

1.dp 基本思路
dp 题基本这么几个步骤:
- 定义状态。
- 写出状态转移式。
- 根据状态转移式找出递推顺序。
- 处理递推的边界。
- 找出结果。
我讲解时不会就题论题,而是讲大部分黄绿难度的 dp 题的方法。
当然,dp 题十分灵活,不会看完这篇题解就会做,关键在于大量的练习。
2.状态定义
定义状态是 dp 最重要的步骤之一,状态定义得不好后面全都无法进行。
像这种线性动态规划,定义经常是“fi 表示前 i 个满足要求时的答案”。
因为这道题有两个串,很容易想到状态的定义是“fi,j 表示 a 串的前 i 个碱基和 b 串的前 j 个碱基的相似度”。
3.转移式
通常定义出状态之后转移式就十分好写了。转移式通常只需要考虑最后一点,比如这道题只用考虑最后一对碱基。
最后一对碱基只有以下3种可能:
- 非空碱基和非空碱基。
- 非空碱基和空碱基。
- 空碱基和非空碱基。
注:空碱基和空碱基不能匹配。
去掉最后一对碱基,转化成规模更小的同样的问题,就是转移式的意义。易得如下转移式:
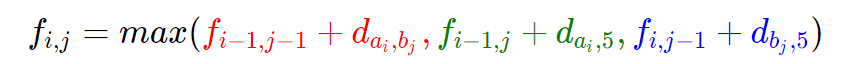
其中 di,j 表示编号为 i 的碱基和编号为 j 的碱基的相似程度,编号为5的是空碱基,ai 表示第一个基因的第 i 个碱基,b 表示第二个基因的第 i 个碱基。
其中红色代表第一种情况的转移,绿色代表第二种,蓝色代表第三种。
如果还不能明白,就看下面的图吧:

4.递推顺序
这步通常挺简单的,看看下标是变大还是变小。如果你要滚动数组的话(这题好像不能用滚动数组),递推顺序就会难一些。
显然,转移时下标不会变大,为了无后效性,应该从小到大递推。至于先枚举 i 还是 j,并不重要。
5.边界
递推顺序找到,边界就很容易找到了。
既然下标都是不变或变小,那边界就是至少有一个下标为0。如果一个下标为0,另一个下标不为0,上面3种转移只有一种有效,即:
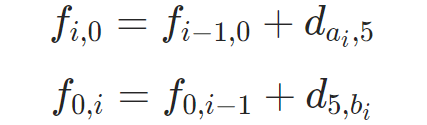
如果两个下标都为0,也就是 f0,0,三个转移都会失效。我们应该按照定义赋给它值:0个碱基和0个碱基的相似度应为0。所以得到最后一个式子:
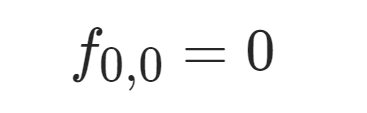
6.结果
这道题的结果很好找,就是 ,但是有些题的结果还得在多个数中找,比较麻烦。
,但是有些题的结果还得在多个数中找,比较麻烦。
7.实现
5个步骤的思维顺序如上,但是代码顺序略有不同,大概是这样的:
- 状态定义。
- 输入。
- 递推边界。
- 递推顺序。
- 状态转移式。
- 找出结果。
AC_Code
1 #include <iostream> 2 #include <cstdio> 3 #include <string> 4 #include <cstring> 5 #include <string> 6 #include <cmath> 7 #include <cstdlib> 8 #include <algorithm> 9 using namespace std; 10 typedef long long ll; 11 const int maxn = 205; 12 const int inf=0x3f3f3f3f; 13 const ll mod=1e9+7; 14 15 const int tab[6][6]={ 16 {0,0,0,0,0,0}, 17 {0,5,-1,-2,-1,-3}, 18 {0,-1,5,-3,-2,-4}, 19 {0,-2,-3,5,-2,-2}, 20 {0,-1,-2,-2,5,-1}, 21 {0,-3,-4,-2,-1,0} 22 }; 23 24 int la,lb; 25 char sa[maxn],sb[maxn]; 26 int a[maxn],b[maxn]; 27 int dp[maxn][maxn]; 28 29 int main() 30 { 31 scanf("%d",&la); 32 scanf("%s",sa); 33 scanf("%d",&lb); 34 scanf("%s",sb); 35 //// printf("%s",sa); 36 //// printf("%s",sb); 37 for(int i=1;i<=la;i++){ 38 for(int j=1;j<=lb;j++){ 39 dp[i][j]=-inf; 40 } 41 } 42 43 for(int i=1;i<=la;i++){ 44 if( sa[i-1]=='A') a[i]=1; 45 if( sa[i-1]=='C') a[i]=2; 46 if( sa[i-1]=='G') a[i]=3; 47 if( sa[i-1]=='T') a[i]=4; 48 } 49 50 for(int i=1;i<=lb;i++){ 51 if( sb[i-1]=='A') b[i]=1; 52 if( sb[i-1]=='C') b[i]=2; 53 if( sb[i-1]=='G') b[i]=3; 54 if( sb[i-1]=='T') b[i]=4; 55 } 56 57 dp[0][0]=0; 58 for(int i=1;i<=la;i++){ 59 dp[i][0]=dp[i-1][0]+tab[a[i]][5]; 60 } 61 for(int i=1;i<=lb;i++){ 62 dp[0][i]=dp[0][i-1]+tab[5][b[i]]; 63 } 64 for(int i=1;i<=la;i++){ 65 for(int j=1;j<=lb;j++){ 66 dp[i][j]=max(dp[i-1][j-1]+tab[a[i]][b[j]],max(dp[i-1][j]+tab[a[i]][5],dp[i][j-1]+tab[5][b[j]])); 67 } 68 } 69 printf("%d ",dp[la][lb]); 70 return 0; 71 }