简介:
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
分布式架构的常见概念:
1.集群
小饭店原来是一个厨师,切菜洗菜备料炒菜全干。后来客人多了,厨房一个厨师忙不过来,又请了个厨师,两个厨师都能炒一样的菜,这两个厨师的关系就是集群。
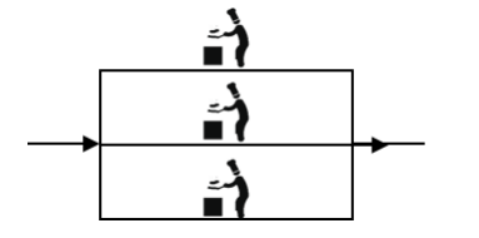
2.分布式
为了让厨师专心炒菜,把菜做到极致,又请了个配菜师负责切菜,备菜,备料,厨师和配菜师的关系就是分布式的,一个配菜师也忙不过来,有请了个配菜师,这两个配菜师的关系就是集群了。所以说有分布式的架构中可能有集群,但集群不等于有分布式。

3.节点
节点是指一个可以独立按照分布式协议完成一组逻辑的程序个体。在具体的项目中,一个节点表示的是一个操作系统上的进程。
一.hadoop分布式集群的搭建
我们需要搭建hadoop集群环境首先需要环境的支持
1.环境支持
操作系统: CentOS7 64
JDK环境: JDK 8

Hadoop环境: hadoop-2.8.0

虚拟机名称: master(主)+slave1(从1)+slave2(从2)
首先配置一个静态id
配置真机网络共享


配置虚拟机虚拟网络

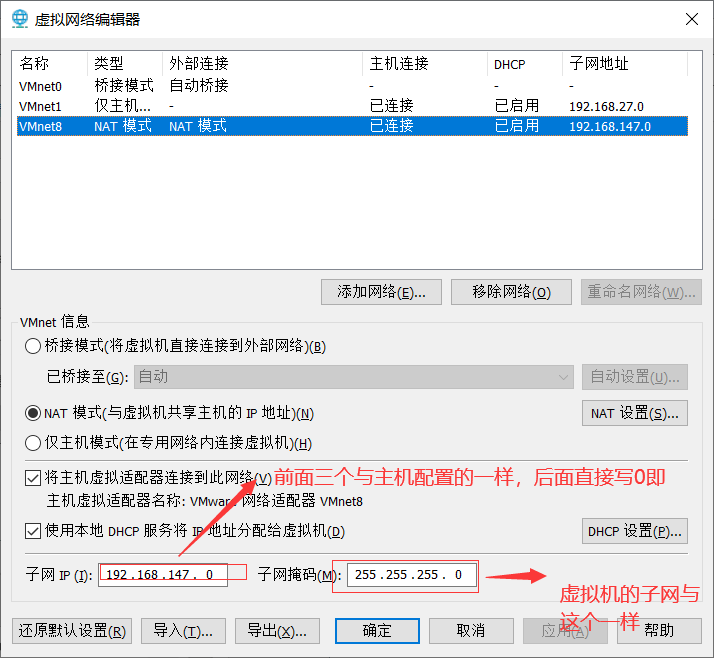
找到系统工具,设置,网络

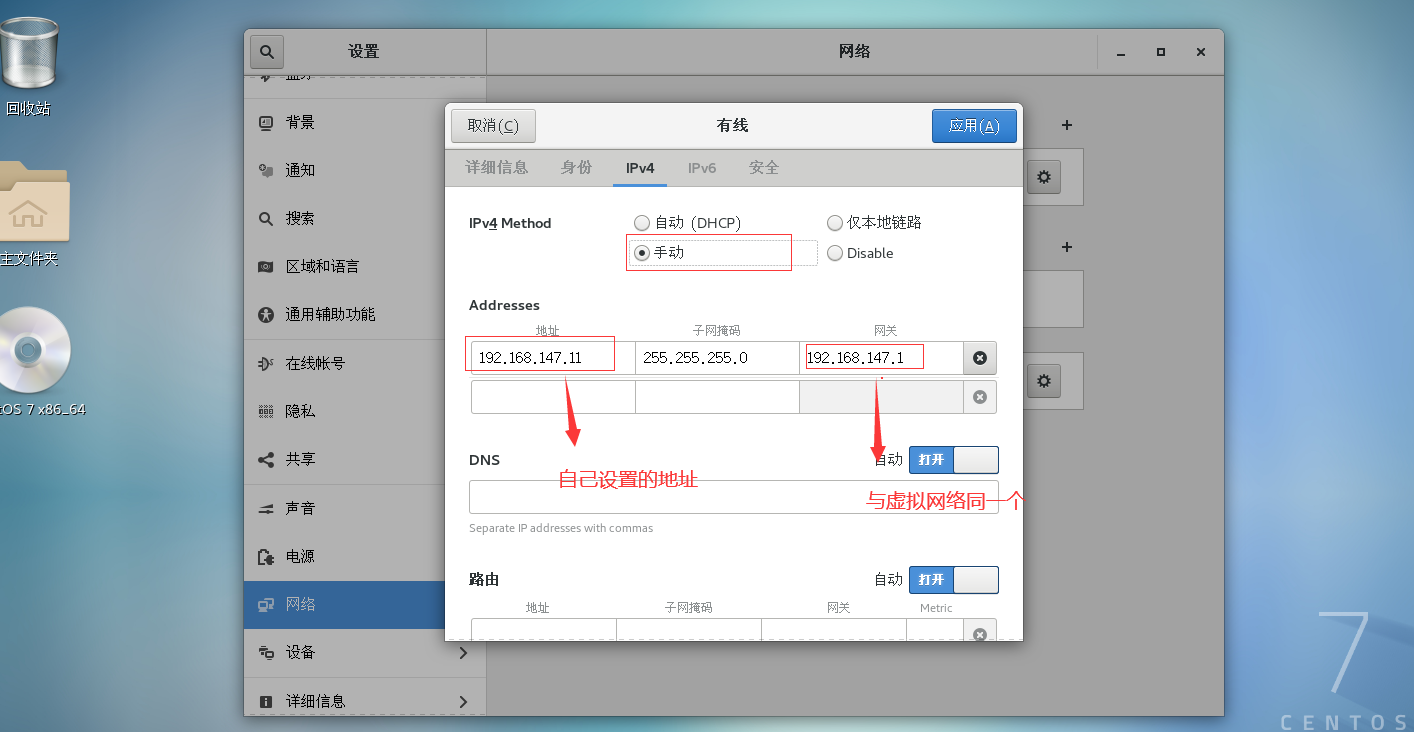
将自动改为手动配置如下信息(配置完了重启即可)
2.设置主机名
我这里是直接将所有的配置全都配置完克隆了两台slave
#编辑hostname文件修改主机名称
vim /etc/hostname
主就使用命令改为master,从就使用命令改为slave01,slave02

使用命令查看主机名是否修改成功
注意:如果不成功可能需要重启虚拟机!!!
hostname

3.安装JDK
注意:Linux上原来的JDK是不完整的需要我们手动将他们一个个的卸载重新安装我们的JDK
首先先使用命令查看Linux上原来的JDK
#查看各自默认安装的JDK rpm -qa|grep jdk

使用 rpm -e --nodeps命令 一个一个卸载
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64 rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64 rpm -e --nodeps java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64 rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64
安装我们的JDK,这里我是使用xf工具上传的解压包上传到/usr/local/java
注意:这里的java路径是我自己创建的
使用命令解压压缩包
#解压压缩文件 tar -zxvf jdk-8u181-linux-x64.tar.gz
解压成功后查看目录

配置JDK
首先修改ect下的profile文件
#编辑profile文件
vim /etc/profile
加入以下内容,请各位按照自身的安装目录为准
export JAVA_HOME=/usr/local/jdk1.8.0_121 export CLASSPATH=.:%JAVA_HOME%/lib/dt.jar:%JAVA_HOME%/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin
在文件的最底下添加即可
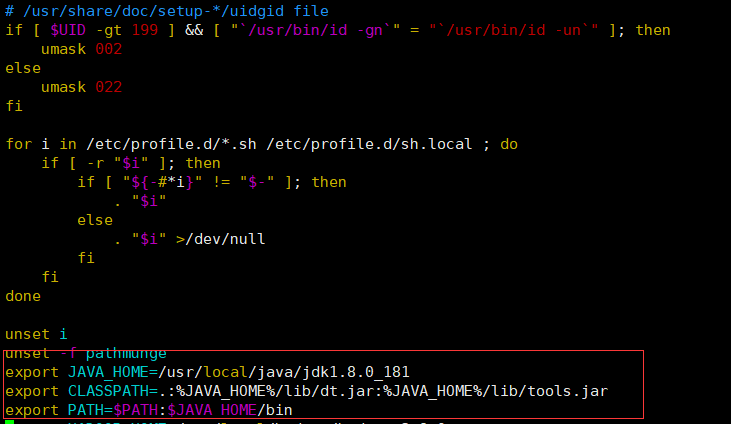
使用命令刷新一下文件,因为Linux不会自己刷新
source /etc/profile

输入java -version命令查看是否安装成功

4.安装并完成hadoop的配置
使用xf工具将hadoop的压缩包上传到Linux里的usr/local/hadoop(自己创建的)
使用命令行解压此压缩包
tar -zxvf hadoop-2.8.0.tar.gz

编辑profile文件也就是配置JDK的文件
vim /ect/profile
添加如下内容,路径请务必写你自己的
export HADOOP_HOME=/usr/local/hadoop-2.8.0 export PATH=$PATH:$HADOOP_HOME/bin:$PATH:$HADOOP_HOME/sbin

添加完成后刷新文件
source /etc/profile
编辑hosts文件,将三台主机的主机名称对应的ip地址写入(我这里还没有后续是直接克隆的)
#编辑hosts文件 vim /etc/hosts #写入如下内容,注意IP地址以自身为准 192.168.147.11 master 192.168.147.12 slave1 192.168.147.13 slave2
完成hadoop内部的配置,切换到hadoop2.8的内部文件夹下
cd /usr/local/hadoop/hadoop-2.8.0/etc/hadoop/

配置slaves文件
vim slaves

删除掉原有的localhost,添加slave主机名

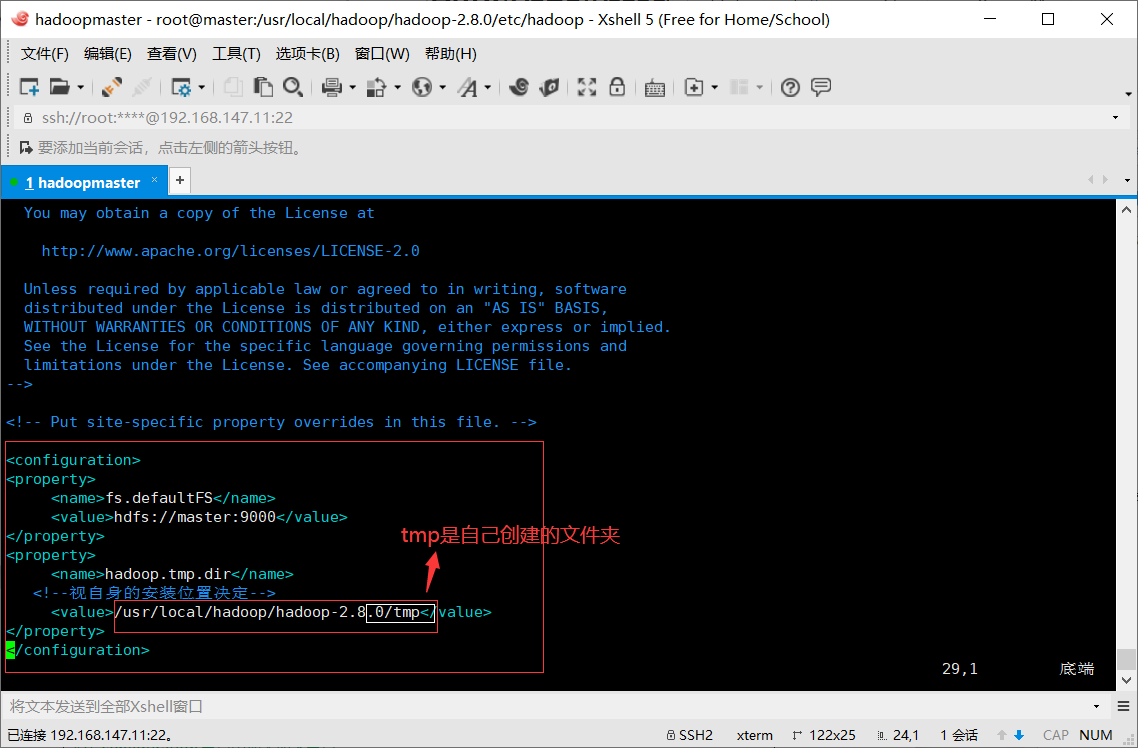
配置core-site.xml文件
vim core-site.xml
在configuration节点中加入如下节点
<property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <!--视自身的安装位置决定--> <value>/usr/local/hadoop-2.8.0/tmp</value> </property>
配置hdfs-site.xml文件
vim hdfs-site.xml
在configuration节点中加入如下节点
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<!--以自身安装目录为准-->
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.8.0/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.8.0/hdfs/data</value>
</property>

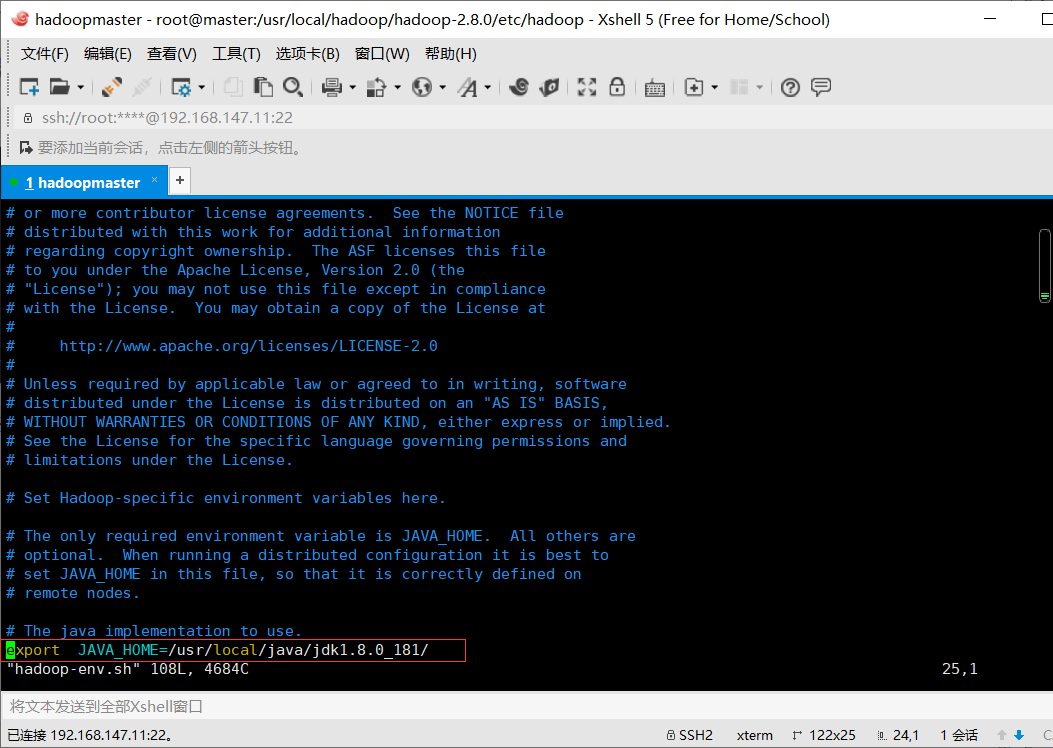
编辑hadoop-env.sh
加入以下内容也就是JDK的安装目录
export JAVA_HOME=/usr/local/jdk1.8.0_121/
编辑yarn-env.sh文件

配置yarn-site.xml
vim yarn-site.xml
在configuration节点中加入如下内容
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
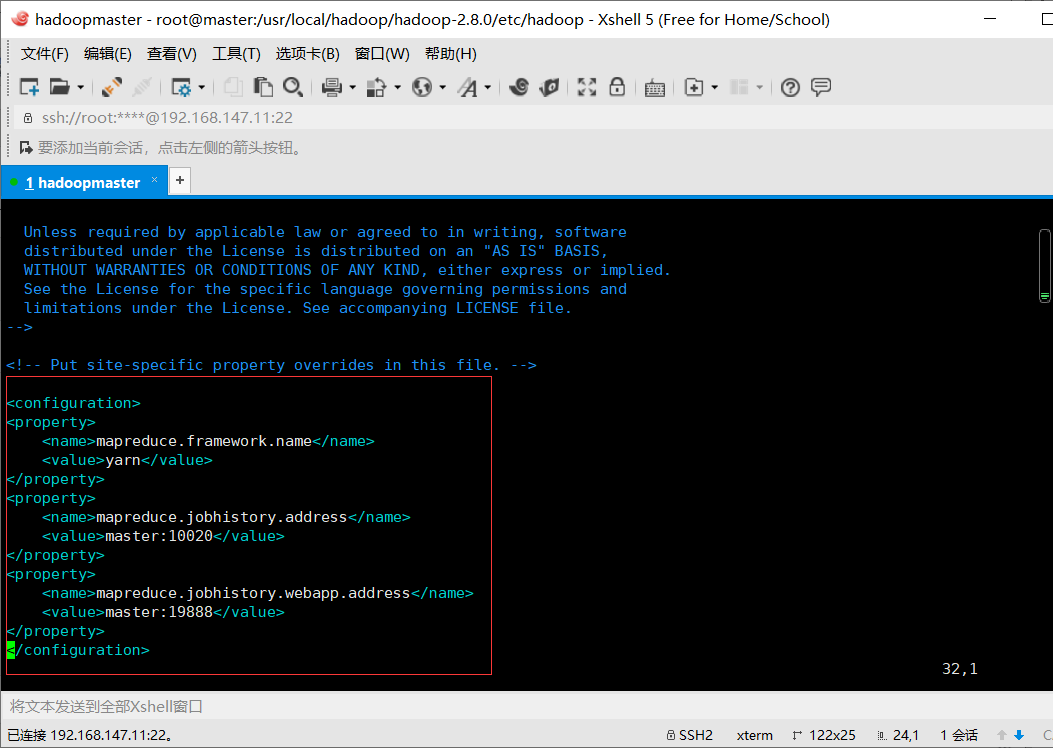
配置mapred-site.xml文件
由于mapred-site.xml文件不存在,需要将mapred-site.xml.template克隆出来一份
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
加入如下内容
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property>
5.克隆主机

克隆完了修改静态ip


1、在master主机上运行如下
hdfs namenode -format
2、启动服务命令
start-all.sh
3、停止集群的命令
stop-all.sh