《Data Structures and Algorithm Analysis in C》学习与刷题笔记
为什么要学习DSAAC?
某个月黑风高的夜晚,下班的我走在黯淡无光、冷清无人的冲之大道上,同时心里冒出一个强烈的想法:我不要再过这种无休止地加班、整天干着繁重琐碎的事情的生活了!我要回去读书!我要考研!在接下来的一个多月中,我不断在考研和换工作之间徘徊,最后我得出一个结论:我不知道读研好还是换工作好,但我知道把自己感兴趣的知识学好总不会错。数据结构是我们专业大二下学期的一门选修课,但当时正值我迷茫和逃课的高峰期,这门课也被我翘掉了,作业也没按时交。现在经过面试和工作的洗礼,我终于意识到数据结构的重要性,同时我现在也很有兴趣去了解一下红黑树等数据结构的原理。因此,我翻出去年入职时购买的但从未翻过的《Data Structures And Algorithm Analysis in C》,决定系统学习一遍数据结构。(出来混的,迟早要还......)
为什么要刷DSAAC的习题?
在看DSAAC这本书时,我给自己订了一个小目标:刷完DSAAC的所有习题。为什么要刷习题呢?因为做习题能够加深对书中知识的理解,而且这些习题90%以上是编程题,正好可以锻炼自己的代码能力。还有一个原因是受《我是一只IT小小鸟》中的一篇文章《掉进读书的兔子洞》的影响。文章作者徐宥提出他的三个学习理念:
- 什么东西都可以自学
- 慢即是快,笨笨地做一遍题是学习的捷径
- 知识就是力量,而读书学知识能够消除蒙昧,掌握改变世界的力量,所以是一件快乐的事情
而他确实也严格按照他的学习理念去做,因此他一字不漏地敲完不少书的程序,以及一题不漏地做完不少教材的习题。当他总结毕业时面试、考研和发paper的成功经验时,说了一句话:
总的来说,面试也好,考研也好,写论文也好,之所以能够比较顺利,我觉得都是大一大二一个键一个键敲出来的,也是大三一本书一本书读出来的。
我很认同徐宥的学习方法,因此打算认认真真地做一遍DSAAC的题,以扎实数据结构基础。
刷题代码的存放路径
这是我刷题代码的github地址:https://github.com/whl1729/dsaac。
读书笔记
1. 最大子数组问题
书中给出了最大子数组问题的四种解法,时间复杂度分别是O(N^3), O(N^2), O(NlogN)和O(N)。
- O(N^3)解法。穷尽法。用下标组合(i, j)来表示第i到j个元素组成的子数组,遍历所有的子数组(i,j),并计算出其元素之和,对比得最大值。
- O(N2)解法。思路仍然是穷尽法。但对O(N3)解法进行优化。O(N^3)解法包含太多重复性的工作,比如在计算子数组元素之和时,计算(i, j+1)时会重新计算一遍(i, j),O(N^2)算法相当于把(i, j)的计算结果记录下来,计算(i, j+1)时就可以使用这个现成的计算结果。
- O(NlogN)解法。分治法。这种解法的思路时把大问题分解成两个相对小一些的问题,分别计算两个小问题的结果,然后汇总得到大问题的答案。把大数组均分成两个小数组,那么最大子数组必然位于左边、右边或中间这三个位置之一。
- O(N)解法。O(N)解法抓住了问题的本质:最大子数组从首元素到任意一个元素之间的总和永远大于0。根据这个性质,O(N)解法只需从左到右扫描一遍数组,扫描时,先假设当前扫描元素就是最大子数组的元素,并即时计算当前数组元素之和。等到计算结果不大于0后,可以舍弃当前子数组,从下一个元素开始重复统计。我认为O(N)解法比O(NlogN)解法更优的主要原因是前者更抓住了问题的本质。
2. 数学证明方法
- 数学归纳法
- 反证法
3. 递归的基本规则
- 基准情形。必须存在不需递归就能解决的基准情形。
- 不断推进。递归调用必须朝着基准情形的方向不断推进。
- 设计法则。假设所有的递归调用都能生效。
- 合成效益法则。切勿在不同的递归调用中做重复性的工作。
刷题笔记
18. 如何用非递归的方式来实现AVL树?
几经周折,今天终于完成了AVL树的编码,并通过了自己的测试用例。我是用递归方式实现的,毕竟在更新树的高度等操作时使用递归会很方便。那么非递归方式又该如何实现呢?有空得思考下。
17. 学习数据结构真有趣
大二时我几乎逃掉了所有的数据结构课,而现在我自学数据结构时却发现原来它这么有趣。大概是敲代码刷掉一道道习题给我带来了成就感和自信心吧。毕竟经过努力我基本能解决掉所有的课后习题,虽然有些题目要思考较长时间。想起陶哲轩的一句话:“发展数学兴趣所要做的最重要的事情是有能力和自由与数学玩。”大抵编程也如此吧。管它呢,开心就好。最近开始学习树结构,我迫不及待地想弄懂AVL树、splay树、B+树和红黑树等各种树的原理,那感觉比森林探险时遇到一棵棵葱葱郁郁的、直插云霄的参天古树还要激动和欣喜呢!
16. 二叉搜索树的一个命名问题
在实现二叉搜索树的插入操作时遇到一个命名问题:我首先调用一个函数来查找应该插入的位置,假设要在节点cur下面插入,则插入的位置为cur->left或cur->right,但在命名这个函数和输入参数时有点纠结,总感觉不恰当。看来想个清晰易懂的命名也不容易啊。
15. 使用表达式树来实现前缀、中缀、后缀表达式的相互转换
本周开始学习第四章“树”,然后发现用表达式树来实现前缀、中缀、后缀表达式之间的相互转换貌似很方便,于是挽起袖子敲代码实现了一下,确实如此。基本思路是:先读入前缀、中缀或后缀表达式,将其转化为一颗表达式树。然后前序、中序和后序遍历此树将分别得到前缀、中缀和后缀表达式。
14. 邓俊辉《数据结构》中关于“栈的应用”的总结
最近晚上经常一边吃宵夜一边在“学堂在线”网站上面邓俊辉的《数据结构》公开课,目前看到邓老师讲解“栈的应用”部分,感觉总结得很到位,摘录笔记如下:
-
逆序输出问题:如进制转换。输入规模不确定的逆序输出问题,适合使用栈,因其具有“后进先出”特性及在容量方面的自适应性。
-
递归嵌套问题:如栈混洗、括号匹配。具有自相似性的问题多可嵌套地递归描述,但因分支位置和嵌套深度不固定,其递归算法的复杂度不易控制。栈结构及其操作天然地具有递归嵌套性,故可用以高效地解决这类问题。
-
延迟缓冲问题:如表达式求值。在一些应用问题中,输入可分解为多个单元并通过迭代依次扫描处理,但过程中的各步计算往往滞后于扫描的进度,需要待到必要的信息已完整到一定程度之后,才能作出判断并实施计算。在这类场合,栈结构可以扮演数据缓冲区的角色。
-
逆波兰表达式:reverse Polish notation, RPN。数学表达式的一种,其语法规则可概括为:操作符紧邻于对应的操作数之后。
13. 是时候学习vim的代码开发技巧了
目前自己一直使用vim编辑器来写C语言代码,但对vim的许多强大功能并不熟悉,导致开发效率低下。是时候安装一些vim插件并学习类似IDE的代码开发技巧了。
12. Bug 6:循环双链表初始化时误将一维指针当二维指针
我在实现循环双链表时定义了两个哨兵:head和tail。初始化时,我首先调用create_node(struct list **head, void *data)接口创建了head节点。由于初始化时要将head和tail的prev和next指针均指向对方,因此我在创建tail节点时这样写:result = create_node(head->next, data)。我的本意是创建一个新节点并将其地址返回给head->next,但我的第一个入参应该写成&head->next而非head->next!我误把一维指针当做二维指针了!然而gcc编译器并没有报错,估计是默默地帮我执行了一维指针到二维指针的强制转换......
11. Bug 5:申请内存时误将指针当结构体导致释放内存时程序崩溃
在实现栈时,发现每次调用stack_clear()接口来释放内存时程序就会崩溃,一开始以为是重复释放内存或释放空指针导致的,但修改后依然崩溃,最后才发现原来自己在栈的初始化函数中有个严重的Bug:申请内存时,误将指针当结构体,结果只申请了一个指针的内存,也就是4字节,而我的栈节点实际需要8个字节!这件事使我意识到把Stack定义为结构体类型,比定义为结构体指针类型好些。虽然使用时要多一个星号,但可以避免诸如本次之类的错误。
// 这里的Stack是个指针!malloc的长度应该是sizeof(*stck)
Stack stck = NULL;
stck = (Stack)malloc(sizeof(Stack));
10. 后缀表达式转中缀表达式
习题3.20第3问是将后缀表达式转为中缀表达式。我觉得这一问有点难度,主要是要考虑有括号的情况。(但课本并没用星号标记这一问,说明作者认为并不困难,也说明......我很菜)。最后我花了好几天下班时间才完成这一问,下面记录下我的解法。
- 用链表存储表达式,表达式的元素是char型,可能是运算数或运算符。
- 当读入一个运算数时,若链表中的尾元素也是运算数或右括号,则说明此处需要插入一个运算符,但这个运算符要在后面才能知道,因此先插入一个空字符串,然后插入当前运算数。
- 当读入一个运算符时,从后往前搜索链表,找到第一个空字符串的位置,修改其值为当前运算符。此时,还要判断是否需要插入括号,见第4步。
- 第3步已经找到运算符应该插入的位置,这个位置将表达式分为左右两个子表达式。分别求出两个子表达式的最低优先级的运算符,若小于当前运算符的优先级,则需要给子表达式添加括号。
解这道题的收获:
- Don't Quit! 做第3问时一度想放弃,后来想出解决方案后又觉得很有趣。要继续保持编程训练,继续培养编程的兴趣。
- 在思考添加括号的问题时,我一开始想到多重括号嵌套的情形,感觉很难处理。后来使用抽象的方法,在考虑给当前运算符左右两边的子表达式添加括号时,将已含有括号的表达式简化成一个操作数,这样再思考问题就简单了。
9. Bug 4:命名冲突导致局部变量名覆盖全局变量名
做习题3.20时,发现某个函数里获取运算符的优先级出错。我是这样求运算符的优先级:定义一个数组prio,存储所有运算符的优先级,因此只需用运算符来索引数组prio即可。我明明定义了prio['+']=2,但在该函数中获取到的值却为0。后来终于找到原因:我在该函数中也定义了局部变量prio,从而覆盖了全局数组prio。这个故事给我的启示:1. 尽量少用全局变量;2. 实在要用全局变量,其命名最好避免与局部变量冲突,可以加个g_前缀来区分。
8. C语言的链表实现如何支持多类型?
-
目前我实现链表的方式大概是:链表的头文件声明中,数据类型均声明为void类型,在初始化链表时传入数据类型的大小,并保存在list_data_size这个全局变量中。这导致我在一个源文件中使用链表时,只能定义一种数据类型的链表。
-
我想到的一种解决方案:不使用全局变量来存储数据类型大小,而通过函数传参的方式传入数据类型大小。但这样的话,每个链表的接口都需要增加data_size这个变量,感觉有点丑陋。有待思考更好的解决方法。
7. 如何确定链表遍历的终止条件
- 不设置哨兵、非循环链表:当指针为空时终止,即
while (cur != NULL) - 不设置哨兵、循环链表:当指针的next元素指向首元素时终止,即
while (cur->next != first) - 设置哨兵:当指针等于尾哨兵节点时终止,即
while (cur != tail)
6. Bug 3:埋伏在缓冲区的' '
做习题3.20,发现第二次输入表达式时出现异常,代码片段大概如下:
while (go_on == 'y')
{
memset(infix_expr, 0, MAX_EXPR_LEN);
memset(post_expr, 0, MAX_EXPR_LEN);
printf("Enter infix expression:
");
get_line(infix_expr);
infix_to_postfix(infix_expr, post_expr);
printf("The postfix expression:
%s
", post_expr);
printf("Continue?('y' or 'n'): ");
scanf(" %c", &go_on);
}
当第一次循环走到最后,我输入'y'后,进入第二次循环,但我还没来得及输入新的表达式,就直接跑到后面让我再次确认是否Continue了。经分析明白了原因:我输入'y'然后按Enter键时,'y'字符被scanf读取了,而紧跟着的' '则留在stdin缓冲区中。当我下一次循环想读取stdin的表达式时,遇到' '就直接停止读取了。目前我的解决方案是在scanf下面增加一次getchar(),把stdin的' '先输出来。
5. 反转链表原来这么简单
习题3.12要求我们实现链表的反转,一开始我还以为有点麻烦,最后写完代码发现,原来反转链表的主要代码(循环体内的语句)只有4行,没想到这么简单!其实思路确实简单,就是保持原来的首节点不变,不断删除原首节点的下一节点并在表头插入。(以下代码省略了指针判空处理)
struct list *prev = head->next;
struct list *cur = prev->next;
while (NULL != cur)
{
prev->next = cur->next;
cur->next = head->next;
head->next = cur;
cur = prev->next;
}
4. 如何更高效地计算2^4000
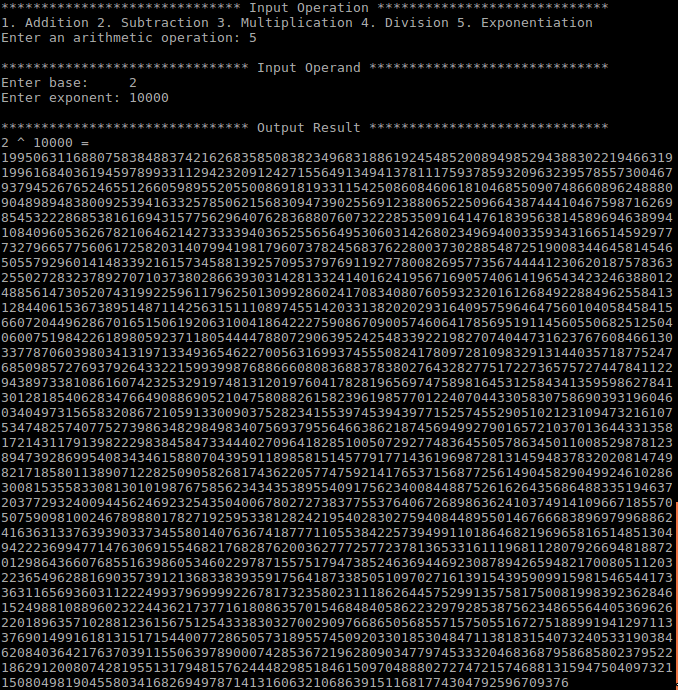
习题3.9要求我们写一个整数算术运算包,并计算2^4000次方中含有0~9各位数字的数目。我用链表实现了整数的加法和乘法,然后使用简单的循环来实现幂运算:
for (cur_expo = 1; cur_expo < expo; cur_expo++)
{
result = multiply_polynomials(first_poly, poly, &product_poly);
if (SUCCESS != result)
{
printf("failed to multiply polynomial!
");
return result;
}
list_clear(first_poly);
first_poly = product_poly;
product_poly = NULL;
}
在运行时,计算2的1000次方花费大约十几秒,计算2的4000次方则电脑卡住超过半小时。于是我开始考虑采取性能更好的算法。我当时的直觉是不断的平方,那么很快就能算到4000次方了。沿着这个方向想下去,还真让我想到一个简单而性能更好的算法:
1. 将4000化成二进制形式(1111,1010,0000),即4000 = 2^11 + 2^10 + 2^9 + 2^8 + 2^7 + 2^5
2. 创建数组a[k](0<=k<12),令a[k]=2^(2^k),显然a[k+1] = a[k]^2,所以通过12次循环即可计算出a[k]各项的值。
3. 2^4000 = a[11] + a[10] + a[9] + a[8] + a[7] + a[5]
编写代码实现这个算法后,编译运行,计算2的10000次方耗时不到1秒!说明时间性能得到明显改善。这道题让我感受到了算法的力量!
3. Bug 2:重复释放链表的内存
解决习题3.13时,在实现基数排序时,自己定义了两个链表数组,每次循环结束后把数组2拷贝到数组1,后面释放内存时分别对两个数组进行释放,结果由于重复释放内存导致系统崩溃!
2. 链表删除结点的注意事项
- 处理好待删结点的前驱和后继的赋值
- 注意头结点的赋值是否需要更改
1. Bug 1:自定义函数名与系统预留函数名冲突
写完习题3.9的代码后运行,每当我输入非法值时,总是提示"Segmentation fault (core dumped)"。大意是访问了非法内存。检查代码,已经进行了入参检查,没看出问题。使用gdb调试,发现每次运行到异常分支"error(...);"就抛出上述错误提示。error()是我用来输出错误提示信息的一个函数,其实现只是对printf的简单封装,应该没啥问题。最后,我使用printf代替error,结果就正常了。因此,估计error是C语言系统或编译器预留的一个函数,我自己重新定义这个函数后,实际上链接的时候还是链接到系统或编译器的那个函数去了,而那个函数的入参与我自定义的应该不一致,最后导致非法内存访问问题。