简介:
随着数据量越来越大,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。
学术一点的定义就是:分布式文件系统是一种允许文件通过网络在多台主机上分享的文件的系统,可让多机器上的多用户分享文件和存储空间。分布式文件管理系统很多,HDFS 只是其中一种。适用于一次写入、多次查询的情况,不支持并发写情况,小文件不合适。因为小文件也占用一个块(block),小文件越多(1000个1k文件)块越多,NameNode压力越大。
1.HDFS是什么?
我们通过hadoop shell上传的文件是存放在DataNode的block中,通过 Linux shell是看不到文件的,只能看到block。可以一句话描述HDFS:把客户端的大文件存放在很多节点的数据块中。在这里,出现了三个关键词:文件、节点、 数 据块。HDFS 就是围绕着这三个关键词设计的,我们在学习的时候也要紧抓住 着 三个关键词来学习。
2.HDFS的基本结构

2.1NameNode
(1) 概述
NameNode的作用是管理文件目录结构,接受用户的操作请求,是管理数据节点。NameNode维护两套数据:
① 文件目录与数据块之间的关系。是静态的,存放在磁盘上的,通过fsimage 和edits文件来维护。
② 数据块与节点之间的关系。不持久放到磁盘,每当集群启动的时候,会自动建 立这些信息,所以一般都放在内存中。
所以它是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表,接收用户的操作请求。
文件包括:
① fsimage(文件系统镜像):元数据的镜像文件。存储某一时段NameNode内存 元数据信息
② edits:操作日志文件,加入操作日志
③ fstime:保存最近一次checkpoint的时间
以上这些文件是保存在linux的文件系统中的!
(2) 特点
是一种允许文件网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
① 通透性。让实际上是通过网络来访问文件的动作,在程序与用户看来,就像是访问本地磁盘一般。
② 容错。即使系统中有某些节点脱机,整体来说系统仍然可以持续运作而不会有数据损失。
③ 适用于一次写入、多次查询的情况,不支持并发写情况,小文件不合适。
2.2DataNode
(1) 概述
DataNode的作用是HDFS中真正存储数据的。
(2) block
①如果一个文件非常大,比如100GB,那么怎么存储在DataNode中呢? DataNode在存储数据的时候是按照block为单位读写数据的。block是hdfs读 写数据的基本单位。
②假设文件大小是100GB,从字节位置0开始,每128MB字节划分为一个 block,以此类推,可以划分出很多的block。每个block就是128MB大小。
③我们看一下org.apache.hadoop.hdfs.protocol.Block类,属性如下显示

由上图可知,类中的属性没有一个是可以存储数据的。所以block本质上是 一个逻辑概念,意味着block里面不会真正的存储数据,只是划分文件的。
④ 那么block默认为128MB的容量是在哪进行配置的呢?查看 core-default.xml文件
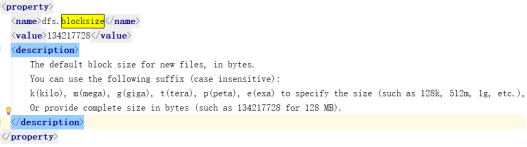
上图中的参数dfs.blocksize指的就是block的大小,值是134217728字节, 可以换算为128MB。如果我们不希望使用128MB大小,可以再core-site.xml 中覆盖该值。单位为字节。