数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。以下是三种常用的归一化方法:
min-max标准化(Min-Max Normalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 , 1]之间。转换函数如下:
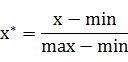
其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
from sklearn import preprocessing import numpy as np X = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]]) min_max_scaler = preprocessing.MinMaxScaler() X_minMax = min_max_scaler.fit_transform(X)
结果:
array([[ 0.5 , 0. , 1. ], [ 1. , 0.5 , 0.33333333], [ 0. , 1. , 0. ]])
找大小的方法直接用np.max()和np.min()就行了,尽量不要用python内建的max()和min()
Z-score标准化方法
也称为均值归一化(mean normaliztion), 给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1。转化函数为:
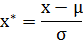
mu(即均值)用np.average(),sigma(即标准差)用np.std()即可.
def Z_ScoreNormalization(x,mu,sigma): x = (x - mu) / sigma; return x; b = np.array([[1,2,3],[4,5,6]]) print(Z_ScoreNormalization(b,b.mean(),b.std()))