介绍UDP-RT协议,用于实时系统中高效、可靠的通信。
介绍
几乎所有现代的应用程序都要求快速和可靠的通信,但实时通信的要求更加极致,需要网络实时响应。某些情况下,要求特别高以至于需要特殊的硬件,来实现所需的性能。在过去的十年中,出现了新的技术以支持增长的需求,但是成本很高而可用性不强。因为,大多数系统仍在使用基于以太网为骨干的TCP/IP协议栈。甚至,大多数程序员还在使用同步的socket API进行开发。这篇文章探索了实时系统中主流技术的使用,展示了在系统中如何设计和开发通信。特别的是,它推荐UDP传输层之上的可靠的协议,获得小于1毫秒的平均交互时间(RTT round trip time),同时每秒钟处理成千上万的消息,在网络中的每一个端口上。
背景
实时网络不是一项简单的工作,因此在深入之前,需要先分析系统连接需求。正确的做法是对系统中的交通进行展开和分类。第一个要做的分类是消息大小,和延时需求。在多数情况下,这两个参数足以用来选择传输协议和网络拓扑。
让我们从传输协议的选择开始。因为本文专注于TCP/IP,我们的选择将在TCP和UDP之间。下面的表格展示了选择协议的规则:
|
延时/消息大小
|
几KB或更少
|
几十KB或更多
|
|
1毫秒(可以更小)到几十毫秒
|
UDP
|
?
|
|
几百毫秒或更多
|
TCP
|
TCP
|
上面的表格中,在低延时和长消息的单元格上有一个问号。在这种特殊情况中,我们需要考虑不同的手段,比如Infiniband之上的RDMA,但这些技术不在本文的范围内。
TCP
长消息可能包含数据表、图片、视频、一堆参数或其他类型的数据,需要在系统范围内传输而不损失性能。TCP协议在处理大量数据的时候工作良好。长消息允许TCP给引擎预热,找到最佳节奏滑动窗口,避免重传,以及获得高带宽利用率。然而当延时需求变得紧张时,TCP暴露出它的弱点。
首先,TCP协议是不确定的。设想一个服务器对多个客户端的情况。客户端共享同一个连接,因此它们的通信影响每个人的延时。考虑到TCP协议缺少平衡和高质量的服务特性,延时变动可能达到几百毫秒。甚至,在多客户端的情况下,带宽利用率可能显著下降(在先前的系统中,可能跌至50%)。
另一个困扰TCP的问题是,缓慢的恢复处理。丢失一帧TCP之后常规的恢复可能耗时几百毫秒。有一些小的技巧可降低恢复时间。比如,Windows XP中,配置注册表的TcpAckFrequency和TcpDelAckTicks参数,可以节省200毫秒的恢复时间。遗憾的是,这些参数在所有操作系统中都不存在,或者尽管存在,也有其他的TCP定时器和算法造成恢复时间很长。
短消息对TCP来说尤其是挑战。默认情况下,TCP使用Nagle算法积攒短消息,然后一起发送。该算法会延迟数据包的发送,因而,造成延时。Socket提供一个API来禁用此行为(参见setsocket函数文档),但是先前的socket实现可能没有此功能。
综上考虑,TCP是一个良好的协议,但不适合实时通信。就像表格1中列出的,它只有在超过几百毫秒延时的系统中才能成功的应用。
UDP
实时系统中的短消息,通常用于管理硬件设备,数据审核和闭环通信(通过设备实时产生的数据来控制设备行为)。因为数据的实时性,短消息必须在数毫秒的时间内传输到目的地。能够胜任此延时的协议就是UDP。事实上,观察消息从来源到目标再返回的RTT交互时间。UDP协议之上的RTT,高度依赖于硬件和通信节点的操作系统。然而,尽管100Mb网络和非实时操作系统,比如Windows XP,支持1毫秒的平均RTT。使用实时操作系统和更高级的网卡,可能降低到微妙级别。
当然,UDP是不可靠的协议,所以使用之前我们要在应用程序层面增加可靠性特性。这是很复杂的工作,但是如果你有一个强大的操作系统,可能已经实现了替代UDP的协议。有很多基于UDP的协议,支持可靠性特性(比如RDP),但没有任何协议适用于异构系统的实时通信。本文提出一种新的UDP之上的可靠协议,特别为这样的系统而设计。
通常,当某人被问到网络需求,通常得到一个带宽形式的答案。这个答案是不完全的,对于实时系统来说。正如所见,节点间的通信可通过延时需求和消息大小分类。对于短消息,还有两个重要的描述通信的参数:消息数量和分布。
考虑一个1Gb的连接,仅用于发送和接收短消息。理论上,1Gb网卡每秒应该能处理超过2,000,000数据包(最小网络帧的大小是64字节),但是在实践中是远远达不到的。尽管某些特定的网卡可以处理这样数量的数据包,对于操作系统和应用程序来说都是一个真正的挑战。例如,2GHz处理器最多为每个数据包授予1000个周期,对于任务处理来说是非常短的时间。
消息的负载均衡也需要被考虑。例如,如果高度同步的多个客户端发送消息到服务器,更有可能在服务端丢失数据包。这样会导致数据包重新发送以及延时的上升。
网络规划
一旦我们完成了系统内通信的分类和选择传输协议,我们需要转到网络规划。我们需要测试当前的网络拓扑(如果不存在就新建一个),评估它是否可胜任通信需求。通常,实时系统有一个专用的网络处理实时通信。然而,这个网络在系统中可以在不同的模块之间共享,而这些模块可能有不同的性能需求。骨干网络必须足够强壮,来承载所有模块的通信需求。简化讨论,我们假定系统存在一个合适的骨干网络,我们的目标是解决它的利用率。
网络规划的下一步是分离不同类型的通信。例如,TCP和UDP不应该搞混。也应该区分不同延时需求的UDP通信。通过分离通信,我们降低了通信密度,因而减少了数据包冲突。同样也简化了网络分析。当然,最佳的分离是为每一中通信类型创建一个专用的物流连接(分离的网卡和节点之间分离的线路)。不过在许多情况下,由于预算和硬件限制,这样的分离是不可行的。这里,我们可以尝试通过时间分离通信。如果这是不可行的,那我们必须检测我们的通信,依据结果考虑实现一个满足网络需求的合适的协议。
UDP-RT协议
UDP-RT协议是基于UDP协议的,用于在实时通信中低延时地发送短消息,该协议具有可靠性的特点。形式上,UDP-RT协议需要满足下列要求:
1.低延时
·尽可能快的发送消息到目标
·尽可能快的接收和传递消息到应用程序
2.可靠性
避免丢失消息
·一旦消息丢失,检测并恢复它(恢复消息的时间取决于可靠性和低延时要求,因此协议要特变关注这个问题)
·处理消息重排序
除了上述功能要求之外,保持协议简单也是重要的。实时系统中的模块会运行嵌入的软件,是难以调试的。所以出于一些高级特性的设计目标以及实现的简单性,我们特意放弃了。不过,对于哪些对鲁棒性更感兴趣胜于简单性的人,在本文最后我们会讨论可行的协议扩展。
UDP-RT组件划分为三个模块:发送、接收和协议驱动。前两个负责高效的发送和接收消息。这些模块提供自定义选项,以在宿主系统上优化协议性能。协议引擎覆盖了以上清单中的可靠性需求。
|
UDP
|
|
|
↑
|
↓
|
|
接收模块
|
发送模块
|
|
↑
|
↓
|
|
协议引擎
|
|
|
↑
|
↓
|
|
应用程序
|
|
消息结构
每一个UDP数据报,包含若干UDP-RT协议的消息。消息不能在UDP数据报之间拆分,所以最大消息尺寸收到最大数据报的限制(64KB)。一个UDP-RT消息由头部和载荷组成。
|
0
|
4
|
8
|
16
|
|
主版本
|
次版本
|
消息类型
|
载荷长度
|
|
32
|
|||
|
ID
|
|||
|
64
|
|||
|
时间戳
|
|||
|
96
|
|||
|
预留
|
|||
|
128
|
|||
|
预留
|
|||
|
160
|
|||
·版本字段允许协议升级。在将来的版本中新功能可能被引入,版本字段帮助节点判断兼容性。最近版本是0.0。
·类型:可以是DATA(0x0)、ACK(0x1)和RESET(0x2)。DATA消息包含载荷。RESET消息重置消息计数器。ACK消息用于应答DATA和RESET消息的到达。RESET和ACK消息没有载荷。
·载荷长度定义了消息载荷中的字节数。
·ID是消息序列号,有发送者赋予DATA和RESET消息。ACK消息必须复制对应DATA和RESET消息中的ID。
·时间戳包含DATA和RESET消息的发送时间,由消息发送方填充。ACK消息必须复制对应的DATA和RESET消息中的时间戳。
信道设置
一对使用UDP-RT协议的节点作为UDP-RT连接,被称为信道。每一个信道有自己的参数,决定了UDP-RT的在信道上的表现。以下是一个信道配置参数的清单:
·初始重传超时-默认重传超时时间。详见“消息重传计时器”
·重传超时模式-协议引擎使用的计算重传超时的算法。详见“消息重传计时器”。
·最大消息延时-应用程序允许的最大消息传递时间。详见“消息重传定时器”。
·消息丢失策略-定义在“最大消息延时”超时之后如何处理消息。详见“消息重传定时器”。
·无序消息策略-定义是否允许信道上的无序消息。详见“消息重排序”。
·重置等待时间-重置过程需要等待的时间。详见“重置消息计数”。
协议引擎
丢失消息的检测和恢复
办法很简单。要知道是否消息到达了目标,需要等接收模块应答。发送者在内存中持有消息,在等待应答期间。一旦收到应答,消息就可以被丢弃。如果一段时间之内消息没有收到应答,就必须重传。
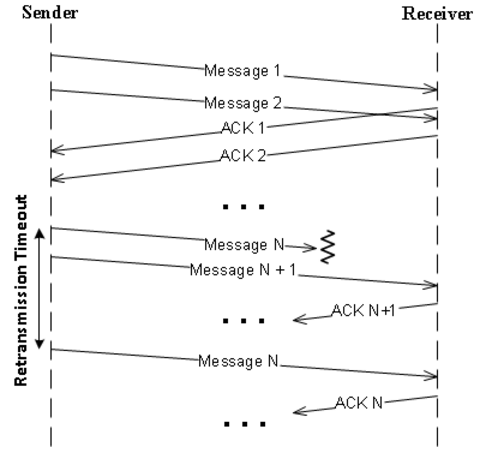
当应用程序执行发送操作,协议做如下动作。首先,分配一个ID给消息然后传递给发送模块,发送模块随后传输消息到目标。然后校正消息的重传时间,放入等待应答的队列(每个信道都有一个队列)。任何时候消息的重传时间超时后,协议引擎就重传消息(交给发送模块),给消息设置新超时时间。如果收到了应答,协议引擎被接收模块通知。检查消息应答队列,如果有消息的ID匹配上,就从队列中移除它,并通知应用程序发送成功(如果应用程序需要这样的通知)。

消息重排序
接收模块将收到的消息传递给协议引擎。如果是应答消息,就像上一节描述的那样处理。如果这是一个DATA消息,那就通知协议引擎。于是协议引擎就生成应答消息,传递给发送模块。然后存储接收到的消息,直到应用程序请求它。
接口引擎可能收到无序的消息,因为重传和路由(在封闭的实时系统中后者不大可能发生)。因此引擎将消息放到信道的堆(heap)上,按照消息的ID排序。引擎知道下一个到达的是什么消息,所以不会传递无序消息给应用程序,而是等待下一个有序的消息。当然,有的应用程序不关心接收到无序的消息,所以该行为是可配置的(无序消息策略out-of-order messages policy配置)。

消息重传计时器
计算定时器超时
UDP-RT协议定义了最大消息延时,作为应用程序允许的消息传递时间。消息延时是协议传输消息的时间;这个值取决于网络硬件和节点所在的操作系统表现。我们假设最大消息延时远超过消息平均延时,并且有充足的时间来重传。于是,重传计时器的超时时间就成为了协议配置中最重要的参数。要设置一个合理的重传超时时间,发送方统计平均消息RTT。往消息头写入时间戳,接收方复制时间戳到ACK消息,这样发送方在收到应答后就可以统计RTT。给定平均RTT后,重传超时时间可以设置为平均RTT+ε,ε是RTT跳动的补偿。既然消息RTT的分布可以考虑为常量,ε应该设置为2*δ,覆盖97%的RTT。平均RTT和ε可以在协议工作中统计,初始重传超时必须由应用程序设置(initial retransmission timeout设置),需要通过基准或理论计算得到该值。上面讨论的模型我们称之为平均RTT重传模型average RTT retransmission model。
平均RTT重传模型在信道数量相对较小时工作良好,消息丢失是随时间和信道发散的。确实,如果一些随机的消息丢失,协议会在平均RTT+ε超时之后回传它。现在考虑消息一再丢失的情况。一旦超过最大消息延时时间,协议不再重传消息,而是依据message dropping policy设置继续执行。该设置允许应用程序配置UDP-RT在消息超时时的行为;协议既可以沉默的丢弃这些消息,也可以声明一个系统错误。
拥塞控制
平均RTT重传模型在数据报的密度变大的时候变得危险。考虑多个客户端向服务端发送消息。网络活动可能会激增,导致明显的消息丢失和延时。结果是,在重传超时以后,客户端会尝试重新回传消息。如果没有超出负载,回传的消息会造成系统更多的负载,于是更多的消息会丢失和延时。最终,由于连绵不绝的负载,一些消息会到达maximun message delay。要处理这种状况,重要的是要明白消息超时是不大会发生的,是瞬时负载的结果。因此,要避免网络拥堵,需要减少网络的重传,让负载传递下去。这可以通过提高后续重传的超时时间来实现;例如,每两次重传就提升超时时间。我们称这样的超时模型为指数RTT重传模型exponential RTT retransmission model。注意,UDP-RT协议不能处理系统中的持续负载,或者像TCP一样控制消息发送速率。相反,协议假定在一般情况下系统是没有问题的,仅给系统一个故障后重回正轨的机会。
你可能会问为什么不用停止等待的方法,在收到最近消息的应答前推迟发送消息。尽管这种技术能避免网络溢出,但有它自身的缺陷。可能造成非必要的发送消息延时,并且这种延时可能累积,除非发送的速率远小于平均RTT时间。
QoS
UDP-RT协议不提供QoS机制。相反,它为确保消息的平均发送时间小于最大消息延时做了最大的努力。只要没有丢失消息,并且RTT小于最大消息延时,这是肯定正确的。一旦消息丢失或者延时,重发机制开始工作,于是如果若干信道共享同一个连接,先择一个信道而不是另一个是合理的(例如有一个信道的最大消息延时比其他信道的更小)。换句话说,有些信道相比其他信道可能要求更快的消息恢复。这可以通过给该信道分配更加侵略性的重传超时模型来做到。比如,给信道分配平均RTT重传模型。要决定何时的超时模型,你需要评估你的系统。我们将在协议扩展章节讨论更严格的QoS解决方案。
重置消息计数
默认的,发送者从0开始DATA消息的ID,以一个递增的序列分配ID给后续的消息。接受方将ID和消息一起传递给应用程序。应用程序可以随时重置计数器为任何值。重置特性通常由应用程序在开始新的处理序列或者避免消息ID溢出时使用。
当应用程序要求重置ID计数器,协议引擎丢弃所有待应答的消息,等待足够长的时间使得系统完成已发送消息的清理。等待时间是在信道的reset waiing time设置的。然后发送者发出RESET消息。接受者清空已收消息堆,重置接收ID计数器为请求的值。RESET消息和DATA消息的应答处理方式是一样的。RESET命令也会传递到接收应用程序,这样应用程序可以恰当的处理RESET通知。例如,它可能从协议引擎请求RESET,然后重置指定信道上两个方向的通信。
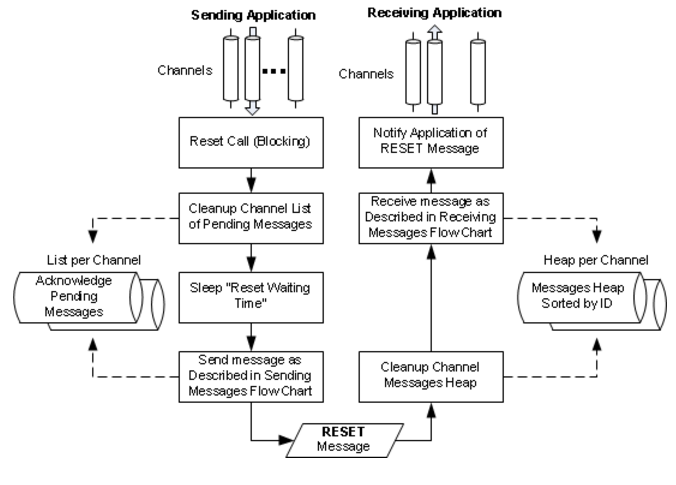
接收和发送模块
接收和发送模块负责在宿主操作系统上适配UDP-RT协议。这些模块运行在特定的线程中,操作socket。这一章,我们讨论这些模块的实现的不同方面,以及如何调试性能。
socket编程
回想一下,协议是工作在同步的socket之上的。同步的socket是低效的,但是低效是轻便的代价。接收和发送模块大多使用3个socket API:select、recvfrom和sento。实际上,接受者和发送者线程程序可以描述为:
Recever_Thread_Procedure() {
while(true) {
select(FD_SET);
foreach(s in FD_SET) {
recvfrom(message, addr);
notify_protocol_engine(message, addr);
}
}
}
Sender_Thread_Procedure() {
while(true) {
wait_for_msg_from_protocol_engine(message, addr);
sendto(message, addr);
}
}
让我们测试上面的伪代码的socket API的性能:
select-通常是一个昂贵的API,某些情况下它的执行可能耗时数十毫秒。要降低API的调用,每一个信道拥有自己的socket来和它的节点通信,因此select API可以一次应用到一组大量的socket。select的性能也受到同时调用它的线程数的影响。要处理它,接收模块允许定义接收线程的数量,给每一个线程分配自己的一组socket。
recvfrom-在select决定了数据包的socket之后,接收线程调用recvfrom API来检索它们。如果socket缓存里有数据报,recvfrom通常立即返回。在某些操作系统中如果不是这种情况,那recvfrom执行时间可能会成为UDP-RT协议的主要延时限制。
sendto-这个API通常执行迅速,但在某些情况下性能会恶化。例如在Windows XP中,多个线程同时调用sendto会显著降低API性能(尽管这些调用是在不同的socket上执行的)。因这个原因,发送模块提供一种定义发送线程数的机制,同样通过合并消息到一个数据报来减少sendto的调用。
另一个要考虑的是socket配置;例如,发送和接收的缓存大小。如果发送缓存太小,不能装下全部数据包,socket上的下一个sendto操作将被挂起,直到缓存被释放。接收缓存也会有同样的问题,如果接收socket缓存已经全部填充,新进的数据包会被丢弃。正如我们上面提到的,每一个信道有自己的socket,所以这些情况不大可能发生。然而,如果缓存有问题,你可以调用setsocket API来扩展他们。这样,你会让更多未处理的数据包堆积在缓存里。
接收线程
就像上面提到的,接收模块允许多个接收线程的运行。要选择一个最优的接收线程数,需要考虑许多参数:select和recvfrom性能、CPU数和核心数、网络端口数、信道数和信道延时需求。尽管正确的做法是系统检测,也有一些简单的准则。接收线程多次执行select,然后一个接一个处理socket,并分发消息到协议引擎。检索和分发消息不应该造成延时,这样线程就有足够的CPU处理这些任务。因此,作为开始,推荐在给定的电脑上创建和CPU核心数一致的接收线程。
发送线程
和接收模块相似,发送模块也允许调整发送线程数。最优的发送线程数应该通过检测得到,然而发送线程的处理不需要CPU,推荐从1个线程开始。
除此之外,该模块还要处理消息合并。每一个发送线程管理一个主发送请求队列,同时管理每个信道的消息队列。协议引擎将消息直接放到信道的队列,也将发送请求放到主线程队列中。每一个发送请求包含信道标识,因此当发送线程从主队列取出一个请求时,它知道从对应的信道队列中取出消息。如果发送线程开始累积延时,信道的队列也开始增长,所以当发送线程处理一个队列中有多个消息的信道时,它将它们合并到一个数据报。这样,发送线程减少调用昂贵的sendto API的次数,也获得一个在一段时间后赶上系统的机会。注意发送模块将消息合并作为最后的手段,来克服性能瓶颈,而不是作为优先操作,就像TCP的Nagle算法那样。
中断调节
UDP-RT设计要解决的一个问题是大量的数据包在网络上传输。尽管协议引擎,和发送模块都配置好了,大数量的数据包对于操作系统来说也是一大问题。例如Windows XP中,每一个UDP数据包在接收之后触发中断,然后操作系统创建deffered procedure call(DPC)。问题在于Windows XP在同一个核心上处理所有的DPC,所以一旦接收到大量的数据包,操作系统在数据包的处理上成为一个严重的瓶颈。幸运的是,现代网卡允许调节它们创造的中断。因此,如果你的UDP-RT体验降低了,分析中断性能(例如,运行Thesycon DPC Latency Checker),然后如果有需要就使用中断调节。
案例研究
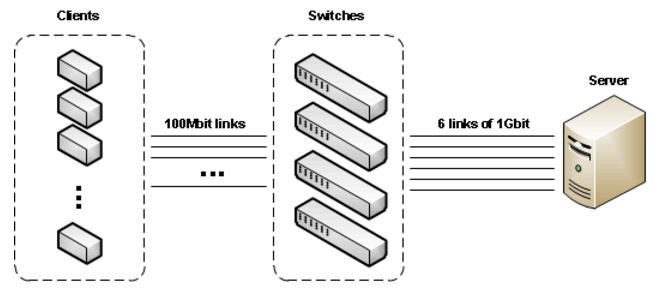
要检测UDP-RT协议,一个特定的环境被创建。该环境模拟客户端-服务端系统,由700个拥有100MBit以太网卡的客户端、网络交换机和拥有2个2.33GHz CPU(每个4核心)的Intel服务器组成。客户端通过若干级联的交换机,连接到服务端的6个1Gbit网卡。
UDP-RT性能可通过消息的平均RTT衡量。如果RTT远小于最大消息延时,就说明协议在系统上运行良好。尽管,某些情况下RTT参数不可确信。RTT可能很高,并且它的值波动很大。另一个参数可用来衡量UDP-RT性能:应答消息队列的平均长度。该参数在高延时的系统中特别有用,很好的给出了网络的稳定性的度量。
服务端接收客户端的消息,针对每个消息做一些统计,然后发送结果,所以两个方向的消息数量是对等的。这没有算UDP-RT为每个DATA消息发送的ACK消息。在我们的环境中,我们注意到服务端到客户端的方向没有任何信息丢失,因此UDP-RT变更为不从客户端发送ACK消息。这样就降低了客户端到服务端方向的传输密度,这经常是消息延时和丢失发生的方向。
如果所有的客户端每3毫秒发送消息,那么总共,算上ACK消息,服务端每秒钟收到130000个消息,发送260000个消息到客户端。等同于每7.7微秒接收一个消息,每3.85微秒发送一个消息。客户端的消息是以太网MTU的尺寸(1.5KB)。服务端的消息要小的多,不超过100字节。ACK消息长度是20字节,因此总的通信带宽需求大概是2.2Gbit,不超过服务器上可用带宽的一半(6个1Gbit端口)。
UDP-RT协议在服务端经过了两个操作系统的测试:Window XP专业版和Windows 7旗舰版。Windows XP可成功处理50000消息输入和100000消息输出。接收消息的平均RTT是10毫秒,应答消息队列的平均长度是7。每秒中客户端重发几十条消息。对于输出消息,RTT和队列长度测量不可用,因为我们废除了客户断ACK消息。Windows XP的结果如下:
| 每秒接收消息 | 平均RTT(毫秒) | 最大RTT(毫秒) | 平均消息队列长度 | 最大消息队列长度 |
| 50000 | 10 | 50 | 7 | 33 |
增加输入消息的数量将导致RTT时间的显著增长,以及未应答消息队列的溢出,该队列的大小被限定为50。而且,尽管接收50000输入消息,系统变得十分不稳定,测量结果每隔几秒钟就会跳动。
必须提到,为了实现上面的结果,做了若干校准来调试UDP-RT接收和发送模块。在最终配置中,我们使用了网卡上允许的最大重中断调制,接收模块拥有6个接收线程,发送模块仅配置为运行1个线程。
然而,Windows 7显示出可靠的性能。系统成功的处理130000输入和260000输出消息,在几分钟的时间里只有微小的RTT和队列长度测量波动。没有发现任何消息重传。我们将这结果归因为Windows 7的receive-side scaling(RSS)技术。结果如下:
| 每秒接收消息 | 平均RTT(毫秒) | 最大RTT(毫秒) | 平均消息队列长度 | 最大消息队列长度 |
| 130000 | 14 | 31 | 8 | 9 |
Window 7的发送和接收模块配置,和我们在Windows XP中使用的是相同的。进一步调试配置可能带来更好的结果。
UDP-RT的可能扩展
捎带ACK消息
UDP-RT最大的挑战是减少网络中的数据包数。在我们上面的案例学习中,我们确定网络路径是可靠的,取消了对应的ACK消息。此外,更通用的减少数据包的做法是,在包含DATA消息的数据包中捎带ACK消息。这样,接受者在收到DATA消息后不会立即发送ACK,而是延后再发送。如果有DATA消息要传输到同一节点,就合并消息到同一个数据报。接收者要知道应答会被延迟多久。如果延时太久,DATA消息可能被重传。要克服此问题,发送节点要告诉接收者,是否允许推迟ACK消息,推迟多久。这可通过在DATA消息头部添加一个超时时间来实现。这个超时应该根据回传超时模型和最大消息延时参数计算。例如,averange RTT retransmission model不允许过多的应答延时,所以发送方需要通过δ来增加重传时间,在DATA消息头中传递δ。接受方将等待,至多δ时间,等捎带信息的机会。此外,接受者需要添加实际的ACK消息延时到ACK头部,这样发送者可以提取对应DATA消息的RTT时间。其他的捎带ACK消息的方案也是可能的。
发送和接收模块的QoS
在上面的章节中已经提到,不同的消息恢复机制,是UDP-RT协议实现QoS的基础。此问题的另一个方法是在接收和发送模块中实现严格的QoS模型。毕竟,接收模块线程是工作在socket之上的,所以特定的socket可以被放到独立的集合中赋予更高的优先级,并更加频繁的进行采样。例如,可以通过加权循环算法来采样。类似的,发送模块中的发送请求队列可以划分为若干队列,可以以不同的方式采样。
在发送和接收模块中实现QoS,并没有替换不同信道各自被赋予的恢复机制。既然底层操作系统和网络设备不支持QoS,数据包可能丢失或延时,因此管理不同的恢复机制是克服此限制的核心。
总结
实时通信离“plug-and-play”还相差很远。本文试着系统分析TCP/IP协议在实时通信上的应用,提出新的可靠的协议,在标准的TCP/IP组件无法系统所需性能的地方。
Michael Pan
2011-11-15