 10
@property
def start(self):
val = (self.current_page - 1) * self.per_items
return val
@property
def end(self):
val = self.current_page * self.per_items
return val
# ############### 调用 ###############
p = Pager(1)
p.start 就是起始值,即:m
p.end 就是结束值,即:n
- 装饰器 即:在方法上应用装饰器
- 静态字段 即:在类中定义值为property对象的静态字段
class Goods:
@property
def price(self):
return "wulaoer"
# ############### 调用 ###############
obj = Goods()
result = obj.price # 自动执行 @property 修饰的 price 方法,并获取方法的返回值
class Goods(object):
@property
def price(self):
print '@property'
@price.setter
def price(self, value):
print '@price.setter'
@price.deleter
def price(self):
print '@price.deleter'
# ############### 调用 ###############
obj = Goods()
obj.price # 自动执行 @property 修饰的 price 方法,并获取方法的返回值
obj.price = 123 # 自动执行 @price.setter 修饰的 price 方法,并将 123 赋值给方法的参数
del obj.price # 自动执行 @price.deleter 修饰的 price 方法
注:经典类中的属性只有一种访问方式,其对应被 @property 修饰的方法
def __init__(self):
# 原价
self.original_price = 100
# 折扣
self.discount = 0.8
@property
def price(self):
# 实际价格 = 原价 * 折扣
new_price = self.original_price * self.discount
return new_price
@price.setter
def price(self, value):
self.original_price = value
@price.deltter
def price(self, value):
del self.original_price
obj = Goods()
obj.price # 获取商品价格
obj.price = 200 # 修改商品原价
del obj.price # 删除商品原价
def get_bar(self):
return 'wupeiqi'
BAR = property(get_bar)
obj = Foo()
reuslt = obj.BAR # 自动调用get_bar方法,并获取方法的返回值
print reuslt
- 第一个参数是方法名,调用 对象.属性 时自动触发执行方法
- 第二个参数是方法名,调用 对象.属性 = XXX 时自动触发执行方法
- 第三个参数是方法名,调用 del 对象.属性 时自动触发执行方法
- 第四个参数是字符串,调用 对象.属性.__doc__ ,此参数是该属性的描述信息
def get_bar(self):
return 'wulaoer'
# *必须两个参数
def set_bar(self, value):
return return 'set value' + value
def del_bar(self):
return 'wulaoer'
BAR = property(get_bar, set_bar, del_bar, 'description...')
obj = Foo()
obj.BAR # 自动调用第一个参数中定义的方法:get_bar
obj.BAR = "alex" # 自动调用第二个参数中定义的方法:set_bar方法,并将“alex”当作参数传入
del Foo.BAR # 自动调用第三个参数中定义的方法:del_bar方法
obj.BAE.__doc__ # 自动获取第四个参数中设置的值:description...
def __init__(self):
# 原价
self.original_price = 100
# 折扣
self.discount = 0.8
def get_price(self):
# 实际价格 = 原价 * 折扣
new_price = self.original_price * self.discount
return new_price
def set_price(self, value):
self.original_price = value
def del_price(self, value):
del self.original_price
PRICE = property(get_price, set_price, del_price, '价格属性描述...')
obj = Goods()
obj.PRICE # 获取商品价格
obj.PRICE = 200 # 修改商品原价
del obj.PRICE # 删除商品原价
注意:Python WEB框架 Django 的视图中 request.POST 就是使用的静态字段的方式创建的属性
def __init__(self, environ):
script_name = get_script_name(environ)
path_info = get_path_info(environ)
if not path_info:
# Sometimes PATH_INFO exists, but is empty (e.g. accessing
# the SCRIPT_NAME URL without a trailing slash). We really need to
# operate as if they'd requested '/'. Not amazingly nice to force
# the path like this, but should be harmless.
path_info = '/'
self.environ = environ
self.path_info = path_info
self.path = '%s/%s' % (script_name.rstrip('/'), path_info.lstrip('/'))
self.META = environ
self.META['PATH_INFO'] = path_info
self.META['SCRIPT_NAME'] = script_name
self.method = environ['REQUEST_METHOD'].upper()
_, content_params = cgi.parse_header(environ.get('CONTENT_TYPE', ''))
if 'charset' in content_params:
try:
codecs.lookup(content_params['charset'])
except LookupError:
pass
else:
self.encoding = content_params['charset']
self._post_parse_error = False
try:
content_length = int(environ.get('CONTENT_LENGTH'))
except (ValueError, TypeError):
content_length = 0
self._stream = LimitedStream(self.environ['wsgi.input'], content_length)
self._read_started = False
self.resolver_match = None
def _get_scheme(self):
return self.environ.get('wsgi.url_scheme')
def _get_request(self):
warnings.warn('`request.REQUEST` is deprecated, use `request.GET` or '
'`request.POST` instead.', RemovedInDjango19Warning, 2)
if not hasattr(self, '_request'):
self._request = datastructures.MergeDict(self.POST, self.GET)
return self._request
@cached_property
def GET(self):
# The WSGI spec says 'QUERY_STRING' may be absent.
raw_query_string = get_bytes_from_wsgi(self.environ, 'QUERY_STRING', '')
return http.QueryDict(raw_query_string, encoding=self._encoding)
# ############### 看这里看这里 ###############
def _get_post(self):
if not hasattr(self, '_post'):
self._load_post_and_files()
return self._post
# ############### 看这里看这里 ###############
def _set_post(self, post):
self._post = post
@cached_property
def COOKIES(self):
raw_cookie = get_str_from_wsgi(self.environ, 'HTTP_COOKIE', '')
return http.parse_cookie(raw_cookie)
def _get_files(self):
if not hasattr(self, '_files'):
self._load_post_and_files()
return self._files
# ############### 看这里看这里 ###############
POST = property(_get_post, _set_post)
FILES = property(_get_files)
REQUEST = property(_get_request)
| 五、类成员的修饰符 |
- 公有成员,在任何地方都能访问
- 私有成员,只有在类的内部才能方法
def __init__(self):
self.name = '公有字段'
self.__foo = "私有字段"
- 公有静态字段:类可以访问;类内部可以访问;派生类中可以访问
- 私有静态字段:仅类内部可以访问;
name = "公有静态字段"
def func(self):
print C.name
class D(C):
def show(self):
print C.name
C.name # 类访问
obj = C()
obj.func() # 类内部可以访问
obj_son = D()
obj_son.show() # 派生类中可以访问
__name = "公有静态字段"
def func(self):
print C.__name
class D(C):
def show(self):
print C.__name
C.__name # 类访问 ==> 错误
obj = C()
obj.func() # 类内部可以访问 ==> 正确
obj_son = D()
obj_son.show() # 派生类中可以访问 ==> 错误
def __init__(self):
self.foo = "公有字段"
def func(self):
print self.foo # 类内部访问
class D(C):
def show(self):
print self.foo # 派生类中访问
obj = C()
obj.foo # 通过对象访问
obj.func() # 类内部访问
obj_son = D();
obj_son.show() # 派生类中访问
def __init__(self):
self.__foo = "私有字段"
def func(self):
print self.foo # 类内部访问
class D(C):
def show(self):
print self.foo # 派生类中访问
obj = C()
obj.__foo # 通过对象访问 ==> 错误
obj.func() # 类内部访问 ==> 正确
obj_son = D();
obj_son.show() # 派生类中访问 ==> 错误
类的特殊成员
Python的类成员以及成员修饰符,从而了解到类中有字段、方法和属性三大类成员,并且成员名前如果有两个下划线,则表示该成员是私有成员,私有成员只能由类内部调用。无论人或事物往往都有不按套路出牌的情况,Python的类成员也是如此,存在着一些具有特殊含义的成员,详情如下:
1、__doc__
表示类的描述信息
""" 描述类信息,这是用于看片的神奇 """
def func(self):
pass
print Foo.__doc__
#输出:类的描述信息
# -*- coding:utf-8 -*-
class C:
def __init__(self):
self.name = 'wulaoer'
obj = C()
print obj.__module__ # 输出 lib.aa,即:输出模块
print obj.__class__ # 输出 lib.aa.C,即:输出类
def __init__(self, name):
self.name = name
self.age = 18
obj = Foo('wupeiqi') # 自动执行类中的 __init__ 方法
def __del__(self):
pass
5. __call__
def __init__(self):
pass
def __call__(self, *args, **kwargs):
print '__call__'
obj = Foo() # 执行 __init__
obj() # 执行 __call__

country = 'China'
def __init__(self, name, count):
self.name = name
self.count = count
def func(self, *args, **kwargs):
print 'func'
# 获取类的成员,即:静态字段、方法、
print Province.__dict__
# 输出:{'country': 'China', '__module__': '__main__', 'func': <function func at 0x10be30f50>, '__init__': <function __init__ at 0x10be30ed8>, '__doc__': None}
obj1 = Province('HeBei',10000)
print obj1.__dict__
# 获取 对象obj1 的成员
# 输出:{'count': 10000, 'name': 'HeBei'}
obj2 = Province('HeNan', 3888)
print obj2.__dict__
# 获取 对象obj1 的成员
# 输出:{'count': 3888, 'name': 'HeNan'}
def __str__(self):
return 'wulaoer'
obj = Foo()
print obj
# 输出:wulaoer
# -*- coding:utf-8 -*-
class Foo(object):
def __getitem__(self, key):
print '__getitem__',key
def __setitem__(self, key, value):
print '__setitem__',key,value
def __delitem__(self, key):
print '__delitem__',key
obj = Foo()
result = obj['k1'] # 自动触发执行 __getitem__
obj['k2'] = 'wulaoer' # 自动触发执行 __setitem__
del obj['k1'] # 自动触发执行 __delitem__
# -*- coding:utf-8 -*-
class Foo(object):
def __getslice__(self, i, j):
print '__getslice__',i,j
def __setslice__(self, i, j, sequence):
print '__setslice__',i,j
def __delslice__(self, i, j):
print '__delslice__',i,j
obj = Foo()
obj[-1:1] # 自动触发执行 __getslice__
obj[0:1] = [11,22,33,44] # 自动触发执行 __setslice__
del obj[0:2] # 自动触发执行 __delslice__
pass
obj = Foo()
for i in obj:
print i
# 报错:TypeError: 'Foo' object is not iterable
# -*- coding:utf-8 -*-
class Foo(object):
def __iter__(self):
pass
obj = Foo()
for i in obj:
print i
# 报错:TypeError: iter() returned non-iterator of type 'NoneType'
# -*- coding:utf-8 -*-
class Foo(object):
def __init__(self, sq):
self.sq = sq
def __iter__(self):
return iter(self.sq)
obj = Foo([11,22,33,44])
for i in obj:
print i
以上步骤可以看出,for循环迭代的其实是 iter([11,22,33,44]) ,所以执行流程可以变更为:
# -*- coding:utf-8 -*-
obj = iter([11,22,33,44])
for i in obj:
print i
# -*- coding:utf-8 -*-
obj = iter([11,22,33,44])
while True:
val = obj.next()
print val
def __init__(self):
pass
obj = Foo() # obj是通过Foo类实例化的对象
print type(Foo) # 输出:<type 'type'> 表示,Foo类对象由 type 类创建
所以,obj对象是Foo类的一个实例,Foo类对象是 type 类的一个实例,即:Foo类对象 是通过type类的构造方法创建。
a). 普通方式
def func(self):
print 'hello wulaoer'
b).特殊方式(type类的构造函数)
print 'hello wulaoer'
Foo = type('Foo',(object,), {'func': func})
#type第一个参数:类名
#type第二个参数:当前类的基类
#type第三个参数:类的成员
| 六、其他相关 |
pass
obj = Foo()
isinstance(obj, Foo)
pass
class Bar(Foo):
pass
issubclass(Bar, Foo)
pass
except Exception,ex:
pass
需求:将用户输入的两个数字相加
num1 = raw_input('num1:')
num2 = raw_input('num2:')
try:
num1 = int(num1)
num2 = int(num2)
result = num1 + num2
except Exception, e:
print '出现异常,信息如下:'
print e
IOError 输入/输出异常;基本上是无法打开文件
ImportError 无法引入模块或包;基本上是路径问题或名称错误
IndentationError 语法错误(的子类) ;代码没有正确对齐
IndexError 下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5]
KeyError 试图访问字典里不存在的键
KeyboardInterrupt Ctrl+C被按下
NameError 使用一个还未被赋予对象的变量
SyntaxError Python代码非法,代码不能编译(个人认为这是语法错误,写错了)
TypeError 传入对象类型与要求的不符合
UnboundLocalError 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量,
导致你以为正在访问它
ValueError 传入一个调用者不期望的值,即使值的类型是正确的
AssertionError
AttributeError
BaseException
BufferError
BytesWarning
DeprecationWarning
EnvironmentError
EOFError
Exception
FloatingPointError
FutureWarning
GeneratorExit
ImportError
ImportWarning
IndentationError
IndexError
IOError
KeyboardInterrupt
KeyError
LookupError
MemoryError
NameError
NotImplementedError
OSError
OverflowError
PendingDeprecationWarning
ReferenceError
RuntimeError
RuntimeWarning
StandardError
StopIteration
SyntaxError
SyntaxWarning
SystemError
SystemExit
TabError
TypeError
UnboundLocalError
UnicodeDecodeError
UnicodeEncodeError
UnicodeError
UnicodeTranslateError
UnicodeWarning
UserWarning
ValueError
Warning
ZeroDivisionError
try:
dic[10]
except IndexError, e:
print e
try:
dic['k20']
except KeyError, e:
print e
try:
int(s1)
except ValueError, e:
print e
s1 = 'hello'
try:
int(s1)
except IndexError,e:
print e
try:
int(s1)
except IndexError,e:
print e
except KeyError,e:
print e
except ValueError,e:
print e
try:
int(s1)
except Exception,e:
print e
try:
int(s1)
except KeyError,e:
print '键错误'
except IndexError,e:
print '索引错误'
except Exception, e:
print '错误'
# 主代码块
pass
except KeyError,e:
# 异常时,执行该块
pass
else:
# 主代码块执行完,执行该块
pass
finally:
# 无论异常与否,最终执行该块
pass
raise Exception('错误了。。。')
except Exception,e:
print e
def __init__(self, msg):
self.message = msg
def __str__(self):
return self.message
try:
raise WupeiqiException('我的异常')
except WupeiqiException,e:
print e
3.6、断言
assert 1 == 1
assert 1 == 2
4、反射
你也可以使用以下函数的方式来访问属性:
- getattr(obj, name[, default]):访问对象的属性。
- hasattr(obj,name):检查是否存在一个属性。
- setattr(obj,name,value):设置一个属性。如果属性不存在,会创建一个新属性。
- delattr(obj,name):删除属性。
def __init__(self):
self.name = 'wulaoer'
def func(self):
return 'func'
obj = Foo()
# #### 检查是否含有成员 ####
hasattr(obj, 'name')
hasattr(obj, 'func')
# #### 获取成员 ####
getattr(obj, 'name')
getattr(obj, 'func')
# #### 设置成员 ####
setattr(obj, 'age', 18)
setattr(obj, 'show', lambda num: num + 1)
# #### 删除成员 ####
delattr(obj, 'name')
delattr(obj, 'func')
def __init__(self):
self.name = 'alex'
def func(self):
return 'func'
obj = Foo()
# 访问字段
obj.name
# 执行方法
obj.func()

def __init__(self):
self.name = 'alex'
# 不允许使用 obj.name
obj = Foo()
def __init__(self):
self.name = 'alex'
def func(self):
return 'func'
# 不允许使用 obj.name
obj = Foo()
print obj.__dict__['name']
def __init__(self):
self.name = 'alex'
def func(self):
return 'func'
# 不允许使用 obj.name
obj = Foo()
print getattr(obj, 'name')
- obj.name
- obj.__dict__['name']
- getattr(obj, 'name')
#coding:utf-8
from wsgiref.simple_server import make_server
class Handler(object):
def index(self):
return 'index'
def news(self):
return 'news'
def RunServer(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
url = environ['PATH_INFO']
temp = url.split('/')[1]
obj = Handler()
is_exist = hasattr(obj, temp)
if is_exist:
func = getattr(obj, temp)
ret = func()
return ret
else:
return '404 not found'
if __name__ == '__main__':
httpd = make_server('', 8001, RunServer)
print "Serving HTTP on port 8000..."
httpd.serve_forever()
staticField = "old boy"
def __init__(self):
self.name = 'wulaoer'
def func(self):
return 'func'
@staticmethod
def bar():
return 'bar'
print getattr(Foo, 'staticField')
print getattr(Foo, 'func')
print getattr(Foo, 'bar')
# -*- coding:utf-8 -*-
def dev():
return 'dev'
2 # -*- coding:utf-8 -*-
3
4 """
5 程序目录:
6 home.py
7 index.py
8
9 当前文件:
10 index.py
11 """
12
13
14 import home as obj
15
16 #obj.dev()
17
18 func = getattr(obj, 'dev')
19 func()
设计模式
一、单例模式
python的面向对象由两个非常重要的两个“东西”组成:类、实例
面向对象场景一:
如:创建三个游戏人物,分别是:
- 苍井井,女,18,初始战斗力1000
- 东尼木木,男,20,初始战斗力1800
- 波多多,女,19,初始战斗力2500
class Person:
def __init__(self, na, gen, age, fig):
self.name = na
self.gender = gen
self.age = age
self.fight =fig
def grassland(self):
"""注释:草丛战斗,消耗200战斗力"""
self.fight = self.fight - 200
# ##################### 创建实例 #####################
cang = Person('苍井井', '女', 18, 1000) # 创建苍井井角色
dong = Person('东尼木木', '男', 20, 1800) # 创建东尼木木角色
bo = Person('波多多', '女', 19, 2500) # 创建波多多角色
- 增
- 删
- 改
- 查
class DbHelper(object):
def __init__(self):
self.hostname = '1.1.1.1'
self.port = 3306
self.password = 'pwd'
self.username = 'root'
def fetch(self):
# 连接数据库
# 拼接sql语句
# 操作
pass
def create(self):
# 连接数据库
# 拼接sql语句
# 操作
pass
def remove(self):
# 连接数据库
# 拼接sql语句
# 操作
pass
def modify(self):
# 连接数据库
# 拼接sql语句
# 操作
pass
# #### 操作类 ####
db = DbHelper()
db.create()
#coding:utf-8
from wsgiref.simple_server import make_server
class DbHelper(object):
def __init__(self):
self.hostname = '1.1.1.1'
self.port = 3306
self.password = 'pwd'
self.username = 'root'
def fetch(self):
# 连接数据库
# 拼接sql语句
# 操作
return 'fetch'
def create(self):
# 连接数据库
# 拼接sql语句
# 操作
return 'create'
def remove(self):
# 连接数据库
# 拼接sql语句
# 操作
return 'remove'
def modify(self):
# 连接数据库
# 拼接sql语句
# 操作
return 'modify'
class Handler(object):
def index(self):
# 创建对象
db = DbHelper()
db.fetch()
return 'index'
def news(self):
return 'news'
def RunServer(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
url = environ['PATH_INFO']
temp = url.split('/')[1]
obj = Handler()
is_exist = hasattr(obj, temp)
if is_exist:
func = getattr(obj, temp)
ret = func()
return ret
else:
return '404 not found'
if __name__ == '__main__':
httpd = make_server('', 8001, RunServer)
print "Serving HTTP on port 8001..."
httpd.serve_forever()
class Foo(object):
__instance = None
@staticmethod
def singleton():
if Foo.__instance:
return Foo.__instance
else:
Foo.__instance = Foo()
return Foo.__instance
# ########### 获取实例 ###########
obj = Foo.singleton()
对于Python单例模式,创建对象时不能再直接使用:obj = Foo(),而应该调用特殊的方法:obj = Foo.singleton() 。
#coding:utf-8
from wsgiref.simple_server import make_server
# ########### 单例类定义 ###########
class DbHelper(object):
__instance = None
def __init__(self):
self.hostname = '1.1.1.1'
self.port = 3306
self.password = 'pwd'
self.username = 'root'
@staticmethod
def singleton():
if DbHelper.__instance:
return DbHelper.__instance
else:
DbHelper.__instance = DbHelper()
return DbHelper.__instance
def fetch(self):
# 连接数据库
# 拼接sql语句
# 操作
pass
def create(self):
# 连接数据库
# 拼接sql语句
# 操作
pass
def remove(self):
# 连接数据库
# 拼接sql语句
# 操作
pass
def modify(self):
# 连接数据库
# 拼接sql语句
# 操作
pass
class Handler(object):
def index(self):
obj = DbHelper.singleton()
print id(single)
obj.create()
return 'index'
def news(self):
return 'news'
def RunServer(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
url = environ['PATH_INFO']
temp = url.split('/')[1]
obj = Handler()
is_exist = hasattr(obj, temp)
if is_exist:
func = getattr(obj, temp)
ret = func()
return ret
else:
return '404 not found'
if __name__ == '__main__':
httpd = make_server('', 8001, RunServer)
print "Serving HTTP on port 8001..."
httpd.serve_forever()
总结:单利模式存在的目的是保证当前内存中仅存在单个实例,避免内存浪费!!!
| Python对象销毁(垃圾回收) |
python和java语言一样,都引用了计数这一简单技术来追踪内存中的对象。
在python内部记录着所有使用中的对象各有多少引用。
一个内部跟踪变量,称为一个引用计数器
当对象被创建时,就创建了一个引用计数,当这个对象不再需要时,也就是说,这个对象的引用计数变为0时,它被垃圾回收。但是回收不是“立即”的,有解释器在适当的时机,将垃圾对象占用的内存空间回收。
b = a # 增加引用, <40> 的计数
c = [b] # 增加引用. <40> 的计数
del a # 减少引用 <40> 的计数
b = 100 # 减少引用 <40> 的计数
c[0] = -1 # 减少引用 <40> 的计数
垃圾回收机制不仅针对引用计数为0的对象,同样也可以处理循环引用的情况。循环引用指的是,两个对象相互引用,但是没有其他变量引用他们。这种情况下,仅使用引用计数是不够的。python的垃圾收集器实际上是一个引用计数器和一个循环垃圾收集器。作为引用计数的补充,垃圾收集器也会留心被分配的总量很大(及未通过引用计数销毁的那些)的对象。这种情况下,解释器会暂停下来,试图清理所有未引用的循环。
实例
析构函数__del__ , __del__在对象消逝的时候被调用,当对象不再被使用时,__del__方法运行:
class Point:
def __init( self, x=0, y=0):
self.x = x
self.y = y
def __del__(self):
class_name = self.__class__.__name__
print class_name, "destroyed"
pt1 = Point()
pt2 = pt1
pt3 = pt1
print id(pt1), id(pt2), id(pt3) # 打印对象的id
del pt1
del pt2
del pt3
<pre>
<p>以上实例运行结果如下:</p>
<pre>
3083401324 3083401324 3083401324
Point destroyed
注意:通常你需要在单独的文件中定义一个类,
重载方法如果你的父类方法的功能不能满足你的需求,你可以在子类重载你父类的方法:
实例:
class Parent: # 定义父类
def myMethod(self):
print 'Calling parent method'
class Child(Parent): # 定义子类
def myMethod(self):
print 'Calling child method'
c = Child() # 子类实例
c.myMethod() # 子类调用重载方法
执行以上代码输出结果如下:
基础重载方法
下表列出了一些通用的功能,你可以在自己的类重写:

运算符重载
python同样支持运算符重载,实例如下:
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self,other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2,10)
v2 = Vector(5,-2)
print v1 + v2
以上代码执行结果如下:
隐藏数据
在python中实现数据隐藏很简单,不需要在前面加什么关键字,只要把类变量名或成员函数前面加两个下划线即可实现数据隐藏的功能,这样,对于类的实例来说,其变量名和成员函数是不能使用的,对于基类的继承来说,也是隐藏的,这样,其继承类可以定义其一模一样的变量名或成员函数名,而不会引起命名冲突。实例:
class JustCounter:
__secretCount = 0
def count(self):
self.__secretCount += 1
print self.__secretCount
counter = JustCounter()
counter.count()
counter.count()
print counter.__secretCount
Python通过改变名称来包含类名:
2
Traceback (most recent call last):
File "test.py", line 12, in <module>
print counter.__secretCount
AttributeError: JustCounter instance has no attribute '__secretCount'
Python不允许实例化的类访问隐藏数据,但你可以使用object._className__attrName访问属性,将如下代码替换以上代码的最后一行代码:
print counter._JustCounter__secretCount
执行以上代码,执行结果如下:
2
2
总结:
- 面向对象是一种编程方式,此编程方式的实现是基于对 类 和 对象 的使用
- 类 是一个模板,模板中包装了多个“函数”供使用
- 对象,根据模板创建的实例(即:对象),实例用于调用被包装在类中的函数
- 面向对象三大特性:封装、继承和多态
def __init__(self, host, user, pwd):
self.host = host
self.user = user
self.pwd = pwd
def 增(self):
# 使用主机名、用户名、密码(self.host 、self.user 、self.pwd)打开数据库连接
# do something
# 关闭数据库连接
def 删(self):
# 使用主机名、用户名、密码(self.host 、self.user 、self.pwd)打开数据库连接
# do something
# 关闭数据库连接
def 改(self):
# 使用主机名、用户名、密码(self.host 、self.user 、self.pwd)打开数据库连接
# do something
# 关闭数据库连接
def 查(self):
# 使用主机名、用户名、密码(self.host 、self.user 、self.pwd)打开数据库连接
# do something
# 关闭数据库连接# do something
def __init__(self, name ,age ,blood_type):
self.name = name
self.age = age
self.blood_type = blood_type
def detail(self):
temp = "i am %s, age %s , blood type %s " % (self.name, self.age, self.blood_type)
print temp
zhangsan = Person('张三', 18, 'A')
lisi = Person('李四', 73, 'AB')
yangwu = Person('杨五', 84, 'A')
