一、Python的基础
1、Python是怎样的语言?

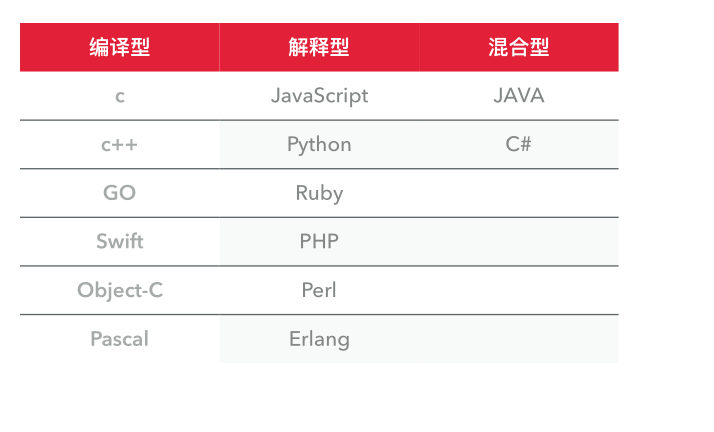
2、Python的安装
Linux安装(python3)
yum install -y make zlib zlib-devel gcc-c++ libtool openssl openssl-devel gcc ncurses-devel libpcap-devel wget bzip2-devel tar zxvf Python-3.5.2.tgz cd Python-3.5.2 mkdir -p /usr/local/python/3.5.2/lib ./configure --enable-shared --prefix=/usr/local/python/3.5.2 LDFLAGS="-Wl,-rpath /usr/local/python/3.5.2/lib" make make install ln -fs /usr/local/python/3.5.2/bin/python3.5 /usr/bin/python3
3、第一个Python程序
#!/usr/bin/env python print "hello,world"
4、Python的变量
变量定义的规则:
变量名只能由数字、字母和下划线组成
不能以数字开头
禁止使用python中的关键字
变量名要具有可描述性
变量名要区分大小写
不能使用中文和拼音
推荐写法:
驼峰体
下划线(官方推荐)
AlexOfOldboy = 89 #这是驼峰体
alex_of_oldboy = 89 #这是下划线
变量的作用:
可变的量 存储数据 开发最大的忌讳是写重复的代码
5、二进制的介绍
二进制是计算技术中广泛采用的一种数制,二进制由用0和1组成,进位规则是“逢二进一”,借位规则是“借一当二”,计算机中的二进制则是一个非常微小的开关,用“开”来表示1,“关”来表示0。
十进制转二进制
| 256 | 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
6、字符编码
ASCII
美国标准信息交换代码,是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。 Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536
UTF-8
utF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存..
小结
编码3种:ascii(256个,二进制8位长度表示)、unicode(至少二进制16位长度表示)、utf-8(同时可满足ascii和unicode两种表示,减少内存占用) Python2.7版本默认是ascii码,只持256个,如果需要支持中文等字符,需使用utf-8编码模式,建议在代码的开头加入如下内容。声明编码 # -*- coding:utf-8 -*-
测试
#!/usr/bin/env python print "你好"
7、数据类型
1)数字
int(整型):在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1 float(浮点型):浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
2)布尔值
真或假 True或False 1 或 0 print(3 > 2) # True 成立
3)字符串
特性:不可修改
字符串常用功能
移除空白:strip(),默认为空格或换行符,只能删除开头或是结尾的字符,不能删除中间部分的字符,可以自定义字符,strip(123)。 分割:split(),通过指定分隔符对字符串进行切片,默认所有的空字符,包括空格、换行( )、制表符( )等,默认为 -1, 即分隔所有。##以什么为分隔符,分割几次## 长度:len(),返回对象(字符、列表、元组等)长度或项目个数, 索引:index() ,检测字符串中是否包含子字符串,可指定范围,beg(开始,默认为0)和 end(结束,默认为字符串的长度),如果str不在 string中会报一个异常。 切片:slice(),实现切片对象,包含开始,结束,间距三个参数。
格式化输出
name = "jack" print "I am %s" %name #输出: i am jack PS: %s(字符串),%d(整数),%f(浮点数)
4)列表
创建列表
names = ['tom','jim','jack','boy','test','key']
基本操作:
切片:取多个元素(下标从0计数)
names[1:4] #取下标1到4的值,包括1,不包括4 names[1:-1] #取下标1到-1的值,不包括-1names[:3] #取下标0到3的值,0可以忽略 names[3:] #取下标3到最后的值,最后可以忽略names[3:-1] #取下标3到-1的值names[::2] #从下标0开始,每隔2个,取一个值,默认是1
追加
names.append("book") #追加到最后
插入
names.insert(2,"disk") #插入到下标2(下标1的后面)
修改
names[2] = "mark" #修改下标2的值
删除
del names[2] #删除下标2的值 names.remove("disk") #删除指定元素 names.pop() #删除列表最后一个值
扩展
b = [1,2,3] names.extend(b) names
['tom','jim','jack','boy','test','key',1, 2, 3]
拷贝
names_2 = names.copy() names_2 ['tom','jim','jack','boy','test','key',1, 2, 3]
统计
names.count("tom") #统计tom的次数
排序&翻转
names.sort() #排序,3.0不同数据类型不能在一起排序
names.reverse() #反转,倒序
获取下标
names.index("tom") #只能返回找到的第一个下标
names[names.index("tom")]="com" #查找并替换
8、运算
算数运算:

比较运算:

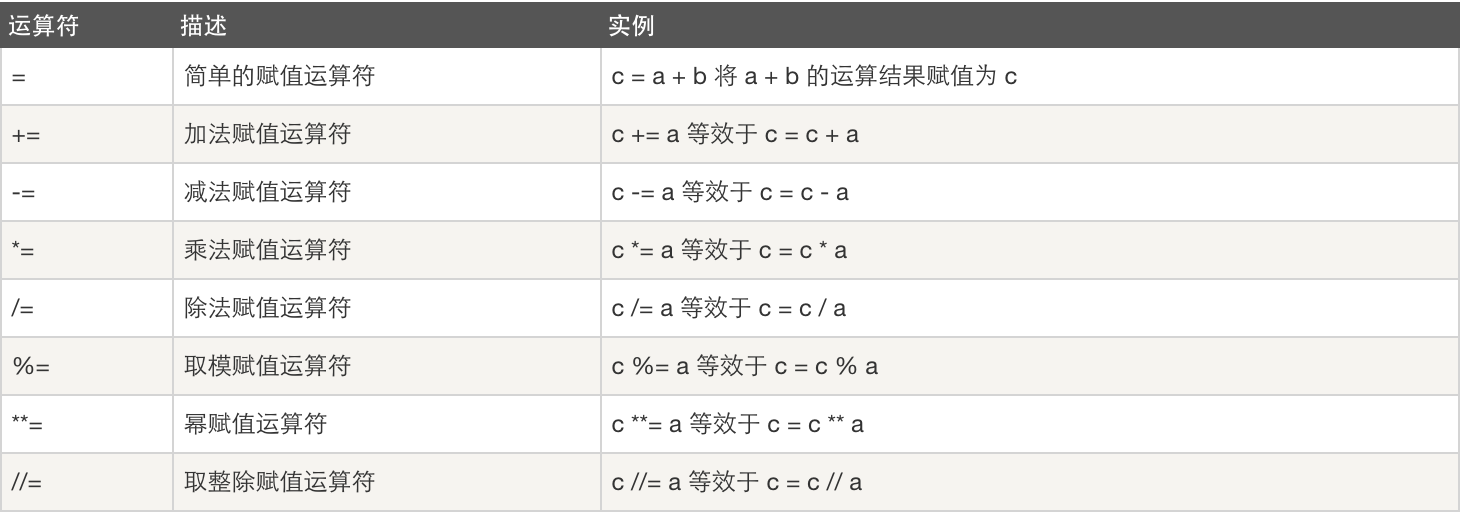
赋值运算:
逻辑运算:

成员运算:

身份运算:

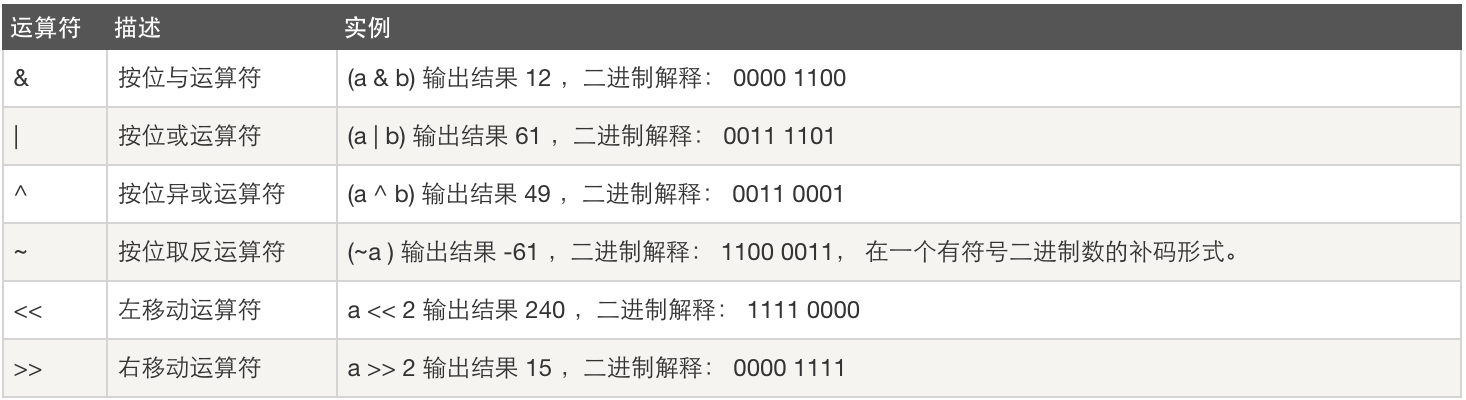
位运算:
#128 64 32 16 8 4 2 1 a = 60 #0 0 1 1 1 1 0 0b = 13 #0 0 0 0 1 1 0 1 #a ^ b = 0 0 1 1 0 0 0 1 = 49 相同的得0,不同的得1 #a & b = 0 0 0 0 1 1 0 0 = 12 上下的值必须均为1 # a | b = 0 0 1 1 1 1 0 1 = 61 上下的值只需有一个为1
运算符优先级:
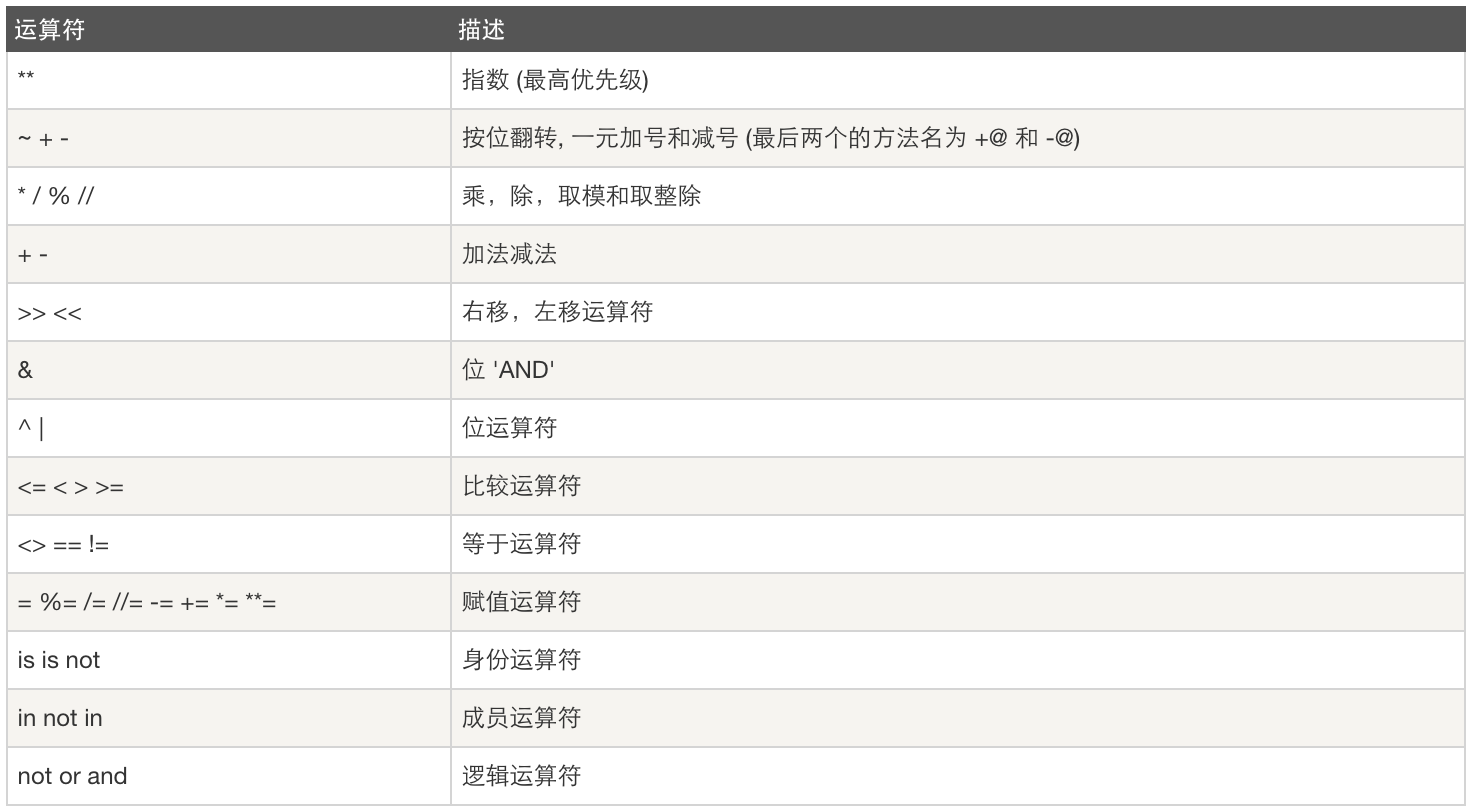
9、注释
单行注视:用# 多行注释:""" 被注释内容 """或 ''' 被注释内容 '''
用户交互
name = input("name:") #输入模块
age = input("age:") job = input("job:") info = '''---info--- #多行用'''或"""" Name:%s Age: %s Job: %s ''' %(name,age,job) print (info)
10、流程控制
1)If … else…
if:如果条件成立,执行
else:否则执行
场景:用户登陆验证
name = input("请输入你的名字:")
if name == "tom":
print ("登录成功")
else:
print ("登录失败")
2)If … elif … else …
用户输入3次失败后退出
name = "tom" pwd = 123 for i in range(3): na_me = input("用户名: ") p_wd = int(input("密码:")) if name == na_me and pwd == p_wd: print ("登录成功") break else: print ("登录失败,请重新输入") print ("您还有%d次机会" %(2-i)) else: print ("登录次数超过3次,请稍后重试")
用法:
# 第一种 if 条件: pass # 第二种 if 条件: pass # pass语句用来占为,表示什么都不做 else: pass # 第三种 if 条件1: pass elif 条件2: pass elif 条件3: pass else: pass
猜年龄
age = 56 num = int(input("猜猜我今年多大了: ") ) if num == age: print("恭喜你,猜对了") elif num > age: print("太大了") else: print("太小了")
作业成绩
score = int(input("score: ")) if score <=100 and score >=0: if score >=90 : print("A") elif score >=80 : print("B") elif score >= 70: print("C") elif score >=60 : print("D") else: print("E") else: print("错误,请输入0-100范围内 ")
3)while循环
# while循环结构 while 判断条件: # 只有条件不成立时退出循环,如果条件为真,成为一个死循环 执行语句……
输出1到10
# 循环输出1-10所有整数 num = 1 while num <11: print(num) num = num +1
猜数字游戏
init_num = 12 num = int(input("Enter:")) while init_num != num: if num > init_num: print("数字过大") else: print("数字过小") num = int(input("Enter:")) print("猜对了")
break语句
# 输出1-5 num = 1 while num <11: print("当前数字是",num) if num == 5 : break num = num +1 print("现在数字变成了:",num)
break的作用: 结束循环,在死循环中,通过设置一定的条件来结束循环
continue语句
# 输出1-100之间所有奇数 num = 0 while num<100: num = num + 1 if num%2 ==0: continue print(num)
while循环中的else:
# while循环结构 while 判断条件: 执行语句…… else: 执行语句…… # else:在正常循环结束后,才会执行,如果循环中有break,else不被执行
例子
# 循环没有被中断 num = 0 while num<10: num = num + 1 if num%2 ==0: continue print(num) else: print("else-----") ### 循环被中断 num = 0 while num<10: num = num + 1 if num%2 ==0: break print(num) else: print("else-----")
嵌套循环:循环套循环
num1 = 0 while num1 <3: print(num1,end="++" ) num1 += 1 num2 = 0 while num2<3: print(num2,end=" ") num2 +=1 print()
输入任意2个数,输出#号形状的长方形
x=int(input("x: ")) y=int(input("y: ")) z1 = 0 while z1 < x: z2=0 while z2 < y: print("#",end=" ") z2+=1 print() z1+=1
三角形
z=int(input("z: ")) x=1 while x<=z: y=z while y>x-1: print("#",end=" ") y-=1 print() x+=1
z=int(input("z: ")) x=1 while x<=z: y=0 while y<=x-1: print("#",end=" ") y+=1 print() x+=1
九九乘法表
x=1 while x<=9: y=1 while y<x+1: print("%s*%s=%s"%(y,x,x*y),end=" ") y+=1 print() x+=1
4)for循环
# for 循环示例 for i in range(10): print(i)
输入任意2个数,输出#号形状的长方形
x=int(input("x: ")) y=int(input("y: ")) for i in range(x): for w in range(y): print("#",end=" ") print()
三角形
z=int(input("z: ")) for x in range(z): for y in range(x+1): print("#",end=" ") print()
z=int(input("z: ")) for x in range(z,-1,-1): for y in range(x): print("#",end=" ") print()
九九乘法表
for x in range(1,10): for y in range(1,x+1): print("%s*%s=%s"%(y,x,x*y),end=" ") print()
标志位
exit_flag = False for i in range(10): if i <5: continue print(i) for j in range(10): print("abc",j) if j == 6: exit_flag = True #标志位设定为True,跳出内循环 break if exit_flag: #检测标志位是True,跳出循环 break
11、元组
ages = (11, 22, 33, 44, 55) ages = tuple((11, 22, 33, 44, 55)) 元组:只读列表,数据可查询,不能修改,一个是count,一个是index 元组写在小括号(())里,元素之间用逗号隔开
购物车实例
#定义商品列表 alist = [("ipod",3000),("book",500),("mac",2000)] shopping=[]
#输入工资 gz = input("请输入你的工资:") if gz.isdigit(): gz = int(gz) while True:
#打印商品内容 for i,v in enumerate(alist): print(i,v) #用户选择商品 bh = input("请输入要买的编号/退出q: ")
#验证输入是否合法 if bh.isdigit(): bh = int(bh) if bh >= 0 and bh < len(alist): #定义用户选择商品列表 itm = alist[bh]
#如果钱够,用本金减去该商品价格,并将该商品加入购物车 if gz > itm[1]: gz-=itm[1] shopping.append(itm[0]) #如果钱不够,打印还差多少钱? else: print("你的余额不足,还差%s" %(itm[1]-gz)) #防止输错 else: print("编号不存在,请你重新输入")
#用户退出,打印购买的商品和数量及余额 elif bh == "q": for i in shopping: pass print("购买的商品是%s,余额是%s"%(i,gz),"数量: %s"%shopping.count(i)) break
#防止工资输错 else: print("你输入的是非法数字,请重新输入")
12、字典
字典一种key - value 的数据类型,无序存储的,key必须是唯一的,不可变类型,如:数字、字符串、元组
字典两大特点:无序,键唯一
创建字典:
dic1 = {'name':"tom",'age':26}
dic = {
'name':"tom",
'age':26,
}
dic2 = dict((('name',"tom"),('age',26),))
增加
dic3={} dic3['name']='alex' dic3['age']=18 a=dic3.setdefault('name','yuan') b=dic3.setdefault('ages',22)
键存在,不改动,返回字典中键对应的值
键不存在,在字典中增加新的键值对,并返回相应的值
删除
dic4={'name': 'tom', 'age': 18,'class':1}
清空字典
# dic4.clear()
删除字典中指定键值对
del dic4['name']
随机删除某组键值对,并以元组方式返回值
a=dic4.popitem()
删除字典中指定键值对,并返回该键值对的值
# print(dic4.pop('age'))
删除整个字典
# del dic4
修改
dic5={'name': 'tom', 'age': 18}
dic5['name']='jack'
dic6={'sex':'male','hobby':'girl'}
dic5.update(dic6)
查找
dic7={'name': 'tom', 'age': 18}
若key存在,返回值,不存在,就报错
print(dic7['name'])
若key存在,返回值,不存在,返回None
print(dic7.get('age'))
若key存在,返回值,不存在,返回False
print("ages" in dic7)
print(dic7.items()) #key和values
print(dic7.keys()) #key
print(dic7.values()) #values
print(list(dic7.values())) #列表存储value
字典的嵌套
cn = { "北京":{ "朝阳": ["国贸","望京"], "海淀": ["中关村","圆明园"], "丰台": ["丰台科技园","北京西站"], "通州":["传媒大学","双桥"] }, "上海":{ "浦东区":["迪士尼乐园","科技大学"] }, "广东":{ "天河区":["花城广场","国际金融中心"] } } cn["北京"]["朝阳"][1] += ",国展" print(cn["北京"]["朝阳"]) #输出 ['国贸', '望京,国展']
字典的遍历
dic8={'name': 'tom', 'age': 28}
for i in dic8:
print(i,dic8[i])
for items in dic8.items():
print(items)
for keys,values in dic8.items():
print(keys,values)
其他操作
##dict.fromkeys##少用,有坑
d1=dict.fromkeys(['host1','host2','host3'],'Mac') print(d1) d1['host1']='xiaomi' print(d1) d2=dict.fromkeys(['host1','host2','host3'],['Mac','huawei']) print(d2) d2['host1'][0]='xiaomi' print(d2)
##sorted(dict) : 返回一个有序的包含字典所有key的列表
dic={5:'555',2:'222',4:'444'} print(sorted(dic))
13、字符串
重要的字符串方法
# print(st.count('l')) #统计元素个数 # print(st.center(50,'#')) #居中 # print(st.startswith('he')) #判断是否以某个内容开头 # print(st.find('t')) #查找到第一个元素,并将索引值返回 # print(st.format(name='tom',age=37)) #格式化输出的另一种方式 待定:?:{} # print('My tLtle'.lower()) #所有大写变小写 # print('My tLtle'.upper()) #所有小写变大写 # print(' My tLtle '.strip()) #移除头尾空格或换行符 # print('My title title'.replace('itle','hehe',1)) #替换(源,目标,次数) # print('My title title'.split('i',1)) #指定分隔符对字符串进行分隔
# print(''.join(["123","abc"])) #字符串拼接
其他
# String的内置方法 # st='hello kitty {name} is {age}' # print(st.count('l')) #统计元素个数 # print(st.capitalize()) #首字母大写 # print(st.center(50,'#')) #居中 # print(st.endswith('tty3')) #判断是否以某个内容结尾 # print(st.startswith('he')) #判断是否以某个内容开头 # print(st.expandtabs(tabsize=20)) #tab键的数量 # print(st.find('t')) #查找到第一个元素,并将索引值返回 # print(st.format(name='alex',age=37)) #格式化输出的另一种方式 待定:?:{} # print(st.format_map({'name':'alex','age':22})) #格式化输出字典格式 # print(st.index('t')) #查找,若值不存在后报错 # print('asd'.isalnum()) #是否是字母和数字 # print('12632178'.isdecimal()) #是否是十进制 # print('1269999.uuuu'.isdigit()) #是否是数字 # print('1269999.uuuu'.isnumeric()) #是否是数字 # print('abc'.isidentifier()) #是否是非法字符(变量) # print('Abc'.islower()) #是否是小写 # print('ABC'.isupper()) #是否是大写 # print(' e'.isspace()) #是否是空格 # print('My title'.istitle()) #是否是标题(单词的首字母是大写) # print('My tLtle'.lower()) #所有大写变小写 # print('My tLtle'.upper()) #所有小写变大写 # print('My tLtle'.swapcase()) #所有大写变小写,小写变大写 # print('My tLtle'.ljust(50,'*')) #左对齐并加* # print('My tLtle'.rjust(50,'*')) #右对齐并加* # print(' My tLtle '.strip()) #移除头尾空格或换行符 # print(' My tLtle '.lstrip()) #移除左边空格或换行符 # print(' My tLtle '.rstrip()) #移除右边空格或换行符 # print('My title title'.replace('itle','lesson',1)) #替换(源,目标,次数) # print('My title title'.rfind('t')) #从右向左查查找(索引是一样的) # print('My title title'.split('i',1)) #指定分隔符对字符串进行分隔 # print('My title title'.rsplit('i',1)) #从右向左,指定分隔符对字符串进行分隔 # print('My title title'.title()) #标题化,转换所有单词的首字母是大写
全部


# string.capitalize() 把字符串的第一个字符大写 # string.center(width) 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 # string.count(str, beg=0, end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 # string.decode(encoding='UTF-8', errors='strict') 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除 非 errors 指 定 的 是 'ignore' 或 者'replace' # string.encode(encoding='UTF-8', errors='strict') 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' # string.endswith(obj, beg=0, end=len(string)) 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. # string.expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 # string.find(str, beg=0, end=len(string)) 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 # string.index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在 string中会报一个异常. # string.isalnum() 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False # string.isalpha() 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False # string.isdecimal() 如果 string 只包含十进制数字则返回 True 否则返回 False. # string.isdigit() 如果 string 只包含数字则返回 True 否则返回 False. # string.islower() 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False # string.isnumeric() 如果 string 中只包含数字字符,则返回 True,否则返回 False # string.isspace() 如果 string 中只包含空格,则返回 True,否则返回 False. # string.istitle() 如果 string 是标题化的(见 title())则返回 True,否则返回 False # string.isupper() 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False # string.join(seq) 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 # string.ljust(width) 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 # string.lower() 转换 string 中所有大写字符为小写. # string.lstrip() 截掉 string 左边的空格 # string.maketrans(intab, outtab]) maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 # max(str) 返回字符串 str 中最大的字母。 # min(str) 返回字符串 str 中最小的字母。 # string.partition(str) 有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. # string.replace(str1, str2, num=string.count(str1)) 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. # string.rfind(str, beg=0,end=len(string) ) 类似于 find()函数,不过是从右边开始查找. # string.rindex( str, beg=0,end=len(string)) 类似于 index(),不过是从右边开始. # string.rjust(width) 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 # string.rpartition(str) 类似于 partition()函数,不过是从右边开始查找. # string.rstrip() 删除 string 字符串末尾的空格. # string.split(str="", num=string.count(str)) 以 str 为分隔符切片 string,如果 num有指定值,则仅分隔 num 个子字符串 # string.splitlines(num=string.count(' ')) 按照行分隔,返回一个包含各行作为元素的列表,如果 num 指定则仅切片 num 个行. # string.startswith(obj, beg=0,end=len(string)) 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. # string.strip([obj]) 在 string 上执行 lstrip()和 rstrip() # string.swapcase() 翻转 string 中的大小写 # string.title() 返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) # string.translate(str, del="") 根据 str 给出的表(包含 256 个字符)转换 string 的字符,要过滤掉的字符放到 del 参数中 # string.upper() 转换 string 中的小写字母为大写
三级菜单
menu = { '北京':{ '海淀':{ '五道口':{ 'soho':{}, '网易':{}, 'google':{} }, '中关村':{ '爱奇艺':{}, '汽车之家':{}, 'youku':{}, }, '上地':{ '百度':{}, }, }, '昌平':{ '沙河':{ '老男孩':{}, '北航':{}, }, '天通苑':{}, '回龙观':{}, }, '朝阳':{}, '东城':{}, }, '上海':{ '闵行':{ "人民广场":{ '炸鸡店':{} } }, '闸北':{ '火车战':{ '携程':{} } }, '浦东':{}, }, '山东':{}, } #记录当前层的位置 d = menu #记录每一层的位置 m = [] while True: #输出key(各级菜单) for k in d: print(k) #用户输入 x = input(">:").strip() if len(x ) == 0:continue if x in d: #每一层=[当前层,当前层](当前层增加到每一层) m.append(d) #当前层=下一层 d = d[x] elif x == 'b': #当前层大于0 if len(m)>0: #当前层=每一层删除最后一层 d = m.pop()
14、编码
1)基本概念
1 在python 2中默认编码是 ASCII,而在python 3中默认编码是 unicode 2 unicode 分为utf-32 (占4个字节),utf-16(占两个字节),utf-8(占1-4个字节),所以utf-16 是最常用的unicode版本,但是在文件里存的还是utf-8,因为utf8省空间 3 在python 3,encode编码的同时会把stringl变成bytes类型,decode解码的同时会把bytes类型变成string类型 4 在unicode编码中 1个中文字符=2个字节,1个英文字符 = 1个字节,切记:ASCII是不能存中文字符的 5 utf-8是可变长字符编码,它是unicode的优化,所有的英文字符依然按ASCII形式存储,所有的中文字符统一是3个字节 6 unicode包含了所有国家的字符编码,不同字符编码之间的转换都需要经过unicode的过程 7 python本身的默认编码是utf-8
2)python2中的编码和转码的过程,如图
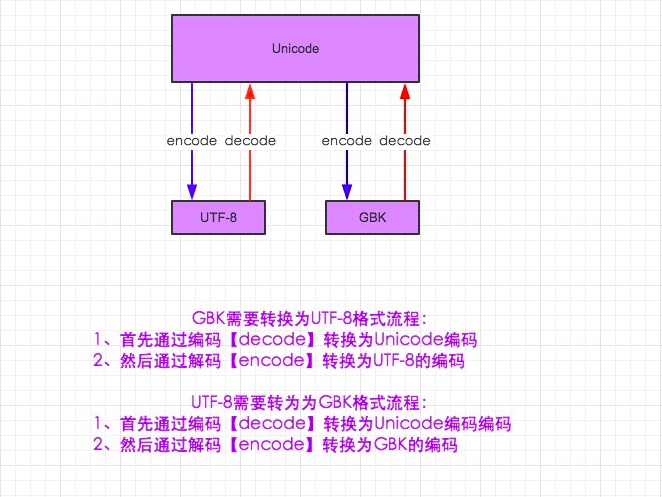
注:因为unicode是中间编码,任何字符编码之前的转换都必须解码成unicode,在编码成需要转的字符编码
3)py3的字符编码转换
在基本概念中已经说到python 3的编码,默认是unicode,所以字符编码之间的转换不需要decode过程,直接encode即可,代码如下:
1 string = "你好" 2 #string现在是utf-8的编码格式,属于unicode编码,无需要decode,直接encode 3 s_to_gbk = string.encode("gbk") 4 print(s_to_gbk) 5 #反过来,gbk要是转换为utf-8需要先解码成unicode,在编码成utf-8 6 gbk_to_utf8 = s_to_gbk.decode("gbk").encode("utf-8") 7 print(gbk_to_utf8) 8 #编码成utf-8 9 decode_utf8 = gbk_to_utf8.decode("utf-8") 10 print(decode_utf8)
注:在python 3,encode编码的同时会把stringl变成bytes类型,decode解码的同时会把bytes类型变成string类型,所以你就不难看出encode后的把它变成了一个bytes类型的数据。还有需要特别注意的是:不管是否在python 3的文件开头申明字符编码,只能表示,这个python文件是这个字符编码,文件中的字符串还是unicode。
15、文件操作
对文件操作流程
1 打开文件,得到文件句柄并赋值给一个变量 2 通过句柄对文件进行操作 3 关闭文件
文件打开模式
r 只读文本 w 清空写文本 a 追加写文本 非常重要 rb 只读二进制,主要应用在爬虫中 wb 清空写字节 ab 追加写字节 非常重要 r+ 读写 重要 w+ 清空写读 a+ 追加写读
1 t 文本模式 (默认)。 2 x 写模式,新建一个文件,如果该文件已存在则会报错。 3 b 二进制模式。 4 + 打开一个文件进行更新(可读可写)。 5 U 通用换行模式(不推荐)。 6 r 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 7 rb 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 8 r+ 打开一个文件用于读写。文件指针将会放在文件的开头。 9 rb+ 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 10 w 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 11 wb 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 12 w+ 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 13 wb+ 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 14 a 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 15 ab 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 16 a+ 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 17 ab+ 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
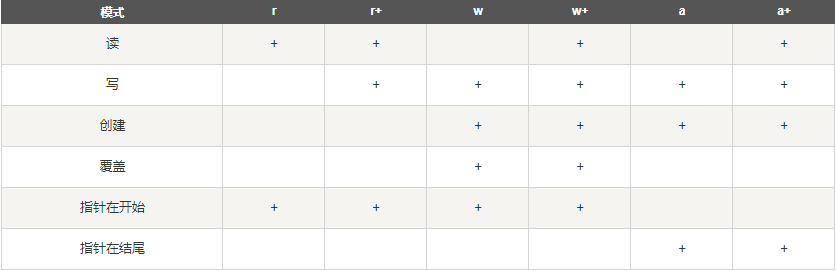
文件读取
f = open("abc.txt","r",encoding='utf8') #打开文件,只读模式,编码utf8 print(f.read(3)) #读3个字节,每个汉字3位,字母或数字1位,换行符( )2位 print(f.readline(6)) #读3个字节 print(f.readline()) #读整行,包括换行符
print(f.readlines()) #读所有行,并转换成列表,包括换行符
print(f.read()) #读取光标后的所有 f.close() #关闭文件
####无论是read()还是readline(),光标会发生位置变化
读取前5行文件
f = open("abc.txt","r",encoding='utf8') for i in range(5): print(f.readline().strip()) #strip()去掉换行符 f.close()
文件写入
# -*- coding:utf-8 -*- f = open("abc2.txt","w",encoding='utf8') #写模式 seq = ["我是谁 1 ", "你是谁 2"] f.write( seq[0] ) #写入指定的字符串,先写内存,后写磁盘,中文注意字符串的编码,要转码 f.writelines( seq ) #写入指定的列表 f.close()
追加写入
# -*- coding:utf-8 -*- f = open("abc2.txt","a",encoding='utf8') #追加模式 f.write("aaaaa") f.close()
在文件的第6行末追加内容,打印出来
f=open('abc','r',encoding='utf8') #读模式 x=0 for i in f: x+=1 if x == 6: i=''.join([i.strip(),"dddd"]) #字符串拼接 print(i.strip()) f.close()
在文件的第6行末追加内容,写到文件
# -*- coding:utf-8 -*- f_r=open('abc2','r',encoding='utf8') #读文件 f_w=open('abc3','w',encoding='utf8') #写文件 x=0 for i in f_r: x+=1 if x == 6: i=''.join([i.strip(),"dddd "]) f_w.write(i) #读一行,写一行 f_r.close() f_w.close()
读取光标位置
f = open('abc2','r',encoding='utf8') print (f.tell()) #读模式,光标的默认是0 print (f.readline().strip()) #无论是read()还是readline(),光标都会发生位置变化 print (f.tell()) f.close()
移动光标位置
f=open('abc2','r',encoding='utf8') print(f.read(6)) #读6个字节,中文是3的倍数 print(f.tell()) print(f.seek(9)) #移动光标 print(f.tell()) f.close()
打印文件编码
f=open('abc2','r',encoding='utf8') print(f.encoding) f.close()
打印读取文件的IO接口
f=open('abc2','r',encoding='utf8') print(f.fileno()) f.close()
强制刷新,保存数据到磁盘
import time #导入模块 f=open('abc2','w',encoding='utf8') f.write("hello word") f.flush() time.sleep(0.30) f.close()
进度条,体会flush的作用
方法1:
import sys,time for i in range(30): sys.stdout.write("*") sys.stdout.flush() time.sleep(0.1) 方法2: import sys,time for i in range(30): print('*',end='',flush=True) time.sleep(0.1)
文件内容替换
f_r=open('abc2','r',encoding='utf8') f_w=open('abc3','w',encoding='utf8') for i in f_r: if "我是第8行" in i: i = i.replace("我是第8行","666") f_w.write(i) f_r.close() f_w.close()
with语句
为了避免打开文件后忘记关闭,可以通过with管理上下文
with open('abc','r') as f: with open('abc','r') as f_r, open('abc','w') as f_rw:
pass
file 对象
1 file.close() 关闭文件。关闭后文件不能再进行读写操作。 2 file.flush() 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 3 file.fileno() 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 4 file.isatty() 如果文件连接到一个终端设备返回 True,否则返回 False。 5 file.next() 返回文件下一行。 6 file.read([size]) 从文件读取指定的字节数,如果未给定或为负则读取所有。 7 file.readline([size]) 读取整行,包括 " " 字符。 8 file.readlines([sizeint]) 读取所有行并返回列表,若给定sizeint>0,则是设置一次读多少字节,这是为了减轻读取压力。 9 file.seek(offset[, whence]) 设置文件当前位置 10 file.tell() 返回文件当前位置。 11 file.truncate([size]) 截取文件,截取的字节通过size指定,默认为当前文件位置。 12 file.write(str) 将字符串写入文件,返回的是写入的字符长度。 13 file.writelines(sequence) 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。
字典和字符串转换
a=str({'beijing':{'1':111}}) #转换成字符串
a=eval(a) #转换成字典
三级菜单,文件读取和写入
# #初始化 将menu存入磁盘中 # menu = {'北京':{ # '朝阳':{ # '国贸':{ # 'CICC':{}, # 'HP':{}, # '渣打银行':{}, # 'CCTV':{} # }, # '望京':{ # '陌陌':{}, # '奔驰':{}, # '360':{} # }, # '三里屯':{ # '优衣库':{}, # 'apple':{} # } # }, # '昌平':{ # '沙河':{ # '老男孩':{}, # '阿泰包子':{} # }, # '天通苑':{ # '链家':{}, # '我爱我家':{} # }, # '回龙观':{} # }, # '海淀':{ # '五道口':{ # '谷歌':{}, # '网易':{}, # 'Souhu':{}, # 'Sogo':{}, # '快手':{} # }, # '中关村':{ # 'youku':{}, # 'Iqiyi':{}, # '汽车之家':{}, # '新东方':{} # } # } # }, # '上海':{ # '浦东':{ # '陆家嘴':{ # 'CICC':{}, # '高盛':{}, # '摩根':{} # }, # '外滩':{} # }, # '闵行':{}, # '静安':{} # }, # '山东':{ # '济南':{}, # '德州':{ # '乐陵':{ # '丁务镇':{}, # '城区':{} # }, # '平原':{} # }, # '青岛':{} # } # } #字典转换成字符串,并写入到文件 # dic_m=str(menu) # with open('menu','w',encoding='utf8') as f: # f.write(dic_m) #打开文件,并转换成字典 with open('menu','r',encoding='utf8') as f: menu=eval(f.read().strip()) #记录当前层的位置 d = menu #记录每一层的位置 m=[] while True: #输出key(一级菜单) print('欢迎使用查询系统'.center(50,'#')) for k in d: print('>>',k) print('输入要查询的省市县,新增[add]、修改[mv]、删除[del]、返回[q]') x = input('>>:').strip() #查询 if x in d: #父层=[当前层,当前层] m.append(d) #子层=下一层 d = d[x] #新增 elif x == 'add': ad = input('请添加:').strip() if ad in d: print('此项已存在') else: d[ad]={} continue #修改 elif x =='mv': mv_old = input('输入修改的内容:').strip() if mv_old in d: mv_new = input('修改为:').strip() d[mv_new]=d[mv_old] del d[mv_old] continue #删除 elif x =='del': rm = input('输入要删除的内容:').strip() if rm in d: m.append(d) del d[rm] continue else: print('此项不存在:') #返回上一级或退出 elif x == 'q': if m: d= m.pop() else: print('目前为最上级菜单,输入q后为退出系统!') break else: print('输入错误') #非列表就转换成字符串,并写入到文件 if type(d) != list: with open('menu','w',encoding='utf8') as f: f.write(str(d))
截断数据
1 #截断数据(不能在r模式下) 2 #在w模式下:先清空,再写,再截断 3 #在a模式下:直接将指定位置后的内容截断 4 5 with open('abc2','r+',encoding='utf8') as f: 6 print(f.tell()) 7 f.truncate(9) 8 f.write('hello world ') 9 f.seek(0) 10 print(f.tell()) 11 print(f.read())