范式虽然在工作中没有很明确的用到,但是作为一个搞数据的人,时时刻刻在用着范式,虽然心里懂,但是每次别人问,都感觉说不出来的样子,为了加强进一步的理解,在这里简单的记录一下。
有一句话概括了3范式,比较容易理解,每一个非健值属性必须依赖于健,依赖于整个健而不是健的一部分,并且不依赖于其它非健值属性。
一、1NF
1NF简单点就是原子性,列不可再分,没有重复的列也没有重复的行,
基本上主要有主键的表都满足第一范式。
1NF的特点
1、列不可再分

这样就不符合。
2、确保每一列表达的是同一类型的含义,数据类型一致,
比如学生成绩分别填写(99,优) 既有数字,又有汉字的。
3、去掉多值属性,拆分成多列,和1差不多。
4、必须去掉重复组。
5、必须得确定主键
二、2NF
1、2NF首先满足1NF
2、非主属性必须依赖于键的全部,如果只依赖于主键的一部分,则需要移出创建新表。
所以第二范式一般是联合主键。

比如这个例子,学号和课程为联合主键,这个呢符合第一范式,但是呢,不符合第二范式,因为"学生姓名"只依赖于主键中的"学号",
而不依赖于课程,所以不符合第二范式,非主属性必须依赖于主键的全部,这种情况下需要进行拆分,如下图所示


三、3NF
3NF必须满足2NF
非主属性只依赖于属性,不依赖于其它非主属性
如果非主属性依赖于其它非主属性,需要移出创建新表。
看例子吧
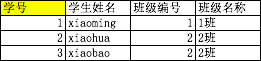
学号为主键,符合第二范式,非主属性都依赖于属性,但是不符合第3范式
因为班级名称依赖于班级编号,所以需要进行拆分,如下图


第3范式其实就是主外键的关系了。
基本三范式都是基于主键的,一般在工作中就基本就够用了,关系型数据库设计基本需要遵循3范式,
但是数据仓库中,有时可以满足2范式就行了,虽然遵循2范式,但是也要先满足2范式,然后在逆归化到
2范式。