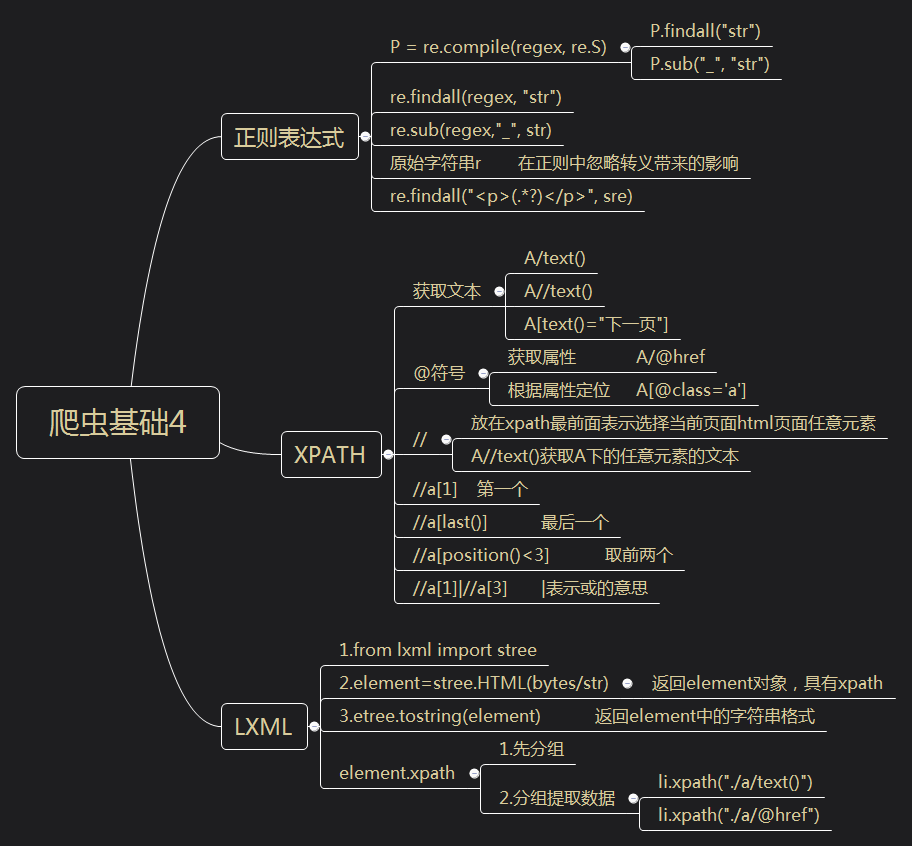
爬虫基础总结4 正则表达式 P = re.compile(regex, re.S) P.findall("str") P.sub("_", "str") re.findall(regex, "str") re.sub(regex,"_", str) 原始字符串r 在正则中忽略转义带来的影响 re.findall("<p>(.*?)</p>", sre) xpath 获取文本 A/text() A//text() A[text()="下一页"] @符号 获取属性 A/@href 根据属性定位 A[@class='a'] // 放在xpath最前面表示选择当前页面html页面任意元素 A//text()获取A下的任意元素的文本 //a[1] 第一个 //a[last()] 最后一个 //a[position()<3] 取前两个 //a[1]|//a[3] |表示或的意思 lxml 1.from lxml import stree 2.element=stree.HTML(bytes/str) 返回element对象,具有xpath 3.etree.tostring(element) 返回element中的字符串格式 element.xpath 1.先分组 2.分组提取数据 li.xpath("./a/text()") li.xpath("./a/@href")