损失函数
是用来衡量一个预测器在对输入数据进行分类预测时的质量好坏。损失值越小,分类器的效果越好,越能反映输入数据与输出类别标签的关系(虽然我们的模型有时候会过拟合——这是由于训练数据被过度拟合,导致我们的模型失去了泛化能力)。
相反,损失值越大,我们需要花更多的精力来提升模型的准确率。就参数化学习而言,这涉及到调整参数,比如需要调节权重矩阵W或偏置向量B,以提高分类的精度。
Hinge Loss
多分类svm:
损失函数的计算方法为:,其中i代表第i个样品,j代表第j个种类,那么y_i代表第i个
样品的真实种类。
其中,常用的数学表达式为:,但为了与代码中的统一,从而稍微变动以下
,对于y_i来说同理。
计算正确类的预测值,和其他类的预测值之间的差距,如果正确类的预测值大于所有不正确的预测值则损失函数为0,证明当前的W和b所计算得到的效果很好。
当把损失值推广到整个训练数据集,则应为: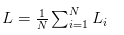
两分类SVM:
在二分类情况下,铰链函数公式如下:
L(y) = max(0 , 1 – t⋅y)
其中,y是预测值(-1到1之间),t为目标值(1或 -1)。其含义为:y的值在 -1到1之间即可,并不鼓励 |y|>1,即让某个样本能够正确分类就可以了,不鼓励分类器过度自信,当样本与分割线的距离超过1时并不会有任何奖励。目的在于使分类器更专注于整体的分类误差。
计算案例

三个图片的损失和整体损失:
