1、传输层
从宏观上来讲,传输层 (Transport Layer) 提供逻辑上的 进程间的 (process-to-process) 数据传输服务
从微观上来讲,传输层连接着应用层和网络层,具体来说包括以下两个作用:
- 在发送数据时,将来自应用层的消息 (message) 封装成数据段 (segment),然后传递给网络层
- 在接收数据时,将来自网络层的数据段 (segment) 拼接成消息 (message),然后传递给应用层
多路复用 (Multiplexing) 和多路分解 (Demultiplexing) 和上面的两个过程类似,但侧重点有所不同
- 多路复用:在发送方,接收来自不同套接字的消息,并添加上头部字段(用于多路分解)
- 多路分解:在接收方,解析头部字段,将信息分发给对应的套接字
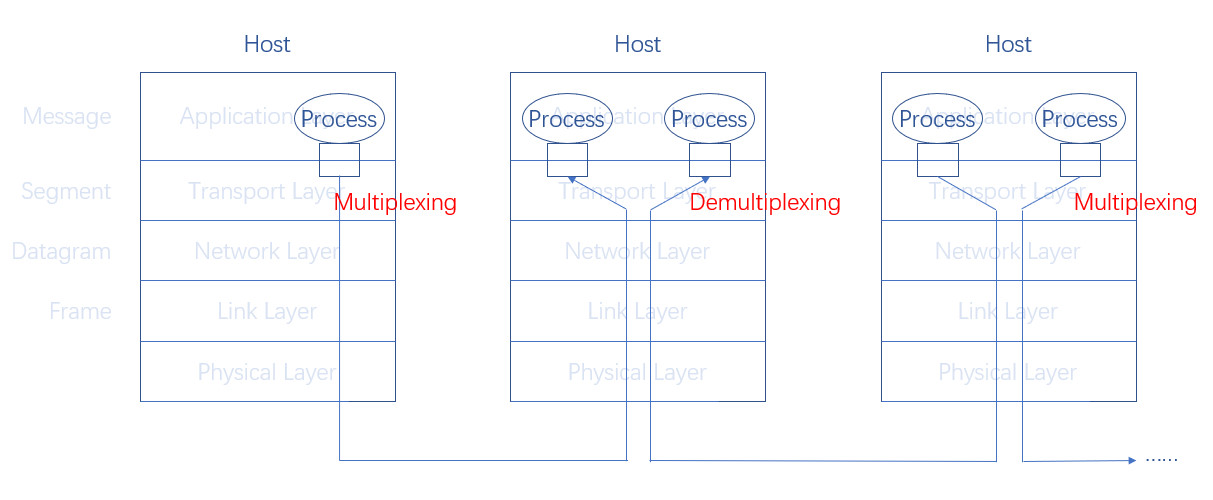
多路复用和多路分解的关键问题在于怎么将不同的数据段和不同的套接字对应起来?
这里要求数据段要有 特殊字段,套接字要有 唯一标识,并且能够根据特殊字段找到唯一标识
数据段的特殊字段,其实就是某些头部字段,具体来说就是 IP address 和 port number
- IP address:可以用于定位主机,在网络层处理,发送时封装到数据,接收时从数据提取
- port number:可以用于定位进程,在传输层处理,发送时封装到数据,接收时从数据提取
套接字的唯一标识,是在套接字建立的时候,根据发送方和接收方的状态确定的,这里分为两种情况
-
如果发送方和接收方是无连接的(UDP),那此时套接字的标识是一个二元组
(destination IP address, destination port number)
-
如果发送方和接收方是有连接的(TCP),那此时套接字的标识是一个四元组
(source IP address, destination IP address, source port number, destination port number)
好,最后我们简单概括一下多路复用和多路分解的整个过程
-
对于发送方而言(多路复用)
传输层接收来自应用层的消息,通过添加 port number 等头部字段将消息封装成数据段
网络层接收来自传输层的数据段,通过添加 IP address 等头部字段将数据段封装成数据报
-
对于接收方而言(多路分解)
网络层从链路层接收数据报,根据 IP address 判断是否应该向上传递(当前主机是否应该接收当前数据)
传输层从网络层接收数据段,根据 IP address 和 port number 判断应该传递给哪个套接字
2、UDP
(1)UDP 是什么
用户数据报协议 (User Datagram Protocol, UDP) 是一种 不可靠、无连接 的数据传输协议
-
不可靠:数据有可能会丢失,而且多个数据到达目的地时可能是没有顺序的
-
无连接:发送方和接收方之间无需建立连接,每个发出的数据段都是独立的
UDP 只是负责把数据丢到网络,交给下层进行传输,至于数据能不能到达、到达后顺序有没有错,它都一律不管
既然 UDP 这么不可靠,那我们为什么还要使用 UDP?一个字,快
相比于 TCP 使用一整套复杂的控制流程保证传输可靠,UDP 牺牲可靠性提高数据的传输速度
(2)UDP 数据段格式
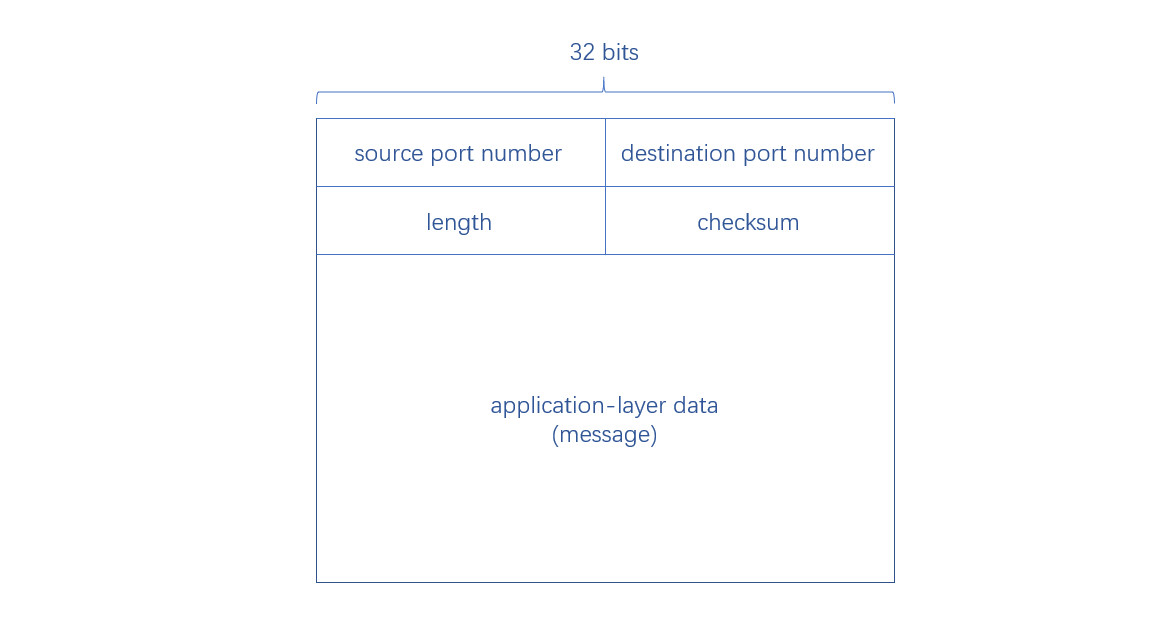
我们可以看到,传输层数据段其实是对应用层消息的封装,而在 UDP 协议就是加上四个头部字段而已
- source port number:发送方的端口号
- destination port number:接收方的端口号
- length:数据段的长度,包括头部字段,以 byte 为单位
- checksum:校验和,用于检查数据是否正确
3、可靠数据传输
刚才提到,UDP 它是一种不可靠的数据传输服务,那么自然也会有可靠的数据传输服务
怎么样才算是可靠的呢?就是能够保证接收方收到的数据:不会重复、不会丢失、没有错误、顺序正确
由于底层的数据传输通道是不可靠的,通常会发生位错误和包丢失,因此导致可靠数据传输协议十分复杂

可靠数据传输协议大体可以分为两种类型,一种是停等协议 (stop-and-wait),一种是流水线协议 (pipeline)
- 停等协议:发送方一次只能发送一个包,等待接收方返回响应后,才会发送下一个包,主要包括 Rdt 各个版本
- 流水线协议:发送方可以同时发送多个包,主要介绍 GBN 和 SR 两种协议
(1)Rdt1.0
Rdt1.0 假设传输管道是可靠的,也就是说在传输过程中不会发生位错误,也不会发生包丢失
由于传输管道是可靠的,所以整个过程十分简单,发送方只要负责发送包,接收方只要负责接收包就可以了

(2)Rdt2.0
Rdt2.0 假设在传输过程中可能会发生位错误,但不会发生包丢失
若在传输过程中,包会发生位错误,那么发送方并不知道接收方收到的包是不是正确的
所以当接收方收到一个包后,应该返回一个 响应 (ACK 或 NAK) 给发送方,告诉它收到的包是正确的还是错误的
如果是正确的,那么发送方可以发送下一个包,万一是错误的,那么发送方应该重发上一个包
-
对于接收方而言
如果收到一个正确的包,那么把包传到上层,然后给发送方发送一个 ACK,告诉它收到的包是正确的
如果收到一个错误的包,那么直接把包丢弃,然后给发送方发送一个 NAK,告诉它收到的包是错误的
-
对于发送方而言
如果收到 ACK ,那么发送下一个包给接收方
如果收到 NAK,那么重发上一个包给接收方
其中 ACK 和 NAK 就是接收方返回给发送方的响应,用来告诉发送方,收到的包是不是正确的
- ACK:acknowledgement,接收方显式告诉发送方 “ 我收到正确的包,你可以发送下一个包 ”
- NAK:negative acknowledgement,接收方显式告诉发送方 “ 我收到错误的包,你需要重发上一个包 ”

Rdt2.0 看似完美,但其实它有一个致命的错误,假如 ACK 或者 NAK 发生错误,那该怎么办呢?
此时,发送方不能发送下一个包,因为假如上一个包是错误的,接收方就会缺少了一个包
而且发送方也不能重发上一个包,因为假如上一个包是正确的,接收方就会收到重复的包
(3)Rdt2.1
Rdt2.1 假设在传输过程中可能会发生位错误,但不会发生包丢失,并且考虑 ACK 或者 NAK 发生错误的情况
下面我们来看看 Rdt2.1 究竟是怎么解决 ACK/NAK 发生错误的情况的,以及它对比于 Rdt2.0 会做出什么样的改动
首先规定:如果发送方收到错误的 ACK/NAK,那就重发上一个包
那么接下来要解决的问题就是:接收方怎么知道现在收到的包是不是和上一个包是一样的
如果是一样的,那就说明接收方已经收到上一个包,所以现在收到的包是重复的,直接把包丢弃就好
如果是不同的,那就说明接收方没有收到上一个包,所以现在收到的包是合适的,然后需要把包接收
方法也很简单,只需要发送方给每个发送的包添加 交替的序列号 (sequence number),就能区分连续的两个包
比如第一个包的序列号为 0,那么第二个包的序列号应该为 1,然后第三个包的序列号为 0,以此类推
-
对于接收方而言
如果收到一个正确的包,并且序列号和上一个传到上层的包不同,那么把包传到上层,给发送方发送一个 ACK
如果收到一个正确的包,但是序列号和上一个传到上层的包相同,那么直接把包丢弃,给发送方发送一个 ACK
如果收到一个错误的包,直接把包丢弃,然后给发送方发送一个 NAK
-
对于发送方而言
如果收到正确的 ACK ,那么发送下一个包给接收方
如果收到正确的 NAK,那么重发上一个包给接收方
如果收到错误的 ACK/NAK,重发上一个包给接收方
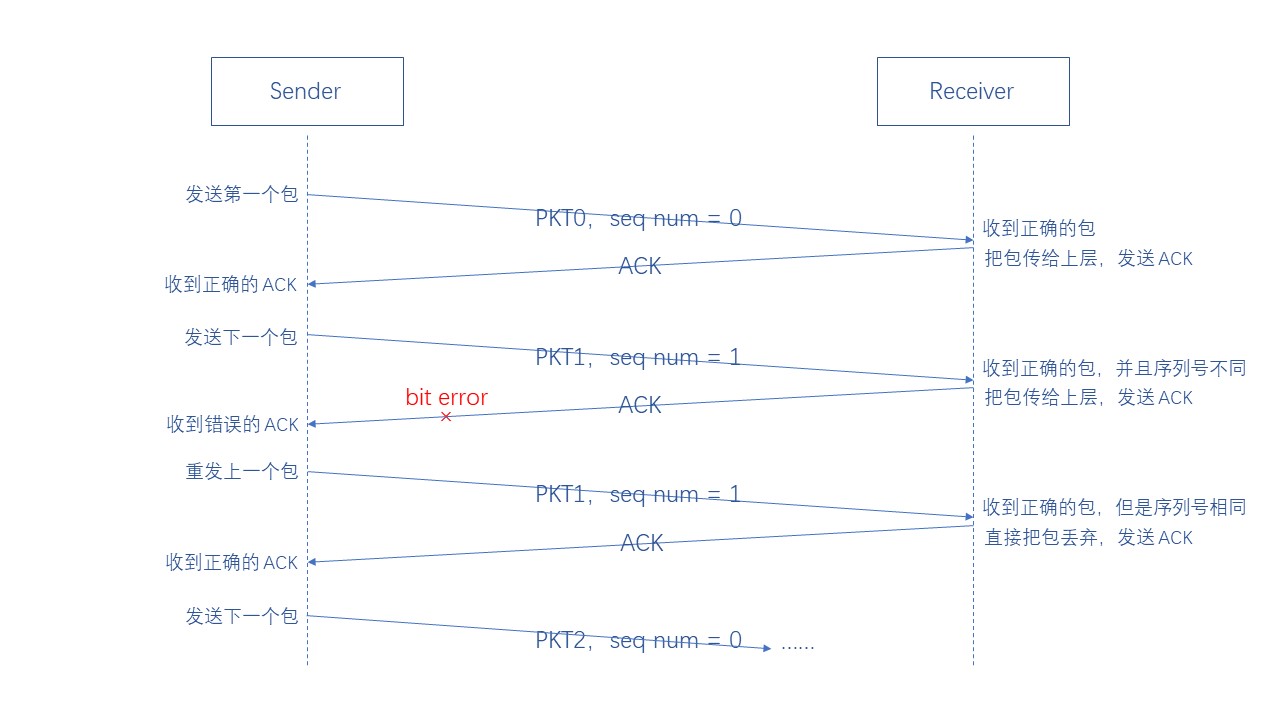

Rdt2.1 已经可以解决假设中的情形,但是能不能再优化呢?
答案是肯定的,我们可以 只使用 ACK 而不使用 NAK 达到一样的效果
(4)Rdt2.2
Rdt2.2 假设在传输过程中可能会发生位错误,但不会发生包丢失,并且仅仅使用 ACK 而不使用 NAK
Rdt2.2 规定接收方收到一个包,无论包正确与否,都会返回一个 ACK,并且带上最后一个传到上层的包的序列号
-
对于接收方而言
若收到一个正确的包,并且序列号不同,则把包传到上层,返回 ACK,带上最后一个传到上层的包的序列号
若收到一个正确的包,但是序列号相同,则也会把包丢弃,返回 ACK,带上最后一个传到上层的包的序列号
如果收到一个错误的包,直接把包丢弃,但是还是返回一个 ACK,带上最后一个传到上层的包的序列号
-
对于发送方而言:
如果收到正确的 ACK,并且现在收到的序列号和上一个收到的序列号不同,那么发送下一个包
如果收到正确的 ACK,但是现在收到的序列号和上一个收到的序列号相同,那么重发上一个包
如果收到错误的 ACK,重发上一个包
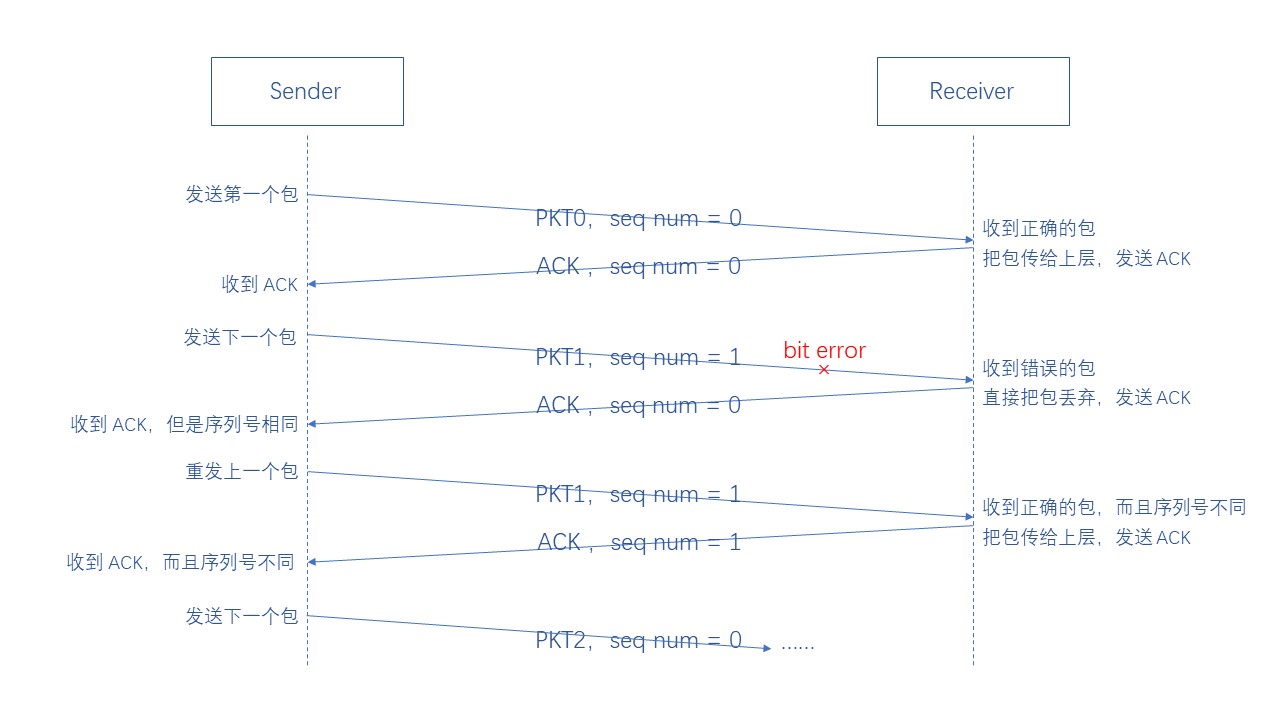
(5)Rdt3.0
Rdt3.0 假设在传输过程中不仅会发生位错误,而且会发生包丢失和延迟,这就是真实的网络环境
这种情况其实也很容易处理,只需要发送方给每个发送的包设置 超时时间 (timeout) 即可
假如在规定时间内,发送方没有收到对应发出的包的响应 (ACK),那就重发对应的包
由于整个过程比较复杂,所以在这里画两个 有限状态机 方便大家理解发送方和接收方的状态转移情况
发送方的有限状态机如下(注意,这里 ACK 和 PKT 后的数字代表带有的序列号):
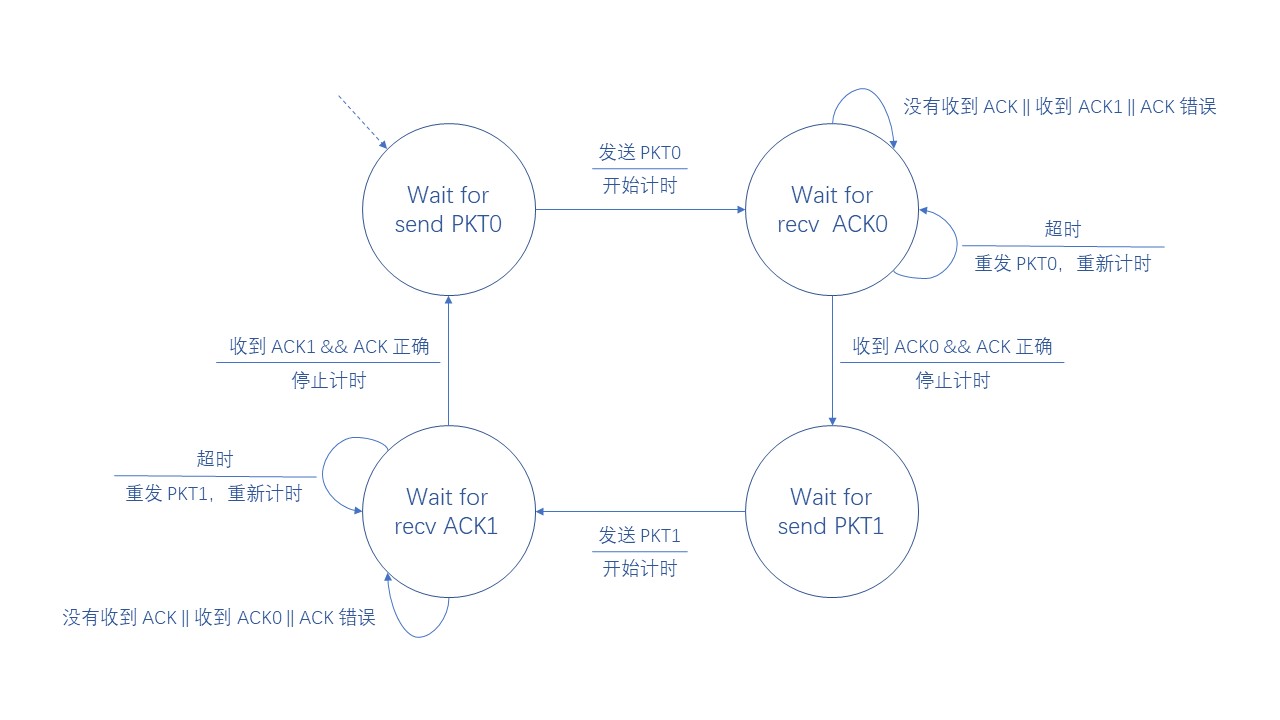
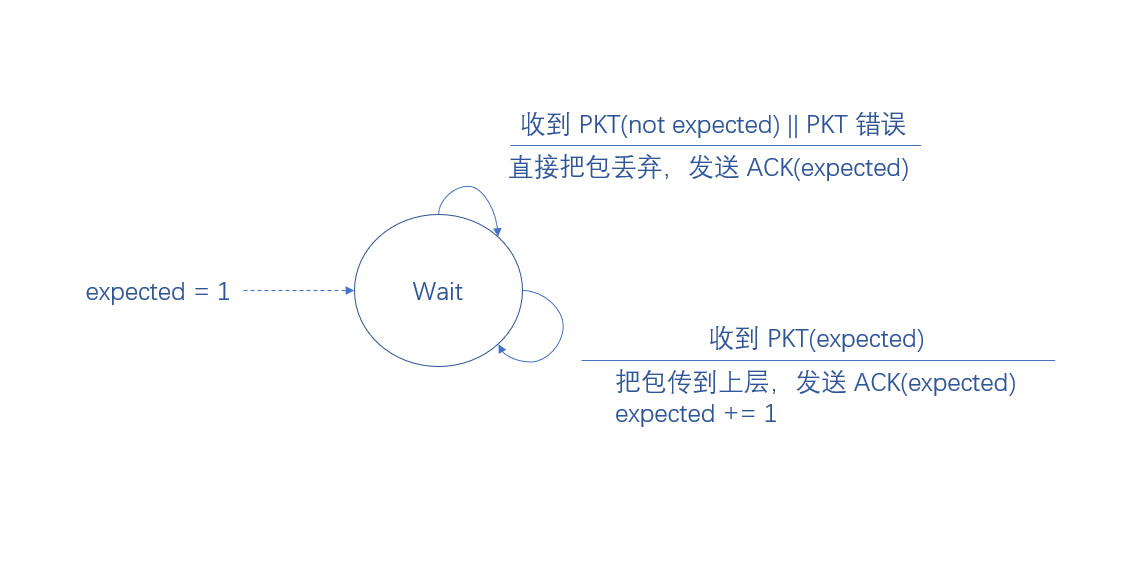
接收方的有限状态机如下(注意,这里 ACK 和 PKT 后的数字代表带有的序列号):

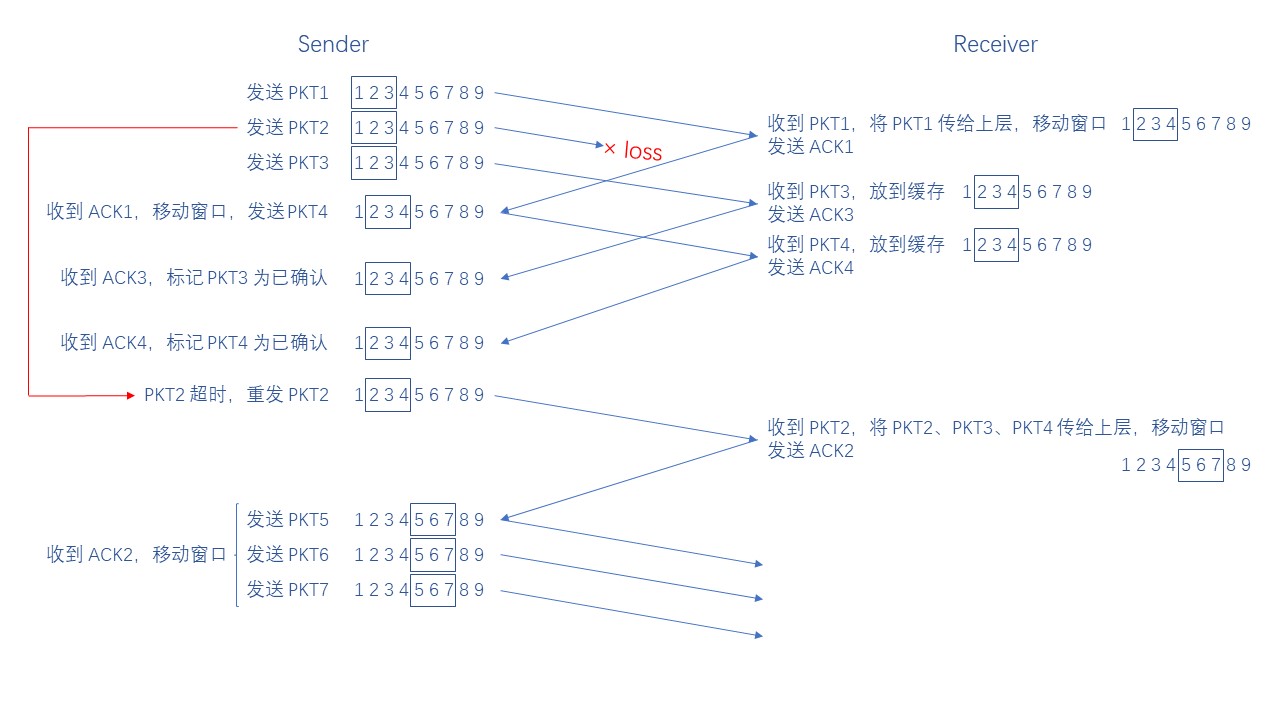
最后给大家举两个例子,一个是对应包丢失的情况,一个是对应包延迟的情况
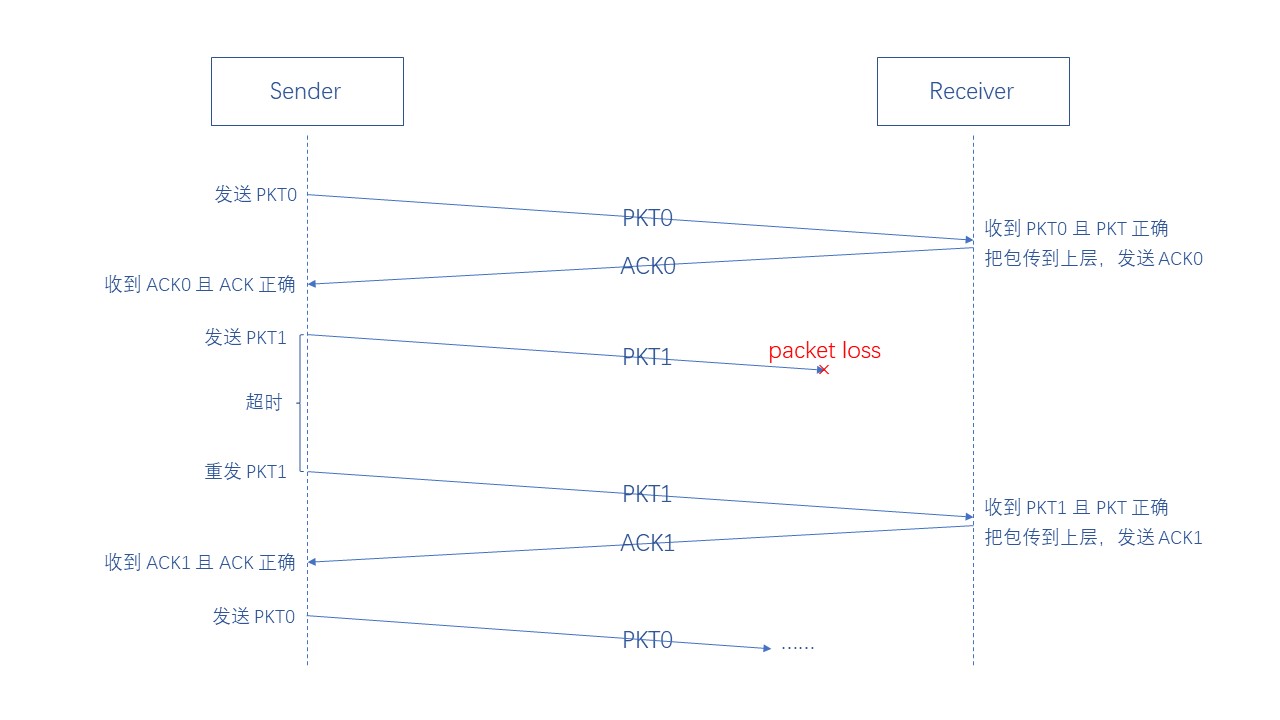
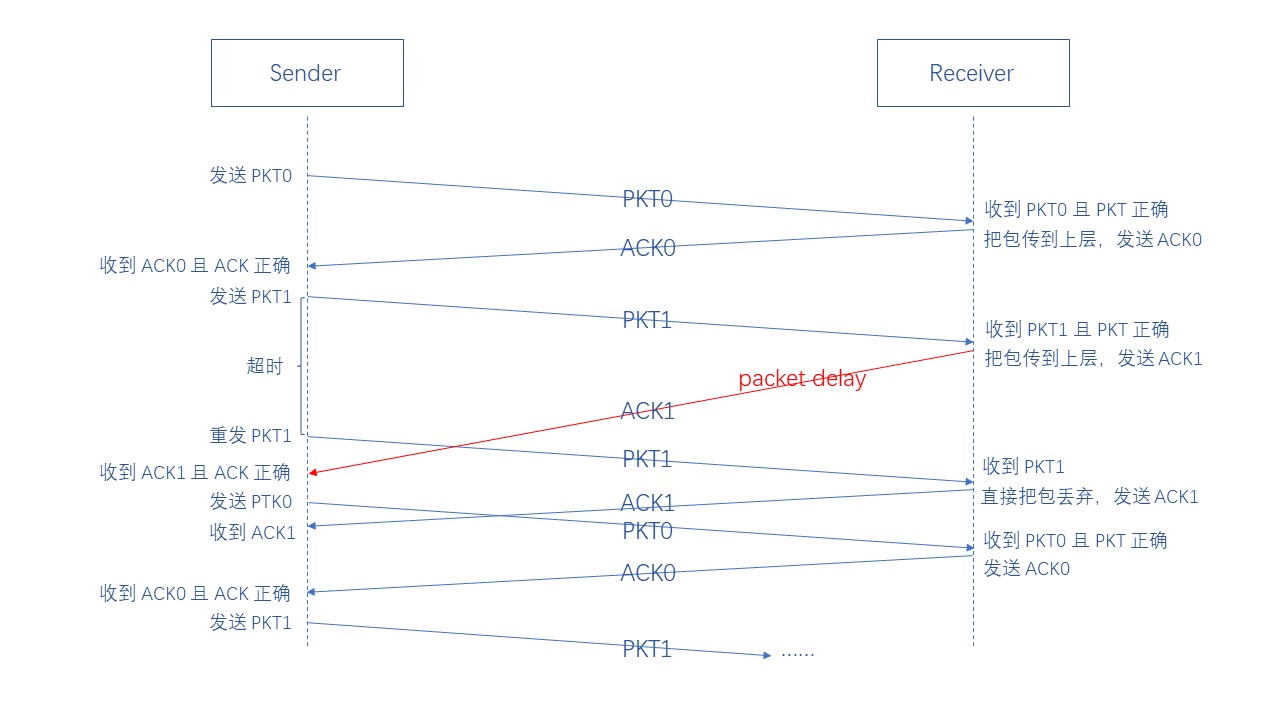
(6)GBN
回退 N 步 (Go-Back-N, GBN),它是流水线协议的一种,允许发送方同时发送多个包
相比 Rdt3.0,GBN 使用 k-bit 序列号 以及添加了 发送窗口 的概念,发送窗口的大小必须小于等于 2k - 1
由于在发送过程中,发送窗口会不断向前移动,因此 GBN 又被称为滑动窗口协议 (sliding window protocol)
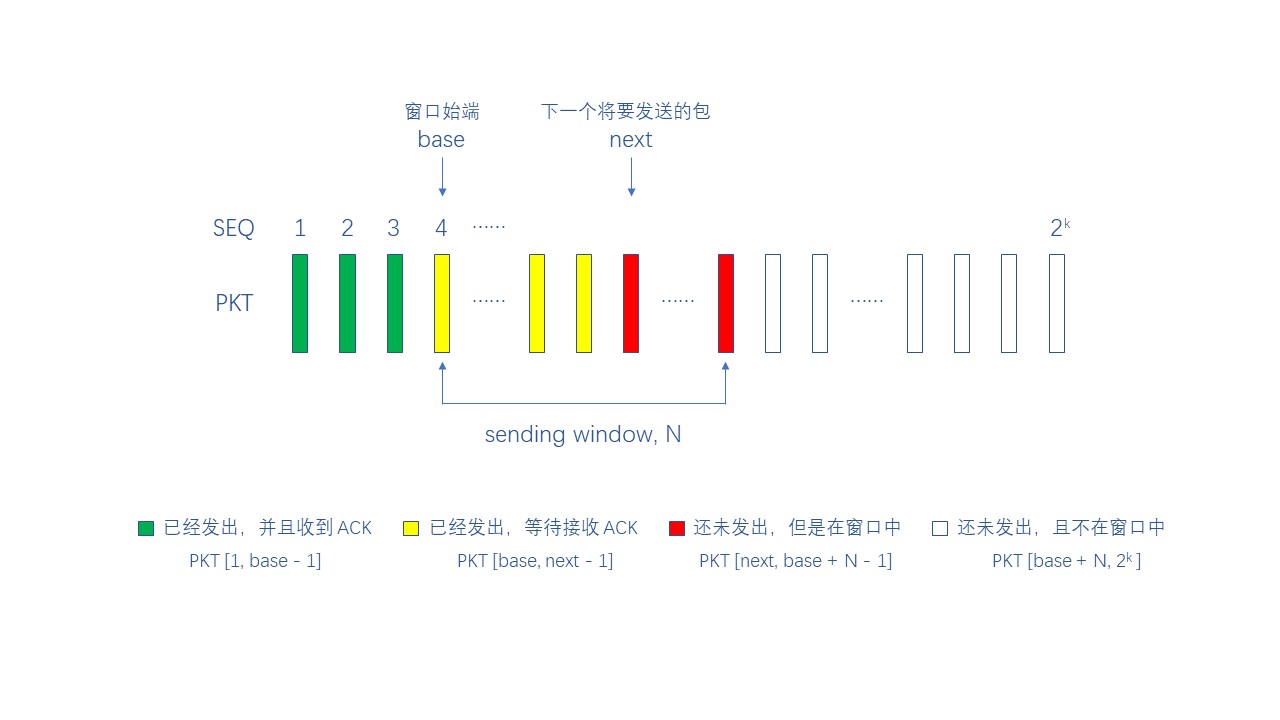
我们先从接收方的角度来看,由于接收方没有缓存,所以要求接收方收到的包都是要按照顺序的
如果接收方收到的包顺序错误,那么直接把包丢弃,如果接收方收到的包顺序正确,那么把包传到上层
什么叫按照顺序呢?也和之前一样,接收方通过序列号判断收到的包顺序是否正确
比如说,现在上一个收到的包序列号为 1,那么下一个期望收到的包序列号应该为 2,以此类推
概括来说,接收方的动作有以下三条规则:
- 如果收到的包顺序正确,那么把包传到上层,发送 ACK,带上期望收到的包的序列号
- 如果收到的包顺序错误,那么直接把包丢弃,发送 ACK,带上期望收到的包的序列号
- 如果收到的包是错误的,也是直接把包丢弃,发送 ACK,带上期望收到的包的序列号
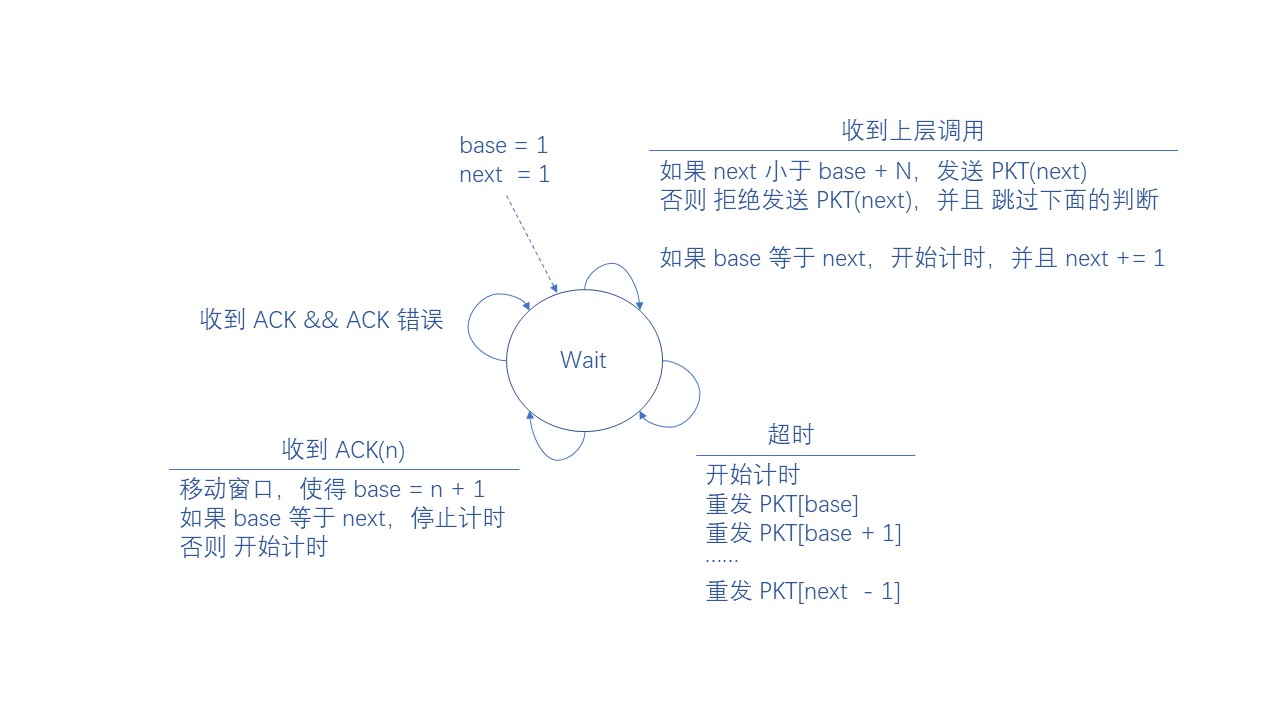
我们再从发送方的角度来看,由于允许同时发送多个包并添加了发送窗口的概念,所以稍微有点复杂
发送方如果收到上层调用要求发包,首先会检查发送窗口是否已满,如果满了先不发送,如果未满那就发送
如果发送方收到 ACK(n),表明接收方已经成功收到所有序列号小于等于 n 的包,那么发送方就可以向前移动窗口
如果发生超时,发送方会认为接收方没有收到当前分组的包,然后重发所有【已经发出,等待接收 ACK】的包
概括来说,发送方的动作也是有三条规则:
-
如果收到上层调用,并且窗口未满 (next < base + N),那么就发送下一个将要发送的包 PKT[next]
-
如果收到 ACK(n), 并且序列号 n 在发送窗口范围内,那就向前移动窗口使得 base 等于 n + 1
-
如果 PKT(n) 超时,重发所有等待接收 ACK 的包,即 PKT[base] ~ PKT[next - 1]
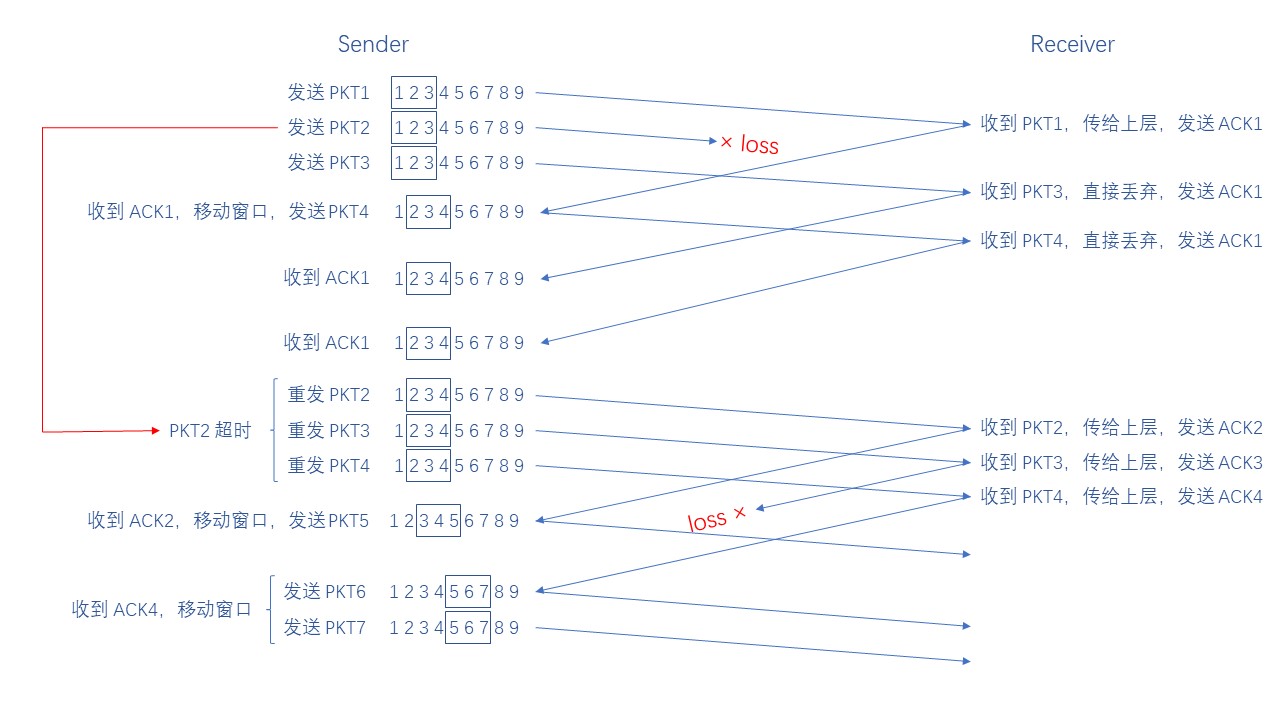
上面的描述可能会有点抽象,我们直接来看一个例子吧
(7)SR
选择重传 (Selective Repeat, SR) 在 GBN 的基础上做了改进,相比于 GBN,SR 添加了 接收窗口 的概念
接收窗口其实就是一块缓存,当收到不按顺序到达的包时,可以先放缓存,等前面的包到达后再一起交给上层
在 SR 协议中,发送窗口的大小必须小于等于 2k-1,同时接收窗口的大小必须小于等于 2k-1
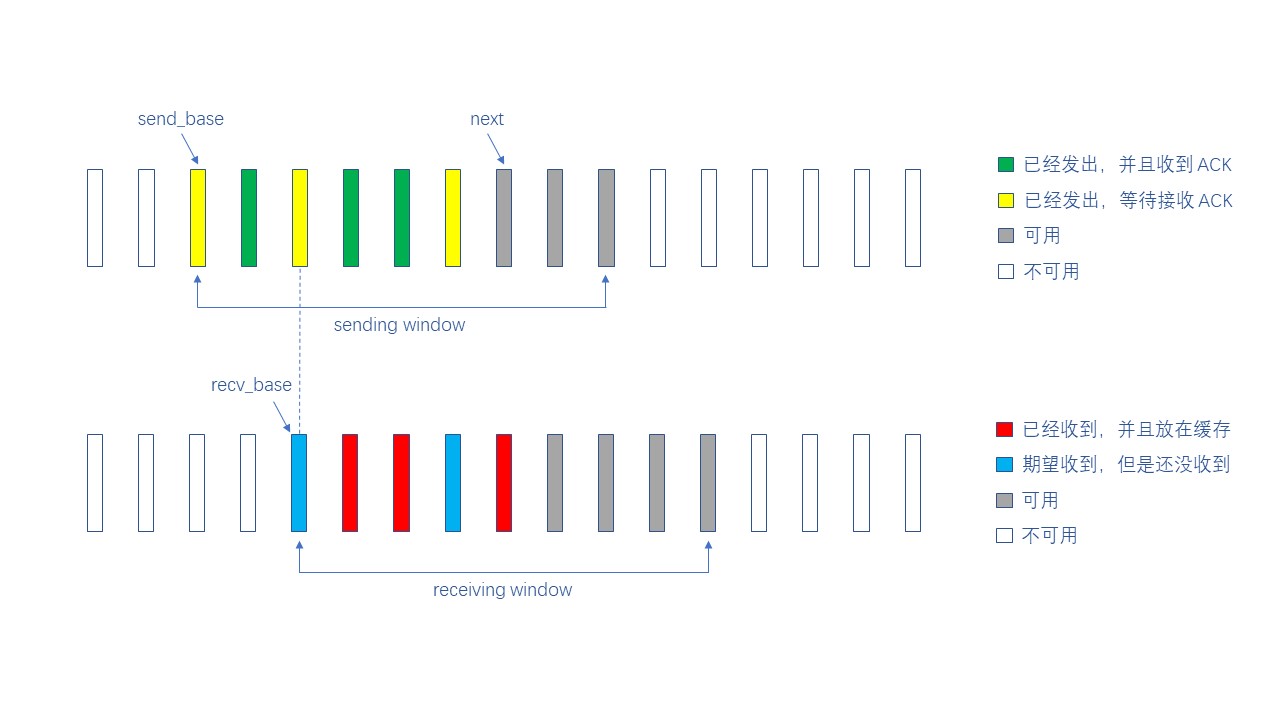
我们先从接收方的角度来看,由于接收方拥有一块缓存,所以能够先把不按顺序到达的包放在缓存
当缓存中有按照顺序的包时,把这些按照顺序的包一起交给上层,然后向前移动窗口
比如,缓存中已经有 2、3、5,如果现在收到 1,那么就可以把 1、2、3 一起交给上层,然后窗口移动到 4
概括来说,接收方的动作有以下三条规则:
-
如果收到 PKT(n) 并且序列号 n 在接收窗口范围内,那么把包放在缓存,然后返回一个 ACK(n)
此时检查接收窗口,若有顺序正确的包,那么把这些包交给上层,然后向前移动窗口
-
如果收到 PKT(n) 但是序列号 n 不在窗口的范围内,那就什么都不要做
-
收到错误的 PKT,那也什么都不要做
我们再从发送方的角度来看,当发送方收到 ACK(n) 时,会先把序列号为 n 的包标记起来
如果在接收窗口始端中出现连续的被标记的包时,就会向前移动发送窗口,直至遇到未被确认的包
比如,窗口中 2、3、5 是标记为被确认的,如果现在 1 也被标记,那么就可以将窗口移动到 4
概括来说,发送方的动作也是有三条规则:
-
如果收到上层调用,并且窗口未满 (next < base + N),那么就发送下一个将要发送的包 PKT[next]
-
如果收到 ACK(n) 并且序列号 n 在发送窗口范围内,那么标记这个包为被确认的
此时检查发送窗口,若窗口始端有连续确认的包,那么向前移动窗口
-
如果 PKT(n) 超时,重发 PKT(n)
最后来看一个例子哈
4、TCP
(1)TCP 是什么
传输控制协议 (Transmission Control Protocol, TCP) 是 可靠的、面向连接 的数据传输服务
- 可靠:能够保证数据到达目的地,且到达目的地时顺序是正确的
- 面向连接:需要先建立连接后才能传输数据,建立连接需要三次握手,释放连接需要四次挥手
TCP 和 UDP 的区别?
1、TCP 提供可靠的数据传输服务,UDP 只是尽最大努力交付
2、TCP 是面向连接的,UDP 是无连接的
3、TCP 是面向字节流的,UDP 是面向数据包的
4、TCP 首部较大(20 bytes),UDP 首部较小(8 bytes)
5、TCP 是一对一的,UDP 是一对多的
(2)TCP 数据段格式
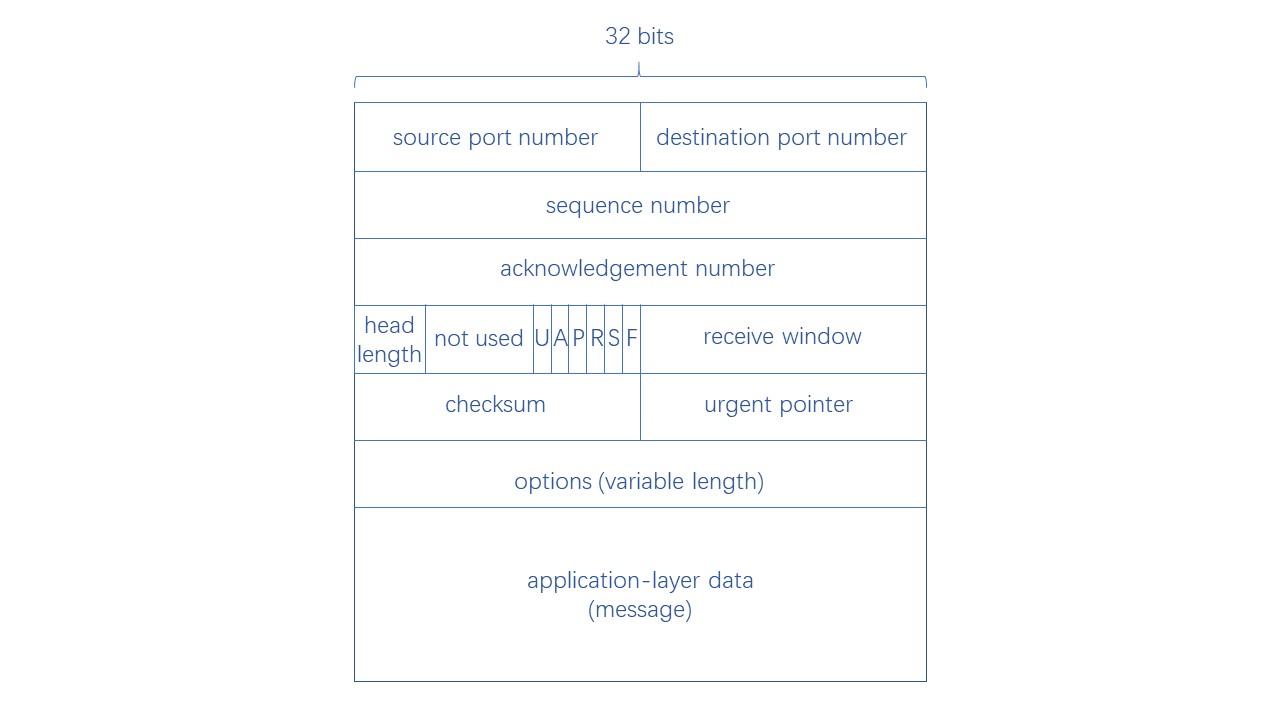
传输层数据段是对应用层消息的封装,TCP 协议由于需要保证传输可靠,所以添加的头部字段也比较多
- source port number:发送方的端口号
- destination port number:接收方的端口号
- sequence number:序列号
- acknowledge number:确认号
- head length:头部长度
- not used:保留使用
- U:紧急控制位,若为 1,说明报文包含紧急数据,需要优先处理
- A:确认控制位,若为 1,说明确认号是有效的
- P:推送控制位,若为 1,收到报文后不放进缓存,直接传给上层
- R:复位控制位,若为 1,说明连接发生错误,需要重新建立
- S:同步控制位,用于同步序列号
- F:终止控制位,若为 1,说明数据发送完毕,要求释放连接
- receive window:接收方窗口大小
- checksum:校验和,用于检查数据是否正确
- urgent pointer:紧急指针,标识紧急数据的位置
- options:长度可变,用于添加别的信息
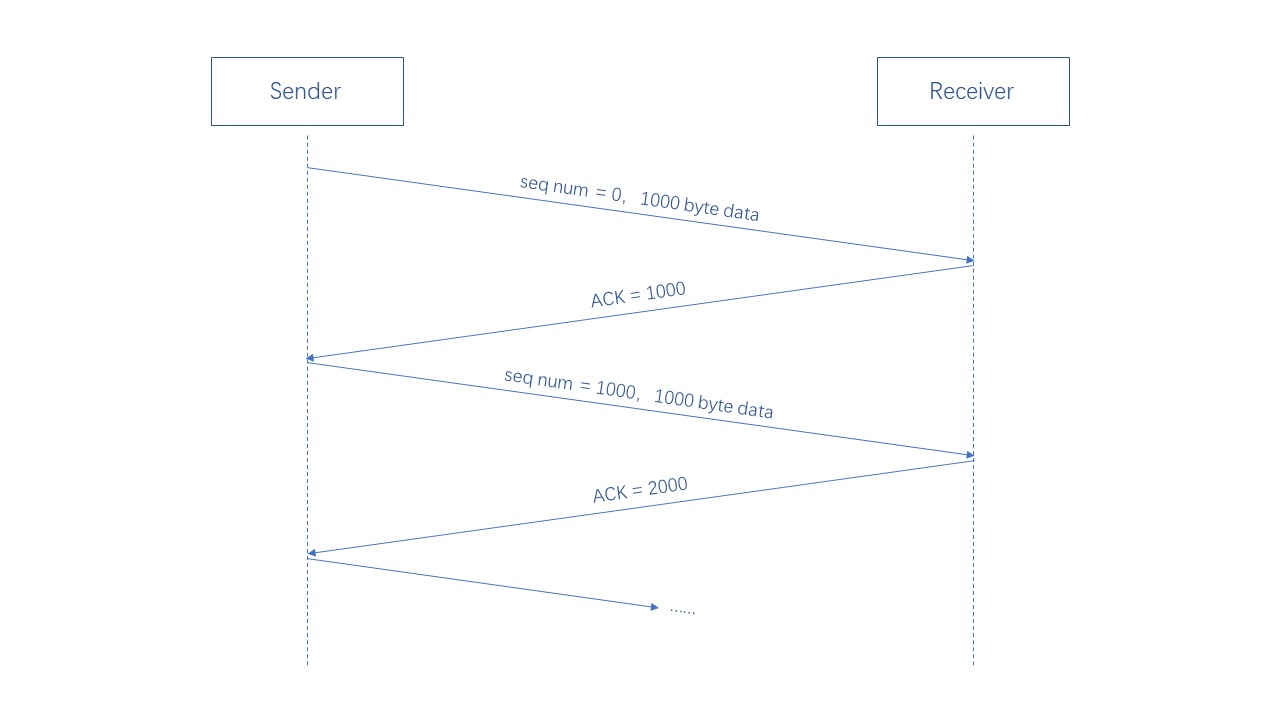
UDP 是 面向数据包 传输的,而 TCP 是 面向字节流 传输的,这是什么意思呢,这里给大家举一个例子
假如现在需要传输一个 500000 byte 的大文件,然后已知最大报文段长度 (MSS) 等于 1000 byte
那么 TCP 会将文件划分为一段一段的字节流进行传输,每一段字节流的大小都是 1000 byte
发送方发送的序列号就是每段字节流第一个字节的编号,接收方返回的确认号表明下一个期望收到的字节的编号
(3)可靠数据传输
TCP 采用流水线协议,但是在发送方和接收方采取的动作上,又和 GBN、SR 有一点点的不同
对于接收方而言:
-
如果收到一个正确的分组,并且序列号 n 在接收窗口范围内,那么就把分组放在缓存
此时检查接收窗口,如果有顺序正确的分组,那么按照顺序把分组交给上层,然后向前移动窗口
之后返回一个 ACK,带上最后一个传到上层的分组的序列号
-
如果收到一个正确的分组,但是序列号 n 不在窗口的范围内,或者是收到错误的分组,那就什么都不要做
对于发送方而言:
- 如果收到上层调用,那就发送下一个分组
- 如果发生超时事件,重发那个序列号最小的没有被确认的分组
- 如果收到三次 ACK(n),并且序列号 n 小于等于窗口始端,那就重发序列号为 n 的分组
- 如果收到 ACK(n),并且序列号 n 大于窗口始端,那就向前移动窗口,使得 base = n
nextSeqNum = InitialSeqNumber
SendBase = InitailSeqNumber
loop(forever) {
switch(event)
event: data received from application above
create TCP segment with sequence number NextSeqNum
if (timer currently not running)
start timer
pass segment to IP
NextSeqNum = NextSeqNum + length(data)
break
event: timer timeout
retransmit not-yet-acknowledged segment with smallest sequence number
start timer
break
event: ACK received, with ACK field value of y
if (y > snedBase) {
SendBase = y
if (there are currently not-yet-acknowledged segments)
start timer
}
else {
increment count of duplicate ACKs received for y
if (number of duplicate ACKs received for y == 3){
resend sgment with sequence number y
}
}
break
}
(4)连接管理
TCP 是面向连接的,在传输数据前需要建立连接,在传输数据后也要释放连接
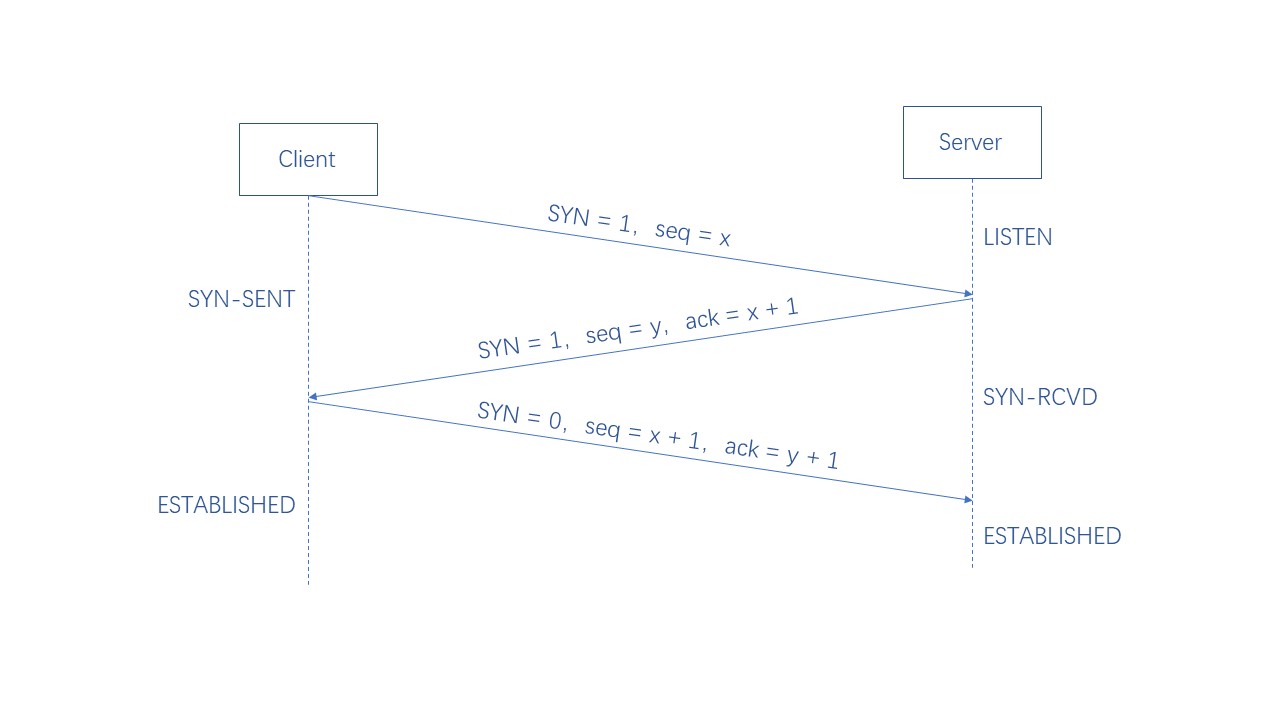
建立连接需要三个步骤,称为 三次握手,具体的过程如下:
-
客户端发送 SYN,指明客户端的初始序列号,进入 SYN-SENT 状态
-
服务端收到 SYN,返回 SYN + ACK,表明已经收到报文同时指明服务端的初始序列号,进入 SYN-RCVD 状态
-
客户端收到 SYN + ACK,发送 ACK,并且可以带上要发送的数据,进入 ESTABLISHED 状态
服务端收到 ACK,随即进入 ESTABLISHED 阶段,此时 TCP 连接建立完成
为什么是三次握手,而不是两次或四次?
第一次握手:客户端发送 SYN,服务端收到 SYN,此时服务端可以确认 客户端的发送能力 OK
第二次握手:服务端返回 SYN + ACK,客户端收到,此时客户端可以确认 服务端的接收和发送能力 OK
第三次握手:客户端发送 ACK,服务端收到 ACK,此时服务端可以确认 客户端的接收能力 OK
三次握手有什么作用?
第一,使双方做好数据交换的准备工作,比如准备好接收缓存和发送缓存等
第二,确定双方的初始序列号;第三,保证双方的接受和发送能力正常
释放连接需要四个步骤,称为 四次挥手,具体的过程如下:
-
当客户端发送完所有数据后,给服务端发送 FIN,进入 FIN-WAIT-1 状态,说明自己已经没有数据还要发送
-
服务端收到 FIN,返回一个 ACK,然后进入 CLOSE-WAIT 状态
此时处于一个半关闭的状态,意味着客户端不会再发送数据,但如果服务端还有数据要发送,客户端也会接收
-
客户端收到 ACK 之后,继续等待接收 FIN,进入 FIN-WAIT-2 状态,此时还能接收服务端的数据
-
服务端发送完所有数据后,给客户端发送 FIN,进入 LAST-ACK 状态,等待客户端最后的确认
-
客户端收到 FIN,返回一个 ACK,然后进入 TIME-WAIT 状态
此时客户端并不会真正关闭连接,必须经过 2MSL 时间之后,才会关闭连接,进入 CLOSED 状态
-
服务端收到 ACK 之后,立即关闭连接,进入 CLOSED 状态
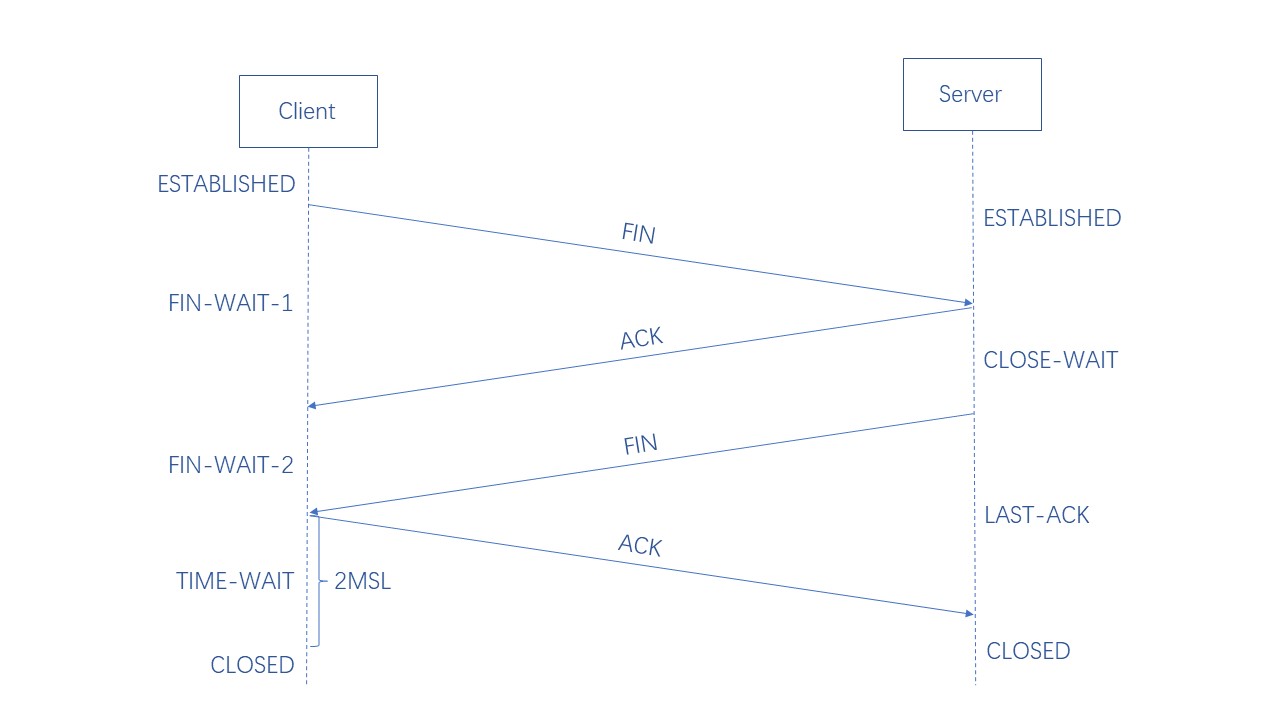
为什么连接的时候是三次握手,而关闭的时候却是四次挥手?
因为在第二次握手时,服务端能够把 SYN + ACK 一起发送过去,其中 SYN 用于同步, ACK 用于应答
但在四次挥手过程中,服务端收到 FIN 之后,可能还有其它数据还要发送,所以只能先回复一个 ACK
等到服务端也发送完数据之后,才会再发送一个 FIN
客户端为什么要经过 TIME-WAIT 阶段才会进入 CLOSED 阶段?
因为客户端要保证服务端能够收到 ACK,如果服务端没有收到 ACK,服务端会重发 FIN
客户端再次收到 FIN 后,就知道之前的 ACK 已经丢失,然后重发一个 ACK,继续等待 2MSL 时间
如果在 2MSL 时间内,客户端没有再次收到 FIN,它就知道服务端已经收到 ACK,然后就可以关闭连接
(5)流量控制
接收方有接收缓存,在接收数据时,网络层会往缓存中放入数据,应用层会从缓存中拿走数据
由于应用层的速度相对较慢,所以为了不使缓存溢出,我们要控制发送方的发送速率,这就是流量控制
接收方会把接收窗口的大小放在数据段发给发送方,发送方根据接收窗口的大小控制发送的速率

(6)拥塞控制
如果网络上有太多的数据,很可能会导致丢失和延迟,所以我们要控制发送方的发送速率,这就是拥塞控制
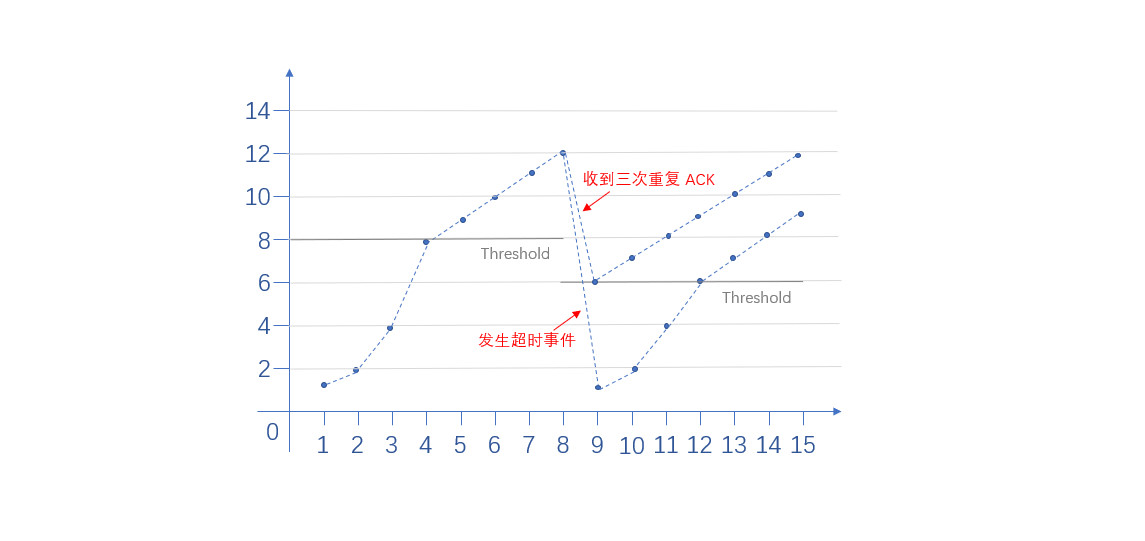
首先一个问题,发送方怎么感知到网络拥塞呢?实际上发送方可以通过超时事件和收到三次重复 ACK 进行判断
如果发生网络拥塞又应该怎么办呢?一个比较著名的解决方法就是 Reno 拥塞控制算法,整个过程如下:
- 当拥塞窗口小于阈值时,拥塞窗口指数增加
- 当拥塞窗口大于等于阈值时,拥塞窗口线性增加
- 如果收到三次重复 ACK,阈值 = 拥塞窗口 / 2,拥塞窗口 = 阈值
- 如果发生超时事件,阈值 = 拥塞窗口 / 2,拥塞窗口 = 1MSS
【 阅读更多计算机网络系列文章,请看 计算机网络复习 】