1.索引:
select * from emp; -- 1.自动创建索引:Oracle 会自动为主键和唯一键创建索引 --- 自动创建的索引无法手动删除,只有在删除主键或唯一键时,对应的索引一并删除 alter table emp add constraint enam_uiq unique (ename); alter table emp drop constraint enam_uiq -- 2.手动创建索引:对于查询条件中经常使用到的查询字段可以添加索引 create index index_name on emp(ename) -- index_name:索引名称,emp:表名, ename:索引字段 --删除索引:只能删除手动添加的索引 drop index index_name
2.视图:视图(view),也称虚表, 不占用物理空间,这个也是相对概念,因为视图本身的定义语句还是要存储在数据字典里的。视图只有逻辑定义。每次使用的时候,只是重新执行SQL。视图是从一个或多个实际表中获得的,这些表的数据存放在数据库中。那些用于产生视图的表叫做该视图的基表。一个视图也可以从另一个视图中产生。视图的定义存在数据库中,与此定义相关的数据并没有再存一份于数据库中。通过视图看到的数据存放在基表中。
作用:
1)提供各种数据表现形式, 可以使用各种不同的方式将基表的数据展现在用户面前, 以便符合用户的使用习惯(主要手段: 使用别名);
2)隐藏数据的逻辑复杂性并简化查询语句, 多表查询语句一般是比较复杂的, 而且用户需要了解表之间的关系, 否则容易写错; 如果基于这样的查询语句创建一个视图, 用户就可以直接对这个视图进行"简单查询"而获得结果. 这样就隐藏了数据的复杂性并简化了查询语句.这也是oracle提供各种"数据字典视图"的原因之一,all_constraints就是一个含有2个子查询并连接了9个表的视图(在catalog.sql中定义);
3)执行某些必须使用视图的查询. 某些查询必须借助视图的帮助才能完成. 比如, 有些查询需要连接一个分组统计后的表和另一表, 这时就可以先基于分组统计的结果创建一个视图, 然后在查询中连接这个视图和另一个表就可以了;
4)提供某些安全性保证. 视图提供了一种可以控制的方式, 即可以让不同的用户看见不同的列, 而不允许访问那些敏感的列, 这样就可以保证敏感数据不被用户看见;
5)简化用户权限的管理. 可以将视图的权限授予用户, 而不必将基表中某些列的权限授予用户, 这样就简化了用户权限的定义。
语法: create [ or replace ] [ force ] view [schema.]view_name
[ (column1,column2,...) ]
as
select ...
[ with check option ] [ constraint constraint_name ]
[ with read only ];
tips:
1 or replace: 如果存在同名的视图, 则使用新视图"替代"已有的视图
2 force: "强制"创建视图,不考虑基表是否存在,也不考虑是否具有使用基表的权限
3 column1,column2,...:视图的列名, 列名的个数必须与select查询中列的个数相同; 如果select查询包含函数或表达式, 则必须为其定义列名.此时, 既可以用column1, column2指定列名, 也可以在select查询中指定列名.
4 with check option: 指定对视图执行的dml操作必须满足“视图子查询”的条件即,对通过视图进行的增删改操作进行"检查",要求增删改操作的数据, 必须是select查询所能查询到的数据,否则不允许操作并返回错误提示. 默认情况下, 在增删改之前"并不会检查"这些行是否能被select查询检索到.
5 with read only:创建的视图只能用于查询数据, 而不能用于更改数据.
-- ===========================视图========================================= --视图,就是一个虚表,可以用这个表查询数据 --视图,就是一个命名的查询语句。可以对表字段数据分权 -- 视图主要是用来做查询的,不能做DML操作,对视图的DML操作会影响原表数据 -- 1.创建一个名为hr_emp的视图 create or replace view v_hr_emp as select * from emp -- 2.创建项目mgr_emp create or replace view v_mgr_emp as select empno,ename,job,mgr,deptno from emp
-- 查询视图:
select * from v_mgr_emp
-- 删除视图,不会影响原来表数据 drop view v_mgr_emp;
---查询目前每个岗位的平均工资、工资总和、最高工资和最低工资。此时创建视图就必须制定列名
create or replace view vw_emp_job_sal(job,avgsal,sumsal,maxsal,minsal) as select job,avg(sal),sum(sal),max(sal),min(sal) from emp group by job
存储函数:
create or replace function get_sal(dpno number) return number is v_sumSal number(10):=0; Cursor sal_cursor is select sal from emp where deptno=dpno; begin for c in sal_cursor loop v_sumSal:=v_sumSal+c.sal; end loop; return v_sumSal; end;
存储过程:
/** 对给定部门(作为参数)的员工进行加薪,在职时间为(?,95)期间,加薪 5% (95,98)期间,加薪 3% (98,?)期间,加薪 1% 得到以下返回结果:此次加薪,公司需要额外付出的成本 ,定义一个out类型的输出变量 */ create or replace procedure add_sal(dept_id number,tem_sal out number) is v_i number(4,2):=0; cursor sal_cursor is select empno,sal,hiredate from emp where deptno = dept_id; begin tem_sal:=0; for c in sal_cursor loop if to_char(c.hiredate,'yyyy') <'1995' then v_i:=0.05; elsif to_char(c.hiredate,'yyyy')<'1998' then v_i:=0.03; else v_i:=0.01; end if; --1.更新工资 update emp set sal = sal*(1+v_i) where empno = c.empno; --2.付出成本 tem_sal:=tem_sal + v_i * c.sal; end loop; dbms_output.put_line(tem_sal); end;
调用以上的存储过程,在plsql命名中输入ed,

进入Text editor界面:
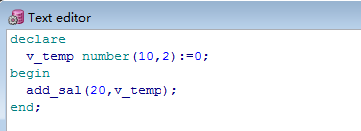
在sql命令中输入 /,得到存储过程结果
