现象:
Numpy区分了str和object类型,其中dtype(‘S’)和dtype(‘O’)分别对应于str和object.
然而,pandas缺乏这种区别 str和object类型都对应dtype(‘O’)类型,即使强制类型为dtype(‘S’)也无济于事
>>> import pandas as pd >>> import numpy as np >>> >>> >>> np.dtype(str) dtype('S') >>> np.dtype(object) >>> >>> dtype('O') >>> df = pd.DataFrame({'a': np.arange(5)}) >>> df a 0 0 1 1 2 2 3 3 4 4 >>> df.a.dtype dtype('int64') >>> df.a.astype(str).dtype dtype('O') >>> df.a.astype(object).dtype dtype('O') >>> df.a.astype(str).dtype dtype('O')
原理:
先说结论:
Numpy的字符串dtypes不是python字符串.pandas使用python字符串,.
numpy与pandas的字符串不同的含义:
>>> x = np.array(['Testing', 'a', 'string'], dtype='|S7') >>> x array([b'Testing', b'a', b'string'], dtype='|S7') >>> >>> >>> y = np.array(['Testing', 'a', 'string'], dtype=object) >>> y array(['Testing', 'a', 'string'], dtype=object)
现在,一个是numpy字符串dtype(固定宽度,类似c的字符串),另一个原生python字符串数组.
如果我们试图超过7个字符,我们会看到立即的差异.numpy字符串dtype版本将被截断,而numpy对象dtype版本可以是任意长度
>>> x[1] = 'a really really really long' >>> x array([b'Testing', b'a reall', b'string'], dtype='|S7') >>> >>> y[1] = 'a really really really long' >>> y array(['Testing', 'a really really really long', 'string'], dtype=object)
尽管存在unicode固定长度字符串dtype,但| s dtype字符串不能正确地保持unicode
最后,numpy的字符串实际上是可变的,而Python字符串则不是.
>>> z = x.view(np.uint8) >>> z array([ 84, 101, 115, 116, 105, 110, 103, 97, 32, 114, 101, 97, 108, 108, 115, 116, 114, 105, 110, 103, 0], dtype=uint8) >>> z+=1 >>> x array([b'Uftujoh', b'b!sfbmm', b'tusjohx01'], dtype='|S7')
由于所有这些原因,pandas选择不允许类似C的固定长度字符串作为数据类型.
正如所注意到的那样,尝试将python字符串强制转换为固定的numpy字符串将无法在pandas中使用.相反,它总是使用本机python字符串,对大多数用户来说,它的行为更直观.
那为什么np.view可以验证
NumPy文档里对ndarray.view方法的说明:
-
ndarray.view(dtype=None, type=None)
-
New view of array with the same data。
-
返回数据的新视图。
除了view()方法,还有我们熟悉的reshape()方法也可以返回一个视图,至于其他方法也可以返回视图
import numpy as np a = np.arange(10) b = a.reshape(5,2) c = a.view() c.shape = (2,5) a_base = a.base b_base = b.base c_base = c.base a_base, b_base, c_base (None, array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]), array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]))
对程序的说明,
-
首先创建一个具有10个数据的1维数组a,shape为(10, )。
-
b是reshape方法返回的a的一个视图(view),此时b是一个2维数组,它的shape为(5,2)。
-
c是view方法返回的a的一个视图,此时c的shape为(10, ),当执行c.shape = (2, 5)后c的shape变为(2, 5)。
-
b_base和c_base说明b和c只是a的一个视图,共享a的数据,虽然它们的shape各不相同。
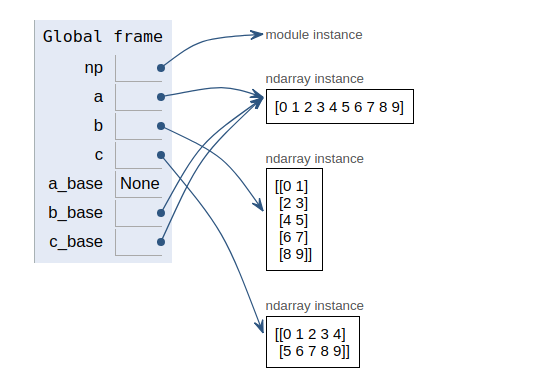
接着我们来看看各个数组的base,
>>>a.base is None True >>>b.base is a True >>>c.base is a True
如果一个数组的base是None,说明这个数组的数据是自己的,它是这个数据的所有者;如果不是None,则说明数据在不是自己的,他只能通过数据拥有者才能访问。
如果两个数组的base相同,说明它们指向同一个数据拥有者。
ndarray.base
-
NumPy文档说明: Base object if memory is from some other object.
-
base对象说明数据是否来自别的对象。
-
上面这个例子,a.base是None,说明a自己拥有数据,不是来自别人的,而b和c的base都是a,说明它们都没有自己的数据,都是a的。
下面代码的运行结果表明,这三个数组中只有a是数据的所有者,而b和c都不是。
a.flags.owndata, b.flags.owndata, c.flags.owndata
结果:(True, False, False)
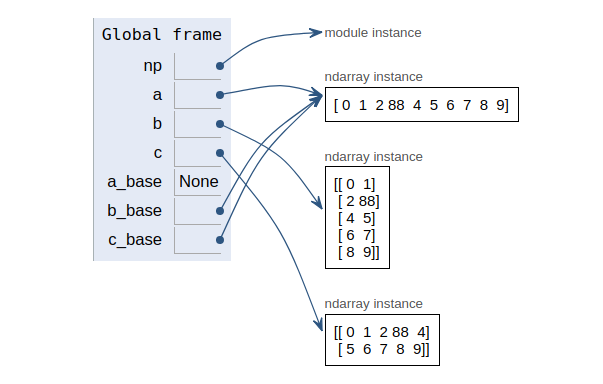
验证:
b[1,1] = 88
把原来的3改成了88。结果我们看下图,三个数组里的3同时被改成88。