如何在TVM上集成Codegen(上)
许多常用的深度学习内核,或者提供DNNL或TensorRT等框架和图形引擎,让用户以某种方式描述他们的模型,从而获得高性能。此外,新兴的深度学习加速器也有自己的编译器、内核库或runtime框架。
然而,当用户试图在一个新的内核库或设备上工作时,必须学习一个新的编程接口。因此,对于统一编程接口的需求变得越来越重要,以便让所有用户和硬件后端提供商站在同一个页面上。
为了与广泛使用的深度学习框架共享编程接口,许多硬件设备提供商尝试将其设备后端集成到TensorFlow。由于TensorFlow没有为新的后端提供正式的后端接口,因此必须对TensorFlow进行注册,这涉及到许多源文件的更改,并使将来的维护变得困难。
本文将展示作为一个硬件后端提供商,如何轻松地利用自带的Codegen(BYOC)框架将硬件设备的内核库/编译器/框架集成到TVM。利用BYOC框架最重要的优势是,设备的所有相关源文件都是自包含的,因此设备的codegen/runtime可以嵌入到TVM代码库。这意味着
1)带有codegen的TVM代码库将与上游兼容
2)TVM用户可以根据需要选择启用codegen/runtime。
在本文的其余部分中,首先说明一个场景,可能需要使用BYOC实现TVM,然后概述BYOC编译和runtime流。最后,以Intel DNNL(又称MKL-DNN,OneDNN)为例,逐步说明如何将供应商库或执行引擎集成到TVM与BYOC。
Bring an ASIC Accelerator to TVM
先做一个场景来说明为什么要将加速器引入TVM,以及可以从BYOC框架中获得哪些特性。如果不确定案例是否适合BYOC,欢迎在tvm.ai里讨论。
想象一下,刚刚制作了一个边缘设备平台,上面有一个ARM CPU和一个很棒的加速器,在常见的图像分类模型中取得了惊人的性能。换句话说,加速器在Conv2D、ReLU、GEMM和其他广泛使用的CNN运营商上表现良好。
不幸的是,目标检测模型也越来越流行,客户需要在平台上同时运行图像分类和目标检测模型。虽然加速器能够执行目标检测模型中的几乎所有算子,但缺少一个算子(例如,非最大抑制,NMS)。
Let TVM execute unsupported operators
由于TVM为不同的后端提供了多个代码源,所以开源社区很容易在短时间内在CPU或GPU上实现新的操作程序。理想情况下,如果将加速器的编译流与BYOC集成到TVM,TVM将执行中继图分区,将图的一部分卸载到加速器上,同时将其它部分保留在TVM上。因此,可以宣称平台能够运行所有模型,而不必担心新的算子。
Customize graph-level optimization
ASIC加速器必须有自己的编译流。通常,可能是以下情况之一:
生成一个图形表示并将其输入图形引擎:
可能有自己的图形引擎,能够在加速器上执行图形(或神经网络模型)。例如,Intel DNNL和NVIDIA TensorRT都使用引擎运行整个图形或模型,因此它们能够
1)减少运算符之间的内存事务;
2)使用运算符融合优化图形执行。
为了实现上述两个优化,可能需要在编译期间处理该图。例如,Conv2D和bias addition在TVM中是两个独立的算子,但它们可能是加速器上的一个算子(具有bias addition功能的Conv2D)。在这种情况下,可能希望通过将conv2d-add graph模式替换为带有“bias”节点的“uconv2d”来优化图形。
如果编译流程属于这种情况,那么建议阅读本文的其余部分,但跳过将DNNL带到TVM:C源代码生成。
生成汇编代码并将其编译为可执行的二进制文件:
如果平台不像前面的例子那样有一个端到端的执行框架,那么可能有一个编译器来用ISA的汇编代码编译程序。为了向编译器提供汇编代码,需要一个codegen来从中继图生成和优化汇编代码。
如果编译流程属于这种情况,那么建议阅读本文的所有其余部分,但跳过将DNNL到TVM:JSON Codegen/Runtime。
How BYOC Works
然后简单地解释一下BYOC框架是如何工作的。有关底层框架组件及其实现的详细说明,请参阅开发人员文档。简而言之,给定图1中的中继图,BYOC框架执行以下步骤:
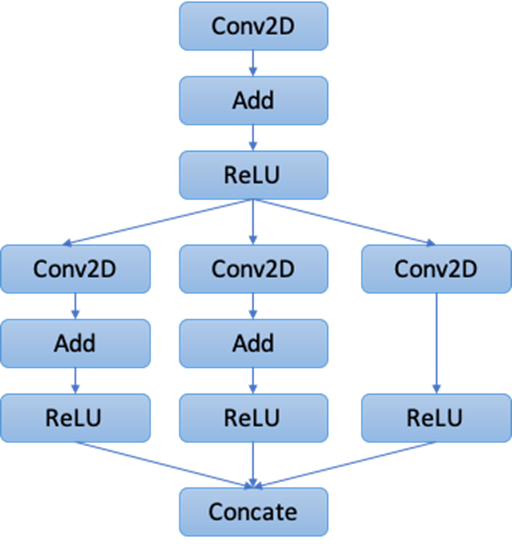
Figure 1: The Original Relay Graph.
- Graph Annotation
以用户提供的中继图为例,第一步是在图中注释可能被卸载到加速器的节点。需要遵循Bring DNNL to TVM:
来实现受支持运算符的白名单,或者自定义复合运算符的图形模式列表。图2显示了一个示例注释结果。
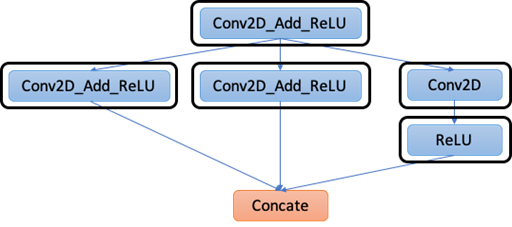
Figure 2: The Graph with Annotations.
- Graph Transformation
第二步是基于注释对图形进行变换和优化。具体来说,BYOC执行以下转换。
2.1:合并编译器区域:
如图2所示,图中现在有许多“区域”可以卸载到加速器上,但实际上可以合并其中一些区域,以减少数据传输和内核启动开销。因此,步骤2.1使用贪婪算法合并尽可能多的这些区域,同时保证功能的正确性。结果如图3所示。
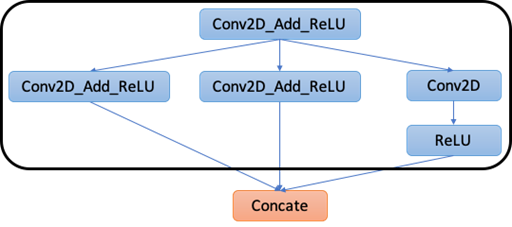
Figure 3: After Merging Compiler Regions.
2.2: Partition Graph:
对于上一步中的每个区域,创建一个带有属性编译器的中继函数,以指示该中继函数应该完全卸载到加速器上,如图4所示。
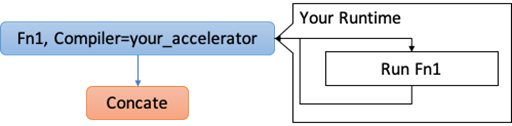
Figure 4: After Graph Partitioning.
3. Code Generation
现在我们知道应该卸载中继图的哪个部分。在这一步中,按顺序将每个带有Compiler=your_accelerator加速器的中继函数发送到codegen。
codegen应该将Relay函数编译成与编译流相匹配的形式。可以是C源代码或任何文本格式。
最后,所有编译的函数将与其他未卸载的中继函数一起通过TVM export_library Python API序列化到一个single .so文件中。换句话说,用户在运行此流后将只获得一个one .so文件。
4. Runtime
可能还需要实现一个runtime来初始化图形引擎(如果适用)并执行编译后的函数。在推理过程中,当TVM runtime遇到图4中相应的函数调用时,TVM runtime(即图runtime或VM)将利用runtime来调用卸载的函数。runtime负责使用给定的输入张量数组启动编译函数,并将结果填充到输出张量数组中。
在本文的其余部分中,以DNNL为例演示如何使用BYOC框架实现上述工作流。本文中引用的所有代码和行号都基于TVM存储库的主分支提交8a0249c。
Bring DNNL to TVM: Annotation Rules
BYOC框架提供了两种方法来描述支持的算子和模式。可以同时使用。本文以DNNL为例来说明如何使用。这里提供了完整的实现。将codegen的注释规则放在
python/tvm/relay/op/contrib/your_codegen_name.py.
Rules for single operators
可以使用BYOC API直观地指定加速器支持哪些中继运算符。例如,使用下面的代码片段构建一个规则,说明DNNL codegen支持Conv2D:
@tvm.ir.register_op_attr("nn.conv2d", "target.dnnl")
def _dnnl_conv2d_wrapper(attrs, args):
return True
这将注册一个新属性target.dnnl接力nn.conv2d算子。通过这种方式,BYOC注释可以调用target.dnnl()以检查DNNL codegen中是否支持它。
另一方面,为每个算子编写上面的代码片段可能很乏味。对于DNNL实现,实现了一个helper函数,即_register_external_op_helper,使生活更轻松:
def _register_external_op_helper(op_name, supported=True):
@tvm.ir.register_op_attr(op_name, "target.dnnl")
def _func_wrapper(attrs, args):
return supported
return _func_wrapper
_register_external_op_helper("nn.batch_norm")
_register_external_op_helper("nn.conv2d")
_register_external_op_helper("nn.dense")
_register_external_op_helper("nn.relu")
_register_external_op_helper("add")
_register_external_op_helper("subtract")
_register_external_op_helper("multiply")
在上面的示例中,指定了DNNL codegen支持的运算符列表。
Rules for graph patterns
加速器或编译器可能已将某些模式(例如Conv2D+add+ReLU)优化为单个指令或API。在这种情况下,可以指定从图形模式到指令/API的映射。对于DNNL来说,它的Conv2D API已经包含了bias addition,并且允许附加下一个ReLU,因此可以将DNNL称为以下代码片段(完整的实现可以在这里找到):
DNNLConv2d(const bool has_bias = false, const bool has_relu = false) {
// ... skip ...
auto conv_desc = dnnl::convolution_forward::desc(
dnnl::prop_kind::forward_inference,
dnnl::algorithm::convolution_direct,
conv_src_md, conv_weights_md, conv_bias_md, conv_dst_md,
strides_dims, padding_dims_l, padding_dims_r);
// Attach ReLU
dnnl::primitive_attr attr;
if (has_relu) {
dnnl::post_ops ops;
ops.append_eltwise(1.f, dnnl::algorithm::eltwise_relu, 0.f, 0.f);
attr.set_post_ops(ops);
}
auto conv2d_prim_desc = dnnl::convolution_forward::primitive_desc(
conv_desc, attr, engine_);
// ... skip ...
在本例中,除了单个conv2d,希望将图形模式conv2d+relu映射到DNNLConv2d(false,true),并将conv2d+add+relu映射到DNNLConv2d(true,true)。可以用下面的代码片段来实现:
def make_pattern(with_bias=True):
data = wildcard()
weight = wildcard()
bias = wildcard()
conv = is_op('nn.conv2d')(data, weight)
if with_bias:
conv_out = is_op('add')(conv, bias)
else:
conv_out = conv
return is_op('nn.relu')(conv_out)
@register_pattern_table("dnnl")
def pattern_table():
conv2d_bias_relu_pat = ("dnnl.conv2d_bias_relu", make_pattern(with_bias=True))
conv2d_relu_pat = ("dnnl.conv2d_relu", make_pattern(with_bias=False))
dnnl_patterns = [conv2d_bias_relu_pat, conv2d_relu_pat]
return dnnl_patterns
在DNNL示例中,实现了两个具有不同名称的模式,以便可以在codegen中轻松地识别它们。注意,这些模式是用中继模式语言实现的。可以学习如何编写自己的模式。
通过模式表,可以使用一个中继传递来执行
%1 = nn.conv2d(%data, %weight, ...)
%2 = add(%1, %bias)
%3 = nn.relu(%2)
to
%1 = fn(%input1, %input2, %input3,
Composite="dnnl.conv2d_bias_relu",
PartitionedFromPattern="nn.conv2d_add_nn.relu_") {
%1 = nn.conv2d(%input1, %input2, ...)
%2 = add(%1, %input3)
nn.relu(%2)
}
%2 = %1(%data, %weight, %bias)
hus,DNNL codegen可以获得模式名conv2d_bias_relu,并将%1映射到DNNLConv2d(true,true)。
在复合函数中还有一个名为“PartitionedFromPattern”的属性。如果模式包含通配符运算符,这可能会很有帮助。例如,可能有一个模式表("conv2d_with_something", conv2d -> *):
def make_pattern(with_bias=True):
data = wildcard()
weight = wildcard()
conv = is_op('nn.conv2d')(data, weight)
return wildcard()(conv)
In this case, you will get a composite function with Composite=conv2d_with_something, but you have no idea about what graph it actually matched. That’s where PartitionedFromPattern comes into play. You can know that if the matched graph is conv2d -> add or conv2d -> relu by looking at PartitionedFromPattern to see if it is nn.conv2d_add_ or nn.conv2d_nn.relu_.
Bring DNNL to TVM: Relay Graph Transformation
使用上一步中的注释规则,现在可以应用BYOC中继传递列表,将中继图从图1转换为图4:
mod=create_relay_module_from_model()# Output: Figure 1
mod=transform.MergeComposite(pattern_table)(mod)
mod=transform.AnnotateTarget(["dnnl"])(mod)# Output: Figure 2
mod=transform.MergeCompilerRegions()(mod)# Output: Figure 3
mod=transform.PartitionGraph()(mod)# Output: Figure 4
As can be seen, each Relay pass can be mapped to a step we have introduced in How BYOC Works.