一、速补基础
1、什么是metrics
缺省是在http(s)的url的/metrics输出。 而metrics要么程序定义输出(模块或者自定义开发),要么用官方的各种exporter(node-exporter,mysqld-exporter,memcached_exporter…)采集要监控的信息占用一个web端口然后输出成metrics格式的信息,prometheus server去收集各个target的metrics存储起来(tsdb)。 用户可以在prometheus的http页面上用promQL(prometheus的查询语言)或者(grafana数据来源就是用)api去查询一些信息,也可以利用pushgateway去统一采集然后prometheus从pushgateway采集(所以pushgateway类似于zabbix的proxy),
k8s的资源指标分类:
资源指标:metrics-server内建API
自定义指标:prometheus来采集,需要组件k8s-prometheus-adapter
一、核心指标获取
metrics-server:API server
--- kubectl api-versions 中默认不包含metrics.k8s.io/v1beta1;使用时需要添加kube-aggregator前缀
--- metrics部署文件:https://github.com/kubernetes-sigs/metrics-server
下载到本地并应用之后就可以使用kubectl api-versions查询,查到metrics.k8s.io/v1beta1已经存在
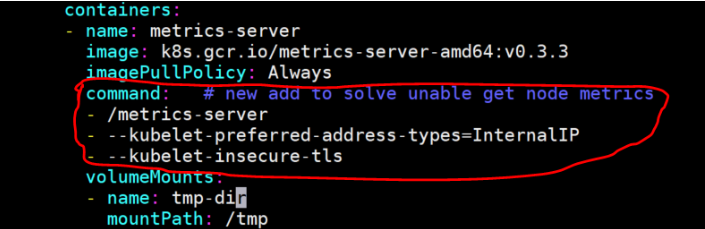
应用之前需要修改metrics-server-deployment.yaml文件,添加如下:
Warming: metrics-server这个容器不能通过CoreDNS 10.96.0.10:53 解析各Node的主机名,metrics-server连节点时默认是连接节点的主机名,需要加个参数,让它连接节点的IP:“–kubelet-preferred-address-types=InternalIP”
因为10250是https端口,连接它时需要提供证书,所以加上–kubelet-insecure-tls,表示不验证客户端证书,此前的版本中使用–source=这个参数来指定不验证客户端证书
执行kubectl apply -f
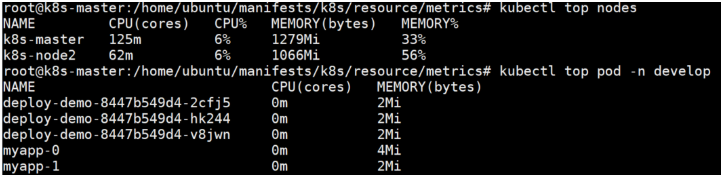
使用kubectl top nodes查看
二、自定义指标 --- Prometheus
♦ node_exporter用来暴露node信息,还有其他的exporter
♦ PromQL查询语句,不能直接被k8s直接解析,需要通过kube-state-metrics组件转k8s-promethues-adapter转为Custom Metrics API
三、prometheus-operator部署
声明式API:
在Kubernetes中我们使用Deployment、DamenSet、StatefulSet来管理应用Workload,使用Service、Ingress来管理应用的访问方式,使用ConfigMap和Secret来管理应用配置。我们在集群中对这些资源的创建,更新,删除的动作都会被转换为事件(Event),Kubernetes的Controller Manager负责监听这些事件并触发相应的任务来满足用户的期望。这种方式我们成为声明式,用户只需要关心应用程序的最终状态,其它的都通过Kubernetes来帮助我们完成,通过这种方式可以大大简化应用的配置管理复杂度
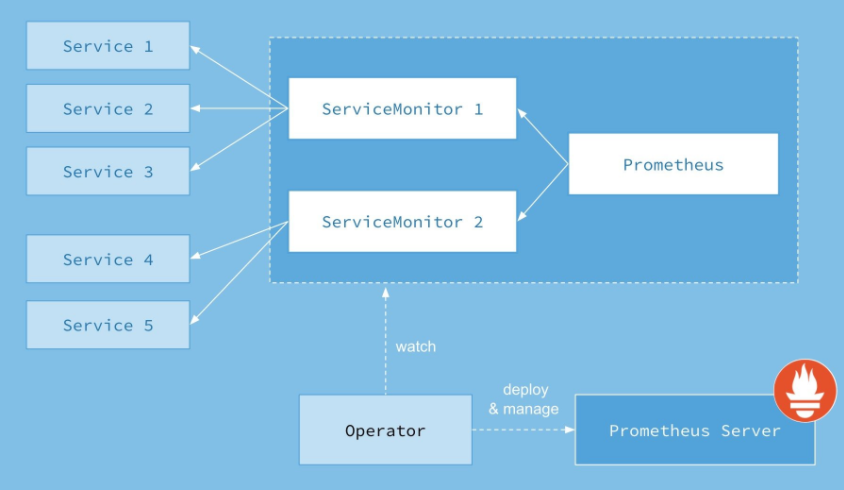
因为svc的负载均衡,所以在K8S里监控metrics基本最小单位都是一个svc背后的pod为target,所以prometheus-operator创建了对应的CRD: kind: ServiceMonitor ,创建的ServiceMonitor里声明需要监控选中的svc的label以及metrics的url路径的和namespaces即可
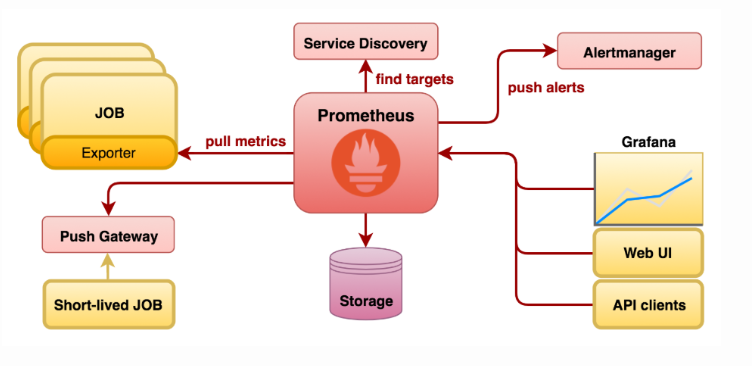
工作架构如下图所示。
下载项目:
git clone https://github.com/coreos/prometheus-operator.git
拉取到文件后我们先创建prometheus-operator:
$ cd prometheus-operator $ kubectl apply -f bundle.yaml clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created clusterrole.rbac.authorization.k8s.io/prometheus-operator created deployment.apps/prometheus-operator created serviceaccount/prometheus-operator created
确认pod运行,以及我们可以发现operator的pod在有RBAC下创建了一个APIService:
$ kubectl get pod NAME READY STATUS RESTARTS AGE prometheus-operator-6db8dbb7dd-djj6s 1/1 Running 0 1m $ kubectl get APIService | grep monitor v1.monitoring.coreos.com 2018-10-09T10:49:47Z
Prometheus Operator引入的自定义资源包括:
- Prometheus
- ServiceMonitor
- Alertmanager
这四个CRD作用如下
- Prometheus: 由 Operator 依据一个自定义资源
kind: Prometheus类型中,所描述的内容而部署的 Prometheus Server 集群,可以将这个自定义资源看作是一种特别用来管理Prometheus Server的StatefulSets资源。 - ServiceMonitor: 一个Kubernetes自定义资源(和
kind: Prometheus一样是CRD),该资源描述了Prometheus Server的Target列表,Operator 会监听这个资源的变化来动态的更新Prometheus Server的Scrape targets并让prometheus server去reload配置(prometheus有对应reload的http接口/-/reload)。而该资源主要通过Selector来依据 Labels 选取对应的Service的endpoints,并让 Prometheus Server 通过 Service 进行拉取(拉)指标资料(也就是metrics信息),metrics信息要在http的url输出符合metrics格式的信息,ServiceMonitor也可以定义目标的metrics的url。 - Alertmanager:Prometheus Operator 不只是提供 Prometheus Server 管理与部署,也包含了 AlertManager,并且一样通过一个
kind: Alertmanager自定义资源来描述信息,再由 Operator 依据描述内容部署 Alertmanager 集群。 - PrometheusRule:对于Prometheus而言,在原生的管理方式上,我们需要手动创建Prometheus的告警文件,并且通过在Prometheus配置中声明式的加载。而在Prometheus Operator模式中,告警规则也编程一个通过Kubernetes API 声明式创建的一个资源.告警规则创建成功后,通过在Prometheus中使用想servicemonitor那样用
ruleSelector通过label匹配选择需要关联的PrometheusRule即可。