准备数据与训练
calendar.csv数据集导入。
该数据数聚包含物品的售卖时间与物品类型
- date: The date in a “y-m-d” format.
- wm_yr_wk: The id of the week the date belongs to.
- weekday: The type of the day (Saturday, Sunday, …, Friday).
- wday: The id of the weekday, starting from Saturday.
- month: The month of the date.
- year: The year of the date.
- event_name_1: If the date includes an event, the name of this event.
- event_type_1: If the date includes an event, the type of this event.
- event_name_2: If the date includes a second event, the name of this event.
- event_type_2: If the date includes a second event, the type of this event.
- snap_CA, snap_TX, and snap_WI: A binary variable (0 or 1) indicating whether the stores of CA, TX or WI allow SNAPpurchases on the examined date. 1 indicates that SNAP purchases are allowed.
# Correct data types for "calendar.csv" calendarDTypes = {"event_name_1": "category", "event_name_2": "category", "event_type_1": "category", "event_type_2": "category", "weekday": "category", 'wm_yr_wk': 'int16', "wday": "int16", "month": "int16", "year": "int16", "snap_CA": "float32", 'snap_TX': 'float32', 'snap_WI': 'float32' } # Read csv file calendar = pd.read_csv("./calendar.csv", dtype = calendarDTypes) calendar["date"] = pd.to_datetime(calendar["date"]) calendar.head(10)
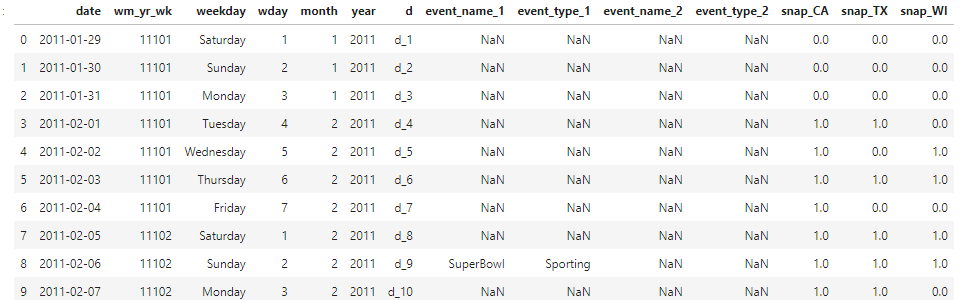

# Transform categorical features into integers for col, colDType in calendarDTypes.items(): if colDType == "category": calendar[col] = calendar[col].cat.codes.astype("int16") calendar[col] -= calendar[col].min() calendar.head(10)
- calendar[col].cat.codes.astype("int16") 这个是属于简单的编码标签类别编码。后面我们尝试改为one编码试试
sell_prices.csv
File 2: “sell_prices.csv”
该数据数聚包含物品的每天每单位的售卖价格
- store_id: The id of the store where the product is sold.
- item_id: The id of the product.
- wm_yr_wk: The id of the week.
- sell_price: The price of the product for the given week/store. The price is provided per week (average across seven days). If not available, this means that the product was not sold during the examined week. Note that although prices are constant at weekly basis, they may change through time (both training and test set).
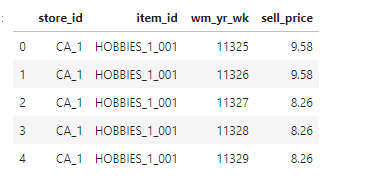
# Correct data types for "sell_prices.csv" priceDTypes = {"store_id": "category", "item_id": "category", "wm_yr_wk": "int16", "sell_price":"float32"} # Read csv file prices = pd.read_csv("./sell_prices.csv", dtype = priceDTypes) prices.head()
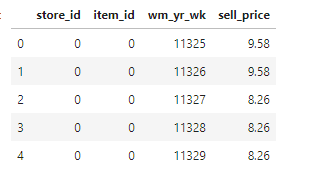
# Transform categorical features into integers for col, colDType in priceDTypes.items(): if colDType == "category": prices[col] = prices[col].cat.codes.astype("int16") prices[col] -= prices[col].min() prices.head()
sales_train_validation.csv
File 3: “sales_train.csv”
Contains the historical daily unit sales data per product and store.
- item_id: The id of the product.
- dept_id: The id of the department the product belongs to.
- cat_id: The id of the category the product belongs to.
- store_id: The id of the store where the product is sold.
- state_id: The State where the store is located.
- d_1, d_2, …, d_i, … d_1941: The number of units sold at day i, starting from 2011-01-29.
firstDay = 250 lastDay = 1913 # Use x sales days (columns) for training numCols = [f"d_{day}" for day in range(firstDay, lastDay+1)] # Define all categorical columns catCols = ['id', 'item_id', 'dept_id','store_id', 'cat_id', 'state_id'] # Define the correct data types for "sales_train_validation.csv" dtype = {numCol: "float32" for numCol in numCols} dtype.update({catCol: "category" for catCol in catCols if catCol != "id"}) [(k,v) for k,v in dtype.items()][:10]

# Read csv file ds = pd.read_csv("./sales_train_validation.csv", usecols = catCols + numCols, dtype = dtype) ds.head()

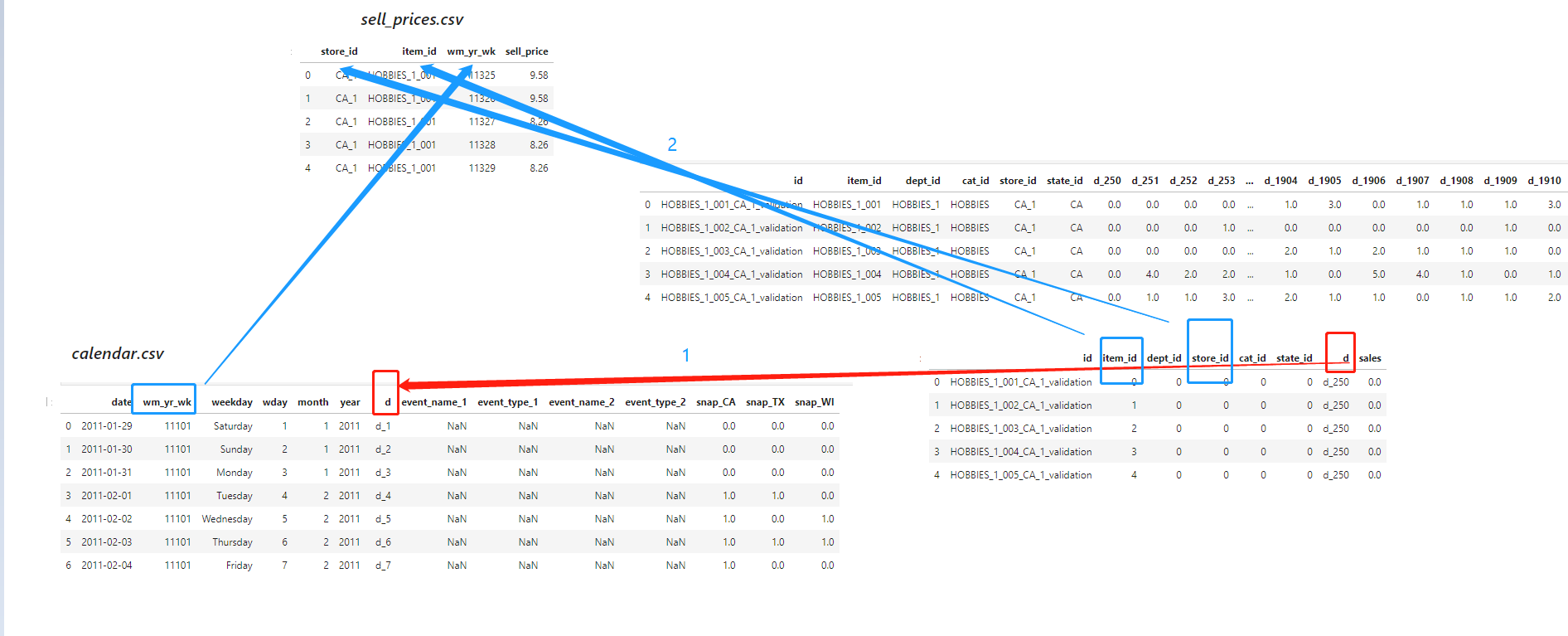
# Transform categorical features into integers for col in catCols: if col != "id": ds[col] = ds[col].cat.codes.astype("int16") ds[col] -= ds[col].min() ds = pd.melt(ds, id_vars = catCols, value_vars = [col for col in ds.columns if col.startswith("d_")], var_name = "d", value_name = "sales") # Merge "ds" with "calendar" and "prices" dataframe ds = ds.merge(calendar, on = "d", copy = False) ds = ds.merge(prices, on = ["store_id", "item_id", "wm_yr_wk"], copy = False) ds.head()
其实3个数据表的关联逻辑如下:
特征工程:
销售额的特征工程
1.构造一个观察窗口
dayLags = [7, 28] lagSalesCols = [f"lag_{dayLag}" for dayLag in dayLags] for dayLag, lagSalesCol in zip(dayLags, lagSalesCols): ds[lagSalesCol] = ds[["id","sales"]].groupby("id")["sales"].shift(dayLag)
这个是shift:见我之前的博客pandas实现hive的lag和lead函数 以及 first_value和last_value函数注意:shift相当于lag
windows = [7, 28] for window in windows: for dayLag, lagSalesCol in zip(dayLags, lagSalesCols): ds[f"rmean_{dayLag}_{window}"] = ds[["id", lagSalesCol]].groupby("id")[lagSalesCol].transform(lambda x: x.rolling(window).mean()) ds.head()

问题如下:
1.为什么要计算滞后的滚动平均值而不是实际值的滚动平均值?
使用目标变量的滞后值的原因是通过对同一模型的多次预测来减少自蔓延误差的影响。 目的是预测每个系列提前28天。因此,要预测系列中的第一天,您可以使用整个系列的销售(直到滞后1)。
但是,要预测第8天,您只有滞后 8的实际数据,而要预测整个系列直到滞后28的实际数据。比赛开始时人们所做的只是使用从落后28并应用回归(例如lightGBM)。
这是最安全的选择,因为它不需要使用“关于预测的预测”。同时,它限制了模型学习更接近于预测值的特征的能力。
即,它在预测第一天时表现不佳,可能会使用该系列中的最新值多于滞后28。此笔记本正在做的事情是在“预测结果”和使用最新的可用信息之间找到平衡。
使用基于具有一定季节性意义的滞后的特征(滞后 7)似乎会产生积极的结果,而只有两个特征(滞后7和均方根 7_7)的自传播误差使过拟合问题得到控制。
日期的特征工程
dateFeatures = {"wday": "weekday",
"week": "weekofyear",
"month": "month",
"quarter": "quarter",
"year": "year",
"mday": "day"}
for featName, featFunc in dateFeatures.items():
if featName in ds.columns:
ds[featName] = ds[featName].astype("int16")
else:
ds[featName] = getattr(ds["date"].dt, featFunc).astype("int16")



<class 'pandas.core.frame.DataFrame'> Int64Index: 42372682 entries, 0 to 42372681 Data columns (total 31 columns): id object item_id int16 dept_id int16 store_id int16 cat_id int16 state_id int16 d object sales float32 date datetime64[ns] wm_yr_wk int16 weekday int16 wday int16 month int16 year int16 event_name_1 int16 event_type_1 int16 event_name_2 int16 event_type_2 int16 snap_CA float32 snap_TX float32 snap_WI float32 sell_price float32 lag_7 float32 lag_28 float32 rmean_7_7 float32 rmean_28_7 float32 rmean_7_28 float32 rmean_28_28 float32 week int16 quarter int16 mday int16 dtypes: datetime64[ns](1), float32(11), int16(17), object(2) memory usage: 4.3+ GB
移除无关列(特征)
# Remove all rows with NaN value ds.dropna(inplace = True) # Define columns that need to be removed unusedCols = ["id", "date", "sales","d", "wm_yr_wk", "weekday"] trainCols = ds.columns[~ds.columns.isin(unusedCols)] X_train = ds[trainCols] y_train = ds["sales"] y_train.head()

切分训练集和测试集
np.random.seed(777) # Define categorical features catFeats = ['item_id', 'dept_id','store_id', 'cat_id', 'state_id'] + ["event_name_1", "event_name_2", "event_type_1", "event_type_2"] validInds = np.random.choice(X_train.index.values, 2_000_000, replace = False) trainInds = np.setdiff1d(X_train.index.values, validInds) trainData = lgb.Dataset(X_train.loc[trainInds], label = y_train.loc[trainInds], categorical_feature = catFeats, free_raw_data = False) validData = lgb.Dataset(X_train.loc[validInds], label = y_train.loc[validInds], categorical_feature = catFeats, free_raw_data = False)
GC:
del ds, X_train, y_train, validInds, trainInds gc.collect()
训练模型
这里是baseline的提供者直接给的代码
params = { "objective" : "poisson", "metric" :"rmse", "force_row_wise" : True, "learning_rate" : 0.075, "sub_row" : 0.75, "bagging_freq" : 1, "lambda_l2" : 0.1, "metric": ["rmse"], 'verbosity': 1, 'num_iterations' : 1200, 'num_leaves': 128, "min_data_in_leaf": 100, }
训练:
# Train LightGBM model m_lgb = lgb.train(params, trainData, valid_sets = [validData], verbose_eval = 20)
模型保存:
# Save the model m_lgb.save_model("model.lgb")
预测:
测试集day > 1913
# Last day used for training trLast = 1913 # Maximum lag day maxLags = 57 # Create dataset for predictions def create_ds(): startDay = trLast - maxLags numCols = [f"d_{day}" for day in range(startDay, trLast + 1)] catCols = ['id', 'item_id', 'dept_id','store_id', 'cat_id', 'state_id'] dtype = {numCol:"float32" for numCol in numCols} dtype.update({catCol: "category" for catCol in catCols if catCol != "id"}) ds = pd.read_csv("./sales_train_validation.csv", usecols = catCols + numCols, dtype = dtype) for col in catCols: if col != "id": ds[col] = ds[col].cat.codes.astype("int16") ds[col] -= ds[col].min() for day in range(trLast + 1, trLast+ 28 +1): ds[f"d_{day}"] = np.nan ds = pd.melt(ds, id_vars = catCols, value_vars = [col for col in ds.columns if col.startswith("d_")], var_name = "d", value_name = "sales") ds = ds.merge(calendar, on = "d", copy = False) ds = ds.merge(prices, on = ["store_id", "item_id", "wm_yr_wk"], copy = False) return ds def create_features(ds): dayLags = [7, 28] lagSalesCols = [f"lag_{dayLag}" for dayLag in dayLags] for dayLag, lagSalesCol in zip(dayLags, lagSalesCols): ds[lagSalesCol] = ds[["id","sales"]].groupby("id")["sales"].shift(dayLag) windows = [7, 28] for window in windows: for dayLag, lagSalesCol in zip(dayLags, lagSalesCols): ds[f"rmean_{dayLag}_{window}"] = ds[["id", lagSalesCol]].groupby("id")[lagSalesCol].transform(lambda x: x.rolling(window).mean()) dateFeatures = {"wday": "weekday", "week": "weekofyear", "month": "month", "quarter": "quarter", "year": "year", "mday": "day"} for featName, featFunc in dateFeatures.items(): if featName in ds.columns: ds[featName] = ds[featName].astype("int16") else: ds[featName] = getattr(ds["date"].dt, featFunc).astype("int16")
最后:
fday = datetime(2016,4, 25) alphas = [1.028, 1.023, 1.018] weights = [1/len(alphas)] * len(alphas) sub = 0. for icount, (alpha, weight) in enumerate(zip(alphas, weights)): te = create_ds() cols = [f"F{i}" for i in range(1,29)] for tdelta in range(0, 28): day = fday + timedelta(days=tdelta) print(tdelta, day) tst = te[(te['date'] >= day - timedelta(days=maxLags)) & (te['date'] <= day)].copy() create_features(tst) tst = tst.loc[tst['date'] == day , trainCols] te.loc[te['date'] == day, "sales"] = alpha * m_lgb.predict(tst) # magic multiplier by kyakovlev te_sub = te.loc[te['date'] >= fday, ["id", "sales"]].copy() te_sub["F"] = [f"F{rank}" for rank in te_sub.groupby("id")["id"].cumcount()+1] te_sub = te_sub.set_index(["id", "F" ]).unstack()["sales"][cols].reset_index() te_sub.fillna(0., inplace = True) te_sub.sort_values("id", inplace = True) te_sub.reset_index(drop=True, inplace = True) te_sub.to_csv(f"submission_{icount}.csv",index=False) if icount == 0 : sub = te_sub sub[cols] *= weight else: sub[cols] += te_sub[cols]*weight print(icount, alpha, weight) sub2 = sub.copy() sub2["id"] = sub2["id"].str.replace("validation$", "evaluation") sub = pd.concat([sub, sub2], axis=0, sort=False) sub.to_csv("submission.csv",index=False)
结果:
0 2016-04-25 00:00:00 1 2016-04-26 00:00:00 2 2016-04-27 00:00:00 3 2016-04-28 00:00:00 4 2016-04-29 00:00:00 5 2016-04-30 00:00:00 6 2016-05-01 00:00:00 7 2016-05-02 00:00:00 8 2016-05-03 00:00:00 9 2016-05-04 00:00:00 10 2016-05-05 00:00:00 11 2016-05-06 00:00:00 12 2016-05-07 00:00:00 13 2016-05-08 00:00:00 14 2016-05-09 00:00:00 15 2016-05-10 00:00:00 16 2016-05-11 00:00:00 17 2016-05-12 00:00:00 18 2016-05-13 00:00:00 19 2016-05-14 00:00:00 20 2016-05-15 00:00:00 21 2016-05-16 00:00:00 22 2016-05-17 00:00:00 23 2016-05-18 00:00:00 24 2016-05-19 00:00:00 25 2016-05-20 00:00:00 26 2016-05-21 00:00:00 27 2016-05-22 00:00:00 0 1.028 0.3333333333333333 0 2016-04-25 00:00:00 1 2016-04-26 00:00:00 2 2016-04-27 00:00:00 3 2016-04-28 00:00:00 4 2016-04-29 00:00:00 5 2016-04-30 00:00:00 6 2016-05-01 00:00:00 7 2016-05-02 00:00:00 8 2016-05-03 00:00:00 9 2016-05-04 00:00:00 10 2016-05-05 00:00:00 11 2016-05-06 00:00:00 12 2016-05-07 00:00:00 13 2016-05-08 00:00:00 14 2016-05-09 00:00:00 15 2016-05-10 00:00:00 16 2016-05-11 00:00:00 17 2016-05-12 00:00:00 18 2016-05-13 00:00:00 19 2016-05-14 00:00:00 20 2016-05-15 00:00:00 21 2016-05-16 00:00:00 22 2016-05-17 00:00:00 23 2016-05-18 00:00:00 24 2016-05-19 00:00:00 25 2016-05-20 00:00:00 26 2016-05-21 00:00:00 27 2016-05-22 00:00:00 1 1.023 0.3333333333333333 0 2016-04-25 00:00:00 1 2016-04-26 00:00:00 2 2016-04-27 00:00:00 3 2016-04-28 00:00:00 4 2016-04-29 00:00:00 5 2016-04-30 00:00:00 6 2016-05-01 00:00:00 7 2016-05-02 00:00:00 8 2016-05-03 00:00:00 9 2016-05-04 00:00:00 10 2016-05-05 00:00:00 11 2016-05-06 00:00:00 12 2016-05-07 00:00:00 13 2016-05-08 00:00:00 14 2016-05-09 00:00:00 15 2016-05-10 00:00:00 16 2016-05-11 00:00:00 17 2016-05-12 00:00:00 18 2016-05-13 00:00:00 19 2016-05-14 00:00:00 20 2016-05-15 00:00:00 21 2016-05-16 00:00:00 22 2016-05-17 00:00:00 23 2016-05-18 00:00:00 24 2016-05-19 00:00:00 25 2016-05-20 00:00:00 26 2016-05-21 00:00:00 27 2016-05-22 00:00:00 2 1.018 0.3333333333333333
未完结。。。明天写改善思路