mysql 三高
高并发:同时处理的事务数高
高性能:事务/SQL的执行速度高
高可用:系统可用的时间高
如何实现三高
高并发:通过复制和扩展,将数据分散至多个节点
高性能:复制提升速度,扩展提升容量
高可用:节点间身份切换保证随时可用
实现三高的手段
复制
目的:数据冗余
手段:binlog传送
收货:并发量提升、可用性提高
问题:占用更多硬件资源
扩展
目的:扩展数据库容量
手段:数据分片分库、分表
收货:性能、并发量提升
问题:可能降低可用性
切换
目的:提高可用性
手段:主从身份切换
收货:并发量提升
问题:丢失切换时
演进

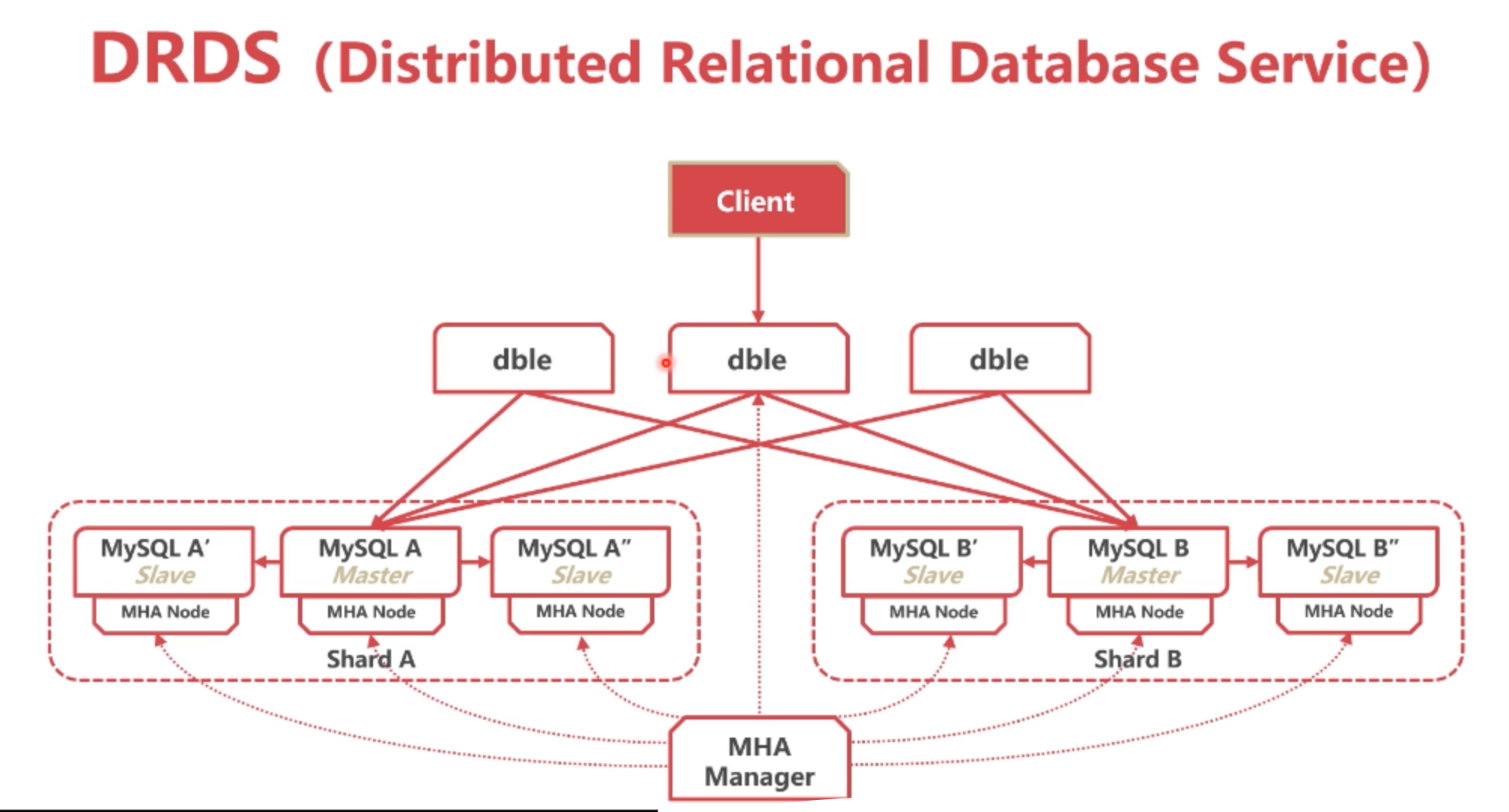
dble分了两个数据分片,每个数据分片都是一个独立的数据库集群,一主两备,MHA manager负责管理每一片的主备的健康,如果有问题的话,MHA manager负责主备的切换,而且MHA manager在主备切换的时候会通知DBLE,让DBLE的流量导到新上来的主库上去。这个架构在很多公司或者云服务厂商叫作DRDS,分布式数据库服务。在几年前比如在阿里云买DRDS服务,现在阿里云没有这个服务了,其实阿里云就是提供一个类似架构的mysql集群。
问题:这么一个架构,说挂就挂!
因为有一个单点问题,DBLE是单点的,比如DBLE宕机了,下面的数据库再健壮也没用,因为客户端连接的是DBLE,业务永远不可能只连接MYSQL A或者MYSQL B,因为MYSQL分库分表了,MYSQL A或者MYSQL B永远都是一部分数据,所以业务直接连上没有意义,必须通过DBLE,而DBLE单点的问题就是成了这个系统架构最薄弱的点。

搭建多个DBLE,每个DBLE都做相同的配置,配置它连接MYSQL A和MYSQL B,然后每个DBLE都可以独立的访问,这样其实不可以!因为分库分表了,虚拟表和虚拟数据库的信息是存在DBLE上的,进一步说每个表按照什么列分配的,比如按时间,三年前的放在A库,三年后的放在B库,这个信息怎么分,元数据是放在DBLE上,现在DBLE一个变成多个,它们之间的元数据如何同步?很难同步!比如业务要新建一个表,新的表的数据是存在DBLE上的,比如有什么字段,怎么分表,都是存在DBLE上,比如客户端连接的是第一个DBLE,第一个DBLE记录了创建新表,但另外两个不知道,下次别的客户端连接另外两个DBLE,另外两个DBLE都不知道有新表创建,所以说多个DBLE之间的数据是需要同步的,比如让一个DBLE当主DBLE,其中的当备DBLE,可不是不可以,但DBLE可以借助zookeeper,zookeeper是一个经典的分布式协调服务,这个服务可以保存很多数据和元数据,而且在保存数据量不大的时候可以做到高可用,而且不需要DBLE从主复制到备的问题,任何的元数据都存到zookeeper上,遇到任何元数据的问题都从zookeeper拉回来,这样就用zookeeper存储表信息、分片等信息,当客户端在其中一个DBLE上创建新表插入了新数据或者修改了表的元数据的时候,DBLE会把数据存储到zookeeper集群里,然后另外的DBLE在需要元数据的时候,从zookeeper集群获取,这样就完美解决了多个DBLE节点数据同步问题。
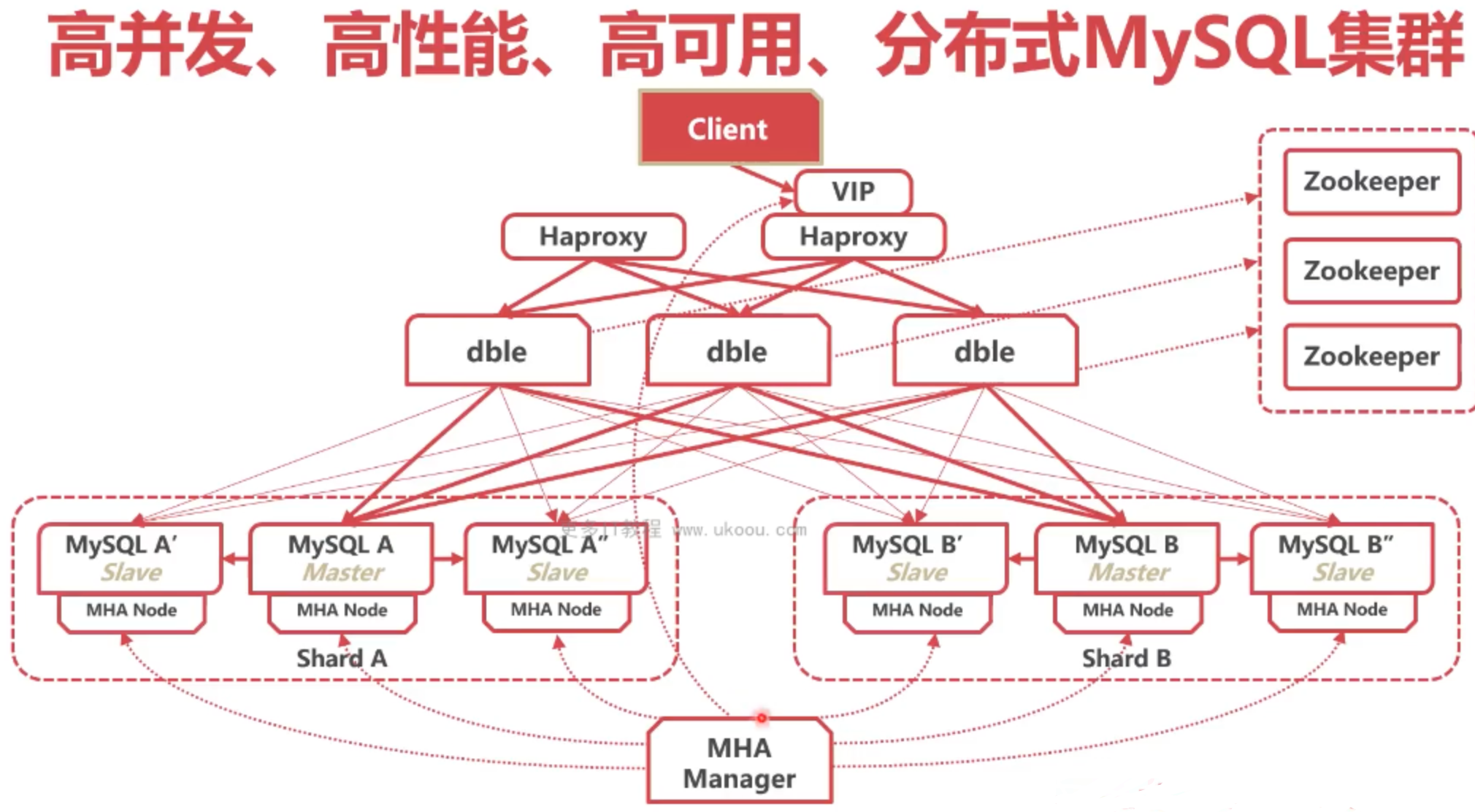
那为什么MYSQL 不能用zookeeper做数据同步?因为用zookeeper做数据同步代价非常大、性能非常差,因为MYSQL数据大,几个G的。
但现在看还有一些问题,比如如何实现负载均衡,比如有多个业务应用,分摊开DBLE上,人为分散开。业务是可以分散开,但是有个问题,MHA manager怎么分散开,MHA manager需要知道DBLE的IP,给MHA一个DBLE IP可以,但MHA manager修改MYSQL的主从IP信息的时候,它调一个DBLE,DBLE会把信息存储在zookeeper,别的DBLE也会知道,但配置在MHA manager上IP 所属的DBLE挂了呢,MHA manager就找不到DBLE了,如果主备切换了的话,MHA manager就不知道告诉谁了,因为MHA manger只能配置一个DBLE IP,但是脚本里只能配一个,也可以配置多个,但是很麻烦,有点多余!
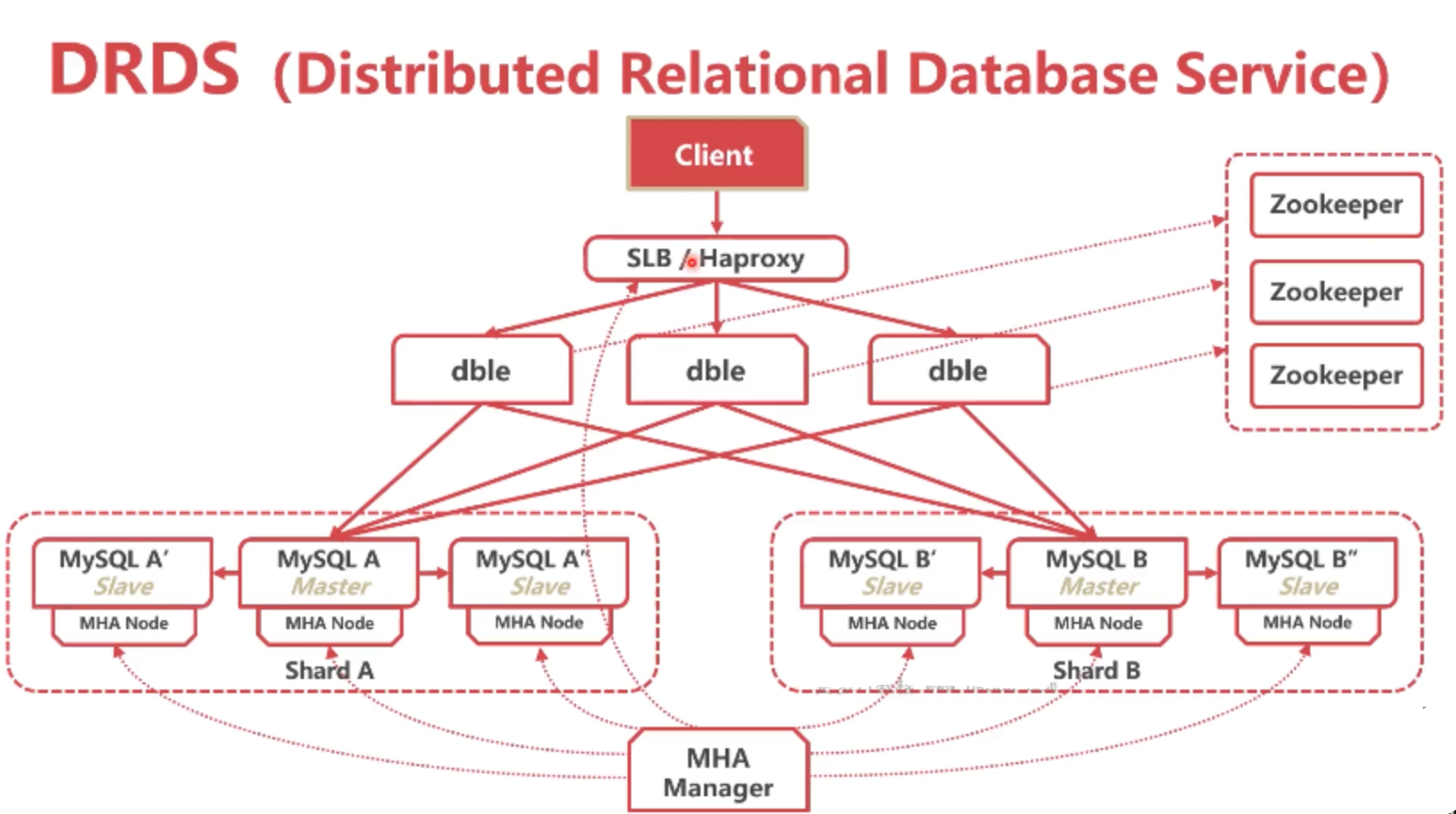
用keepalived可以实现,把每一个DBLE挂一个VIP,就是虚拟IP,这个虚拟IP供给MHA manager使用,也可以给客户端使用,就好比客户端和MHA manager都连接这个IP,DBLE上都安装keepalived,如果其中一个DBLE挂了,那么两边的keepalived会自动选择一个优先级高的,把VIP拽过来,也就是说同样的一个IP,之前绑定在宕机之前的服务器上,转移之后会绑定在另外正常的优先级高的服务器上,这样的话客户端和MHA manager在调用DBLE的时候,会不知不觉中调用新的DBLE。

但这种架构也有问题,对于MHA manager没问题,它能找到DBLE就可以,但对于客户端来说,所有的客户端都连接一个VIP,所有的压力都压在一个DBLE身上,业务量大的话,被切换后的DBLE还会挂,业务流高峰不敢保证单点不被冲垮。这时候引用SLB或者HaProxy。
SLB是各个云服务厂商都提供的负载均衡服务,保证SLB负载均衡器的高可用,我们不用管它,我们只需要告诉它把进来的请求分发到哪几个服务器就可以,然后云服务厂商会给我们提供一个SLB的IP,我们所有的业务配置这个SLB的IP,它会给我们转发到三个DBLE。假如你想自己搭的话,也可以用HaProxy,但HaProxy会占用一台服务器,HaProxy作为负载均衡器,所有的业务都调用HaProxy,然后转发给三个DBLE,这样就解决了多个DBLE负载不均衡问题,避免了单点宕机。用HaProxy就要面临自己解决单点失效的问题,因为这时候HaProxy也是单点,这个单点失效的问题往往要把单点变为多点,这样需要搞多台HaProxy服务器,然后HaProxy再装Keepalived,用HaProxy+keepalived这种经典架构来保证负载均衡器的高可用。也就是keepalived先把VIP绑定在其中一台负载均衡器上,然后这台负载均衡器挂了的话,keepalived会把VIP自动转移到另一台负载均衡器,客户端就会走另一台负载均衡器,负载均衡器就会客户端均衡负载到多个DBLE上,多个DBLE再把请求转发给两个数据分片上。
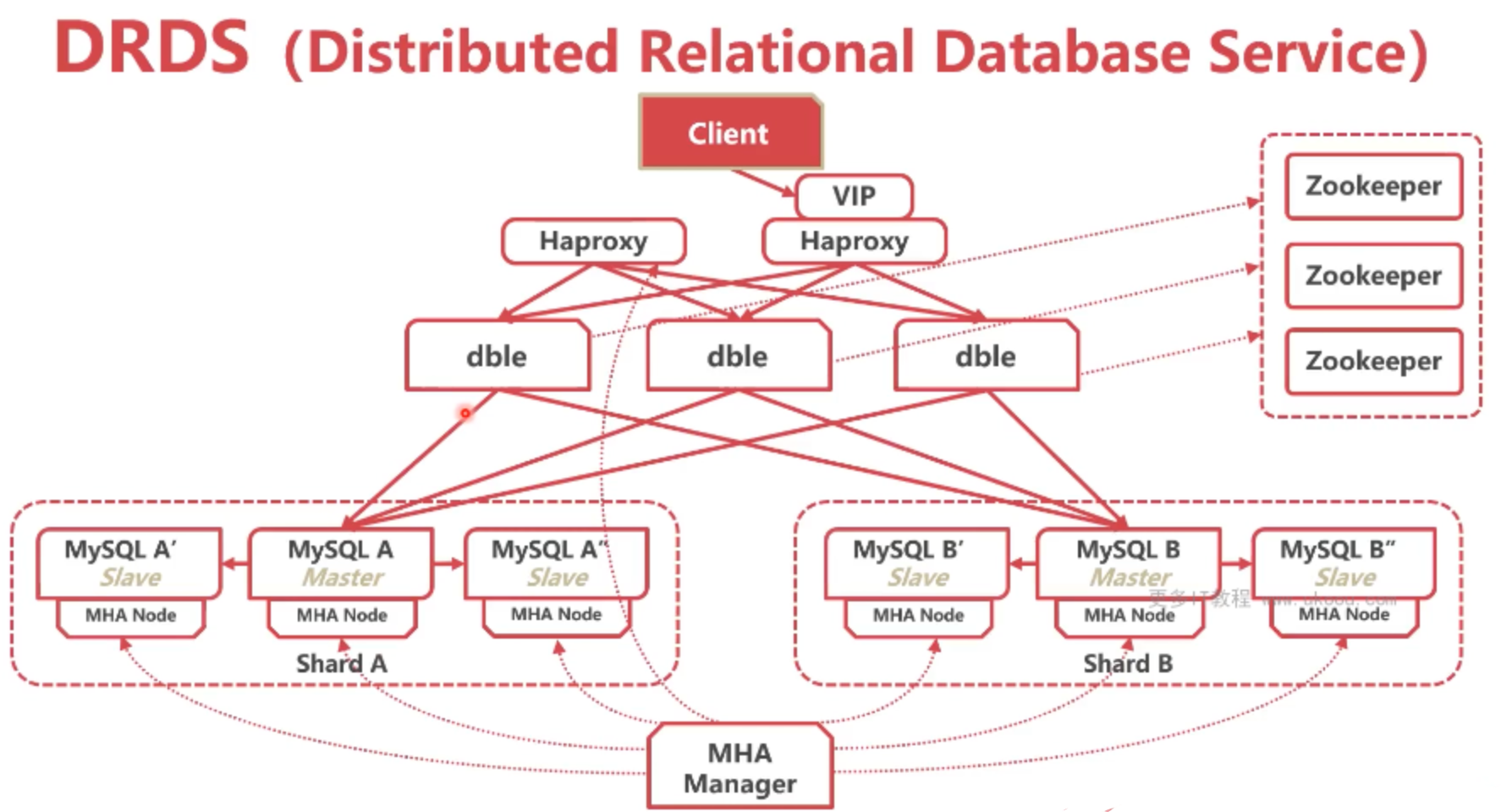
然后Mysql再实现读写分离!也就是DBLE现在都是走的主库,然后加上配置读写分离,配置好多个DBLE就可以读走备库、增删改走主库,这样就行程了一个高性能、高可用、高并发的架构集群!