环境说明:
3台机器安装 GlusterFS 组成一个集群。
使用 docker volume plugin GlusterFS
服务器:
10.6.0.140
10.6.0.192
10.6.0.196
配置 hosts
10.6.0.140 swarm-manager
10.6.0.192 swarm-node-1
10.6.0.196 swarm-node-2
client:
10.6.0.94 node-94
安装:
CentOS 安装 glusterfs 非常的简单
在三个节点都安装glusterfs
yum install centos-release-gluster
yum install -y glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
配置 GlusterFS 集群:
启动 glusterFS
systemctl start glusterd.service
systemctl enable glusterd.service
在 swarm-manager 节点上配置,将 节点 加入到 集群中。
[root@swarm-manager ~]#gluster peer probe swarm-manager
peer probe: success. Probe on localhost not needed
[root@swarm-manager ~]#gluster peer probe swarm-node-1
peer probe: success.
[root@swarm-manager ~]#gluster peer probe swarm-node-2
peer probe: success.
查看集群状态:
[root@swarm-manager ~]#gluster peer status
Number of Peers: 2
Hostname: swarm-node-1
Uuid: 41573e8b-eb00-4802-84f0-f923a2c7be79
State: Peer in Cluster (Connected)
Hostname: swarm-node-2
Uuid: da068e0b-eada-4a50-94ff-623f630986d7
State: Peer in Cluster (Connected)
创建数据存储目录:
[root@swarm-manager ~]#mkdir -p /opt/gluster/data
[root@swarm-node-1 ~]# mkdir -p /opt/gluster/data
[root@swarm-node-2 ~]# mkdir -p /opt/gluster/data
查看volume 状态:
[root@swarm-manager ~]#gluster volume info
No volumes present
创建GlusterFS磁盘:
[root@swarm-manager ~]#gluster volume create models replica 3 swarm-manager:/opt/gluster/data swarm-node-1:/opt/gluster/data swarm-node-2:/opt/gluster/data force
volume create: models: success: please start the volume to access data
GlusterFS 几种volume 模式说明:
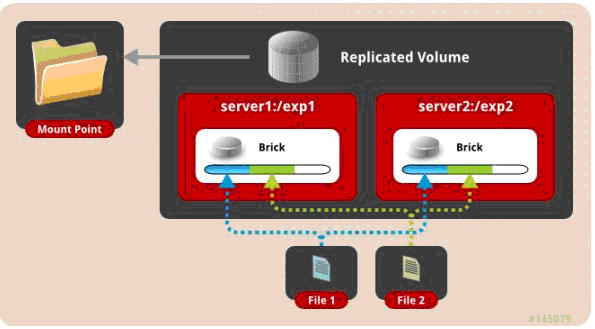
一、 默认模式,既DHT, 也叫 分布卷: 将文件已hash算法随机分布到 一台服务器节点中存储。
gluster volume create test-volume server1:/exp1 server2:/exp2
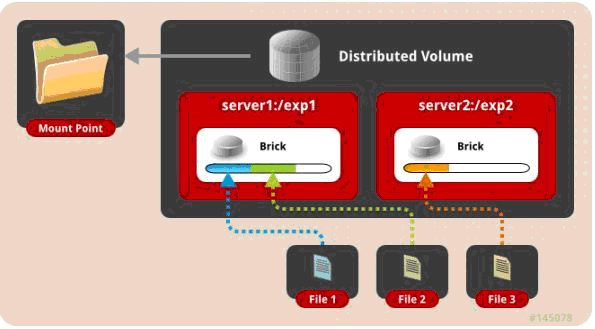
二、 复制模式,既AFR, 创建volume 时带 replica x 数量: 将文件复制到 replica x 个节点中。
gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2
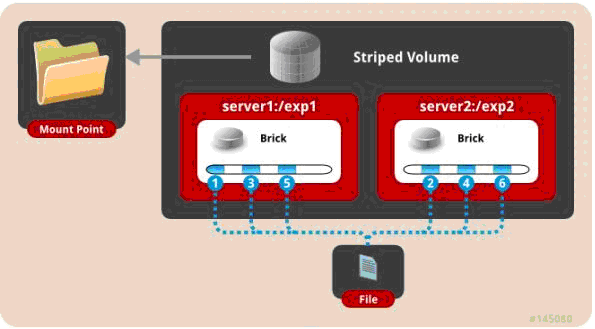
三、 条带模式,既Striped, 创建volume 时带 stripe x 数量: 将文件切割成数据块,分别存储到 stripe x 个节点中 ( 类似raid 0 )。
gluster volume create test-volume stripe 2 transport tcp server1:/exp1 server2:/exp2
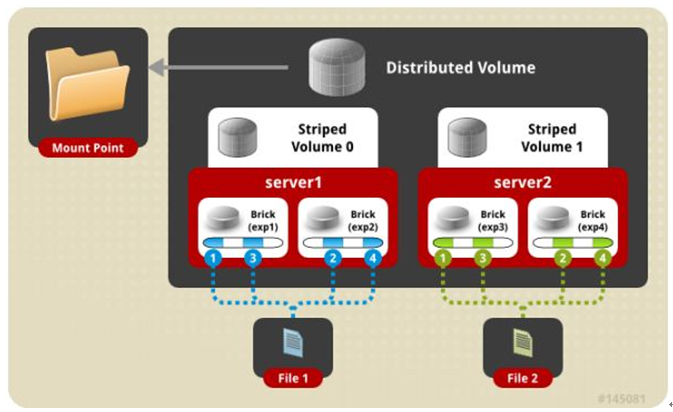
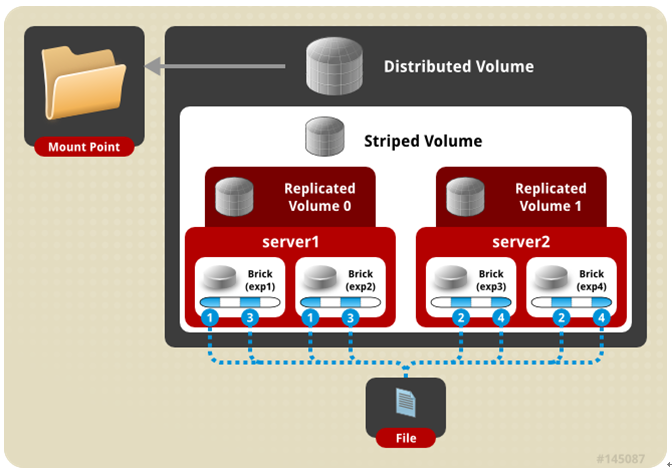
四、 分布式条带模式(组合型),最少需要4台服务器才能创建。 创建volume 时 stripe 2 server = 4 个节点: 是DHT 与 Striped 的组合型。
gluster volume create test-volume stripe 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4
五、 分布式复制模式(组合型), 最少需要4台服务器才能创建。 创建volume 时 replica 2 server = 4 个节点:是DHT 与 AFR 的组合型。
gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4
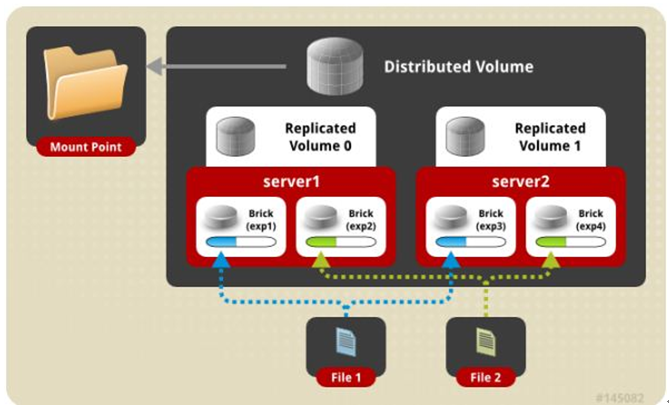
六、 条带复制卷模式(组合型), 最少需要4台服务器才能创建。 创建volume 时 stripe 2 replica 2 server = 4 个节点: 是 Striped 与 AFR 的组合型。
gluster volume create test-volume stripe 2 replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4
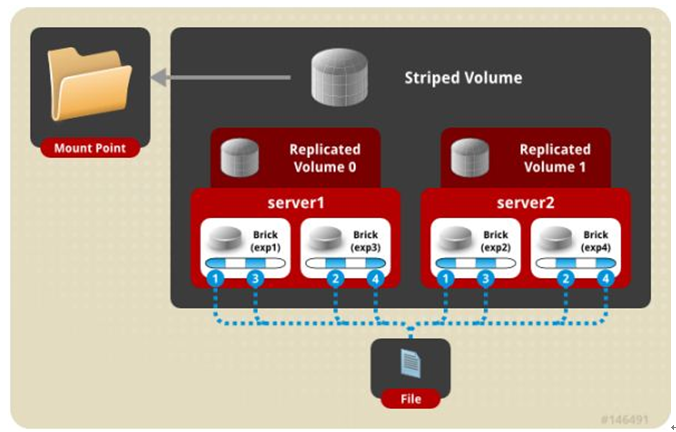
七、 三种模式混合, 至少需要8台 服务器才能创建。 stripe 2 replica 2 , 每4个节点 组成一个 组。
gluster volume create test-volume stripe 2 replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 server5:/exp5 server6:/exp6 server7:/exp7 server8:/exp8
再查看 volume 状态:
[root@swarm-manager ~]#gluster volume info
Volume Name: models
Type: Replicate
Volume ID: e539ff3b-2278-4f3f-a594-1f101eabbf1e
Status: Created
Number of Bricks: 1 x 3 = 3
Transport-type: tcp
Bricks:
Brick1: swarm-manager:/opt/gluster/data
Brick2: swarm-node-1:/opt/gluster/data
Brick3: swarm-node-2:/opt/gluster/data
Options Reconfigured:
performance.readdir-ahead: on
启动 models
[root@swarm-manager ~]#gluster volume start models
volume start: models: success
gluster 性能调优:
开启 指定 volume 的配额: (models 为 volume 名称)
gluster volume quota models enable
限制 models 中 / (既总目录) 最大使用 80GB 空间
gluster volume quota models limit-usage / 80GB
#设置 cache 4GB
gluster volume set models performance.cache-size 4GB
#开启 异步 , 后台操作
gluster volume set models performance.flush-behind on
#设置 io 线程 32
gluster volume set models performance.io-thread-count 32
#设置 回写 (写数据时间,先写入缓存内,再写入硬盘)
gluster volume set models performance.write-behind on
部署GlusterFS客户端并mount GlusterFS文件系统 (客户端必须加入 glusterfs hosts 否则报错。)
[root@node-94 ~]#yum install -y glusterfs glusterfs-fuse
[root@node-94 ~]#mkdir -p /opt/gfsmnt
[root@node-94 ~]#mount -t glusterfs swarm-manager:models /opt/gfsmnt/
[root@node-94 ~]#df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/vg001-root 98G 1.2G 97G 2% /
devtmpfs 32G 0 32G 0% /dev
tmpfs 32G 0 32G 0% /dev/shm
tmpfs 32G 130M 32G 1% /run
tmpfs 32G 0 32G 0% /sys/fs/cgroup
/dev/mapper/vg001-opt 441G 71G 370G 17% /opt
/dev/sda2 497M 153M 344M 31% /boot
tmpfs 6.3G 0 6.3G 0% /run/user/0
swarm-manager:models 441G 18G 424G 4% /opt/gfsmnt
测试:
DHT 模式 客户端 创建一个 1G 的文件
[root@node-94 ~]#time dd if=/dev/zero of=hello bs=1000M count=1
记录了1+0 的读入
记录了1+0 的写出
1048576000字节(1.0 GB)已复制,9.1093 秒,115 MB/秒
real 0m9.120s
user 0m0.000s
sys 0m1.134s
AFR 模式 客户端 创建一个 1G 的文件
[root@node-94 ~]#time dd if=/dev/zero of=hello.txt bs=1024M count=1
录了1+0 的读入
记录了1+0 的写出
1073741824字节(1.1 GB)已复制,27.4566 秒,39.1 MB/秒
real 0m27.469s
user 0m0.000s
sys 0m1.065s
Striped 模式 客户端 创建一个 1G 的文件
[root@node-94 ~]#time dd if=/dev/zero of=hello bs=1000M count=1
记录了1+0 的读入
记录了1+0 的写出
1048576000字节(1.0 GB)已复制,9.10669 秒,115 MB/秒
real 0m9.119s
user 0m0.001s
sys 0m0.953s
条带复制卷模式 (Number of Bricks: 1 x 2 x 2 = 4) 客户端 创建一个 1G 的文件
[root@node-94 ~]#time dd if=/dev/zero of=hello bs=1000M count=1
记录了1+0 的读入
记录了1+0 的写出
1048576000字节(1.0 GB)已复制,17.965 秒,58.4 MB/秒
real 0m17.978s
user 0m0.000s
sys 0m0.970s
分布式复制模式 (Number of Bricks: 2 x 2 = 4) 客户端 创建一个 1G 的文件
[root@node-94 ~]#time dd if=/dev/zero of=haha bs=100M count=10
记录了10+0 的读入
记录了10+0 的写出
1048576000字节(1.0 GB)已复制,17.7697 秒,59.0 MB/秒
real 0m17.778s
user 0m0.001s
sys 0m0.886s
针对 分布式复制模式还做了如下测试:
4K随机写 测试:
安装 fio (yum -y install libaio-devel (否则运行fio 会报错engine libaio not loadable, 已安装需重新编译,否则一样报错))
[root@node-94 ~]#fio -ioengine=libaio -bs=4k -direct=1 -thread -rw=randwrite -size=10G -filename=1.txt -name="EBS 4KB randwrite test" -iodepth=32 -runtime=60
write: io=352204KB, bw=5869.9KB/s, iops=1467, runt= 60002msec
WRITE: io=352204KB, aggrb=5869KB/s, minb=5869KB/s, maxb=5869KB/s, mint=60002msec, maxt=60002msec
4K随机读 测试:
fio -ioengine=libaio -bs=4k -direct=1 -thread -rw=randread -size=10G -filename=1.txt -name="EBS 4KB randread test" -iodepth=8 -runtime=60
read: io=881524KB, bw=14692KB/s, iops=3672, runt= 60001msec
READ: io=881524KB, aggrb=14691KB/s, minb=14691KB/s, maxb=14691KB/s, mint=60001msec, maxt=60001msec
512K 顺序写 测试:
fio -ioengine=libaio -bs=512k -direct=1 -thread -rw=write -size=10G -filename=512.txt -name="EBS 512KB seqwrite test" -iodepth=64 -runtime=60
write: io=3544.0MB, bw=60348KB/s, iops=117, runt= 60135msec
WRITE: io=3544.0MB, aggrb=60348KB/s, minb=60348KB/s, maxb=60348KB/s, mint=60135msec, maxt=60135msec
其他的维护命令:
1. 查看GlusterFS中所有的volume:
[root@swarm-manager ~]#gluster volume list
2. 删除GlusterFS磁盘:
[root@swarm-manager ~]#gluster volume stop models #停止名字为 models 的磁盘
[root@swarm-manager ~]#gluster volume delete models #删除名字为 models 的磁盘
注: 删除 磁盘 以后,必须删除 磁盘( /opt/gluster/data ) 中的 ( .glusterfs/ .trashcan/ )目录。
否则创建新 volume 相同的 磁盘 会出现文件 不分布,或者 类型 错乱 的问题。
3. 卸载某个节点GlusterFS磁盘
[root@swarm-manager ~]#gluster peer detach swarm-node-2
4. 设置访问限制,按照每个volume 来限制
[root@swarm-manager ~]#gluster volume set models auth.allow 10.6.0.*,10.7.0.*
5. 添加GlusterFS节点:
[root@swarm-manager ~]#gluster peer probe swarm-node-3
[root@swarm-manager ~]#gluster volume add-brick models swarm-node-3:/opt/gluster/data
注:如果是复制卷或者条带卷,则每次添加的Brick数必须是replica或者stripe的整数倍
6. 配置卷
[root@swarm-manager ~]# gluster volume set
7. 缩容volume:
先将数据迁移到其它可用的Brick,迁移结束后才将该Brick移除:
[root@swarm-manager ~]#gluster volume remove-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data start
在执行了start之后,可以使用status命令查看移除进度:
[root@swarm-manager ~]#gluster volume remove-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data status
不进行数据迁移,直接删除该Brick:
[root@swarm-manager ~]#gluster volume remove-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data commit
注意,如果是复制卷或者条带卷,则每次移除的Brick数必须是replica或者stripe的整数倍。
扩容:
gluster volume add-brick models swarm-node-2:/opt/gluster/data
8. 修复命令:
[root@swarm-manager ~]#gluster volume replace-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data commit -force
9. 迁移volume:
[root@swarm-manager ~]#gluster volume replace-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data start
pause 为暂停迁移
[root@swarm-manager ~]#gluster volume replace-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data pause
abort 为终止迁移
[root@swarm-manager ~]#gluster volume replace-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data abort
status 查看迁移状态
[root@swarm-manager ~]#gluster volume replace-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data status
迁移结束后使用commit 来生效
[root@swarm-manager ~]#gluster volume replace-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data commit
10. 均衡volume:
[root@swarm-manager ~]#gluster volume models lay-outstart
[root@swarm-manager ~]#gluster volume models start
[root@swarm-manager ~]#gluster volume models startforce
[root@swarm-manager ~]#gluster volume models status
[root@swarm-manager ~]#gluster volume models stop
###############################################
分布式复制卷的最佳实践:
1)搭建条件
- 块服务器的数量必须是复制的倍数
- 将按块服务器的排列顺序指定相邻的块服务器成为彼此的复制
例如,8台服务器:
- 当复制副本为2时,按照服务器列表的顺序,服务器1和2作为一个复制,3和4作为一个复制,5和6作为一个复制,7和8作为一个复制
- 当复制副本为4时,按照服务器列表的顺序,服务器1/2/3/4作为一个复制,5/6/7/8作为一个复制
2)创建分布式复制卷
磁盘存储的平衡
平衡布局是很有必要的,因为布局结构是静态的,当新的 bricks 加入现有卷,新创建的文件会分布到旧的 bricks 中,所以需要平衡布局结构,使新加入的 bricks 生效。布局平衡只是使新布局生效,并不会在新的布局中移动老的数据,如果你想在新布局生效后,重新平衡卷中的数据,还需要对卷中的数据进行平衡。
#在gv2的分布式复制卷的挂载目录中创建测试文件入下
[root@node01 ~]# df -h 文件系统 容量 已用 可用 已用% 挂载点 127.0.0.1:/gv2 10G 65M 10G 1% /mnt [root@node01 ~]# cd /mnt/ [root@node01 mnt]# touch {x..z}
#新创建的文件只在老的brick中有,在新加入的brick中是没有的 [root@node01 mnt]# ls /data/brick2 1 2 3 4 5 6 x y z [root@node02 ~]# ls /data/brick2 1 2 3 4 5 6 x y z [root@node03 ~]# ll -h /data/brick1 总用量 0 [root@node04 ~]# ll -h /data/brick1 总用量 0
# 从上面可以看到,新创建的文件还是在之前的 bricks 中,并没有分布中新加的 bricks 中
# 下面进行磁盘存储平衡
[root@node01 ~]# gluster volume rebalance gv2 start
[root@node01 ~]# gluster volume rebalance gv2 status #查看平衡存储状态
# 查看磁盘存储平衡后文件在 bricks 中的分布情况
[root@node01 ~]# ls /data/brick2
1 5 y
[root@node02 ~]# ls /data/brick2
1 5 y
[root@node03 ~]# ls /data/brick1
2 3 4 6 x z
[root@node04 ~]# ls /data/brick1
2 3 4 6 x z
#从上面可以看出部分文件已经平衡到新加入的brick中了
每做一次扩容后都需要做一次磁盘平衡。 磁盘平衡是在万不得已的情况下再做的,一般再创建一个卷就可以了。
做
模拟误删除卷信息故障及解决办法
[root@node01 ~]# ls /var/lib/glusterd/vols/ gv2 gv3 [root@node01 ~]# rm -rf /var/lib/glusterd/vols/gv3 #删除卷gv3的卷信息 [root@node01 ~]# ls /var/lib/glusterd/vols/ #再查看卷信息情况如下:gv3卷信息被删除了 gv2 [root@node01 ~]# gluster volume sync node02 #因为其他节点服务器上的卷信息是完整的,比如从node02上同步所有卷信息如下: Sync volume may make data inaccessible while the sync is in progress. Do you want to continue? (y/n) y volume sync: success [root@node01 ~]# ls /var/lib/glusterd/vols/ #验证卷信息是否同步过来
3、glustefs分布式存储优化
Auth_allow #IP访问授权;缺省值(*.allow all);合法值:Ip地址 Cluster.min-free-disk #剩余磁盘空间阀值;缺省值(10%);合法值:百分比 Cluster.stripe-block-size #条带大小;缺省值(128KB);合法值:字节 Network.frame-timeout #请求等待时间;缺省值(1800s);合法值:1-1800 Network.ping-timeout #客户端等待时间;缺省值(42s);合法值:0-42 Nfs.disabled #关闭NFS服务;缺省值(Off);合法值:Off|on Performance.io-thread-count #IO线程数;缺省值(16);合法值:0-65 Performance.cache-refresh-timeout #缓存校验时间;缺省值(1s);合法值:0-61 Performance.cache-size #读缓存大小;缺省值(32MB);合法值:字节 Performance.quick-read: #优化读取小文件的性能 Performance.read-ahead: #用预读的方式提高读取的性能,有利于应用频繁持续性的访问文件,当应用完成当前数据块读取的时候,下一个数据块就已经准备好了。 Performance.write-behind:先写入缓存内,在写入硬盘,以提高写入的性能。 Performance.io-cache:缓存已经被读过的、
3.1、优化参数调整方式
命令格式: gluster.volume set <卷><参数>
例如:
#打开预读方式访问存储
[root@node01 ~]# gluster volume set gv2 performance.read-ahead on
#调整读取缓存的大小[root@mystorage gv2]# gluster volume set gv2 performance.cache-size 256M
3.2、监控及日常维护
使用zabbix自带的模板即可,CPU、内存、磁盘空间、主机运行时间、系统load。日常情况要查看服务器监控值,遇到报警要及时处理。 #看下节点有没有在线 gluster volume status nfsp #启动完全修复 gluster volume heal gv2 full #查看需要修复的文件 gluster volume heal gv2 info #查看修复成功的文件 gluster volume heal gv2 info healed #查看修复失败的文件 gluster volume heal gv2 heal-failed #查看主机的状态 gluster peer status #查看脑裂的文件 gluster volume heal gv2 info split-brain #激活quota功能 gluster volume quota gv2 enable #关闭quota功能 gulster volume quota gv2 disable #目录限制(卷中文件夹的大小) gluster volume quota limit-usage /data/30MB --/gv2/data #quota信息列表 gluster volume quota gv2 list #限制目录的quota信息 gluster volume quota gv2 list /data #设置信息的超时时间 gluster volume set gv2 features.quota-timeout 5 #删除某个目录的quota设置 gluster volume quota gv2 remove /data 备注:quota功能,主要是对挂载点下的某个目录进行空间限额。如:/mnt/gulster/data目录,而不是对组成卷组的空间进行限制。
3.3、Gluster日常维护及故障处理
注:给自己的提示:此处如有不详之处查看qq微云--linux-glusterfs文件夹
1、硬盘故障
如果底层做了raid配置,有硬件故障,直接更换硬盘,会自动同步数据。
如果没有做raid处理方法:
参看其他博客:http://blog.51cto.com/cmdschool/1908647
2、一台主机故障
https://www.cnblogs.com/xiexiaohua007/p/6602315.html
一台节点故障的情况包含以下情况:
物理故障
同时有多块硬盘故障,造成数据丢失
系统损坏不可修复
解决方法:
找一台完全一样的机器,至少要保证硬盘数量和大小一致,安装系统,配置和故障机同样的 IP,安装 gluster 软件,
保证配置一样,在其他健康节点上执行命令 gluster peer status,查看故障服务器的 uuid
[root@mystorage2 ~]# gluster peer status Number of Peers: 3 Hostname: mystorage3 Uuid: 36e4c45c-466f-47b0-b829-dcd4a69ca2e7 State: Peer in Cluster (Connected) Hostname: mystorage4 Uuid: c607f6c2-bdcb-4768-bc82-4bc2243b1b7a State: Peer in Cluster (Connected) Hostname: mystorage1 Uuid: 6e6a84af-ac7a-44eb-85c9-50f1f46acef1 State: Peer in Cluster (Disconnected) 复制代码 修改新加机器的 /var/lib/glusterd/glusterd.info 和 故障机器一样 [root@mystorage1 ~]# cat /var/lib/glusterd/glusterd.info UUID=6e6a84af-ac7a-44eb-85c9-50f1f46acef1 operating-version=30712 在信任存储池中任意节点执行 # gluster volume heal gv2 full 就会自动开始同步,但在同步的时候会影响整个系统的性能。 可以查看状态 # gluster volume heal gv2 info
GlusterFS在企业中应用场景
理论和实践分析,GlusterFS目前主要使用大文件存储场景,对于小文件尤其是海量小文件,存储效率和访问性能都表现不佳,海量小文件LOSF问题是工业界和学术界的人工难题,GlusterFS作为通用的分布式文件系统,并没有对小文件额外的优化措施,性能不好也是可以理解的。
Media -文档、图片、音频、视频 *Shared storage -云存储、虚拟化存储、HPC(高性能计算) *Big data -日志文件、RFID(射频识别)数据