1.Common/Shuffle/Reduce Join
Reduce Join在Hive中也叫Common Join或Shuffle Join
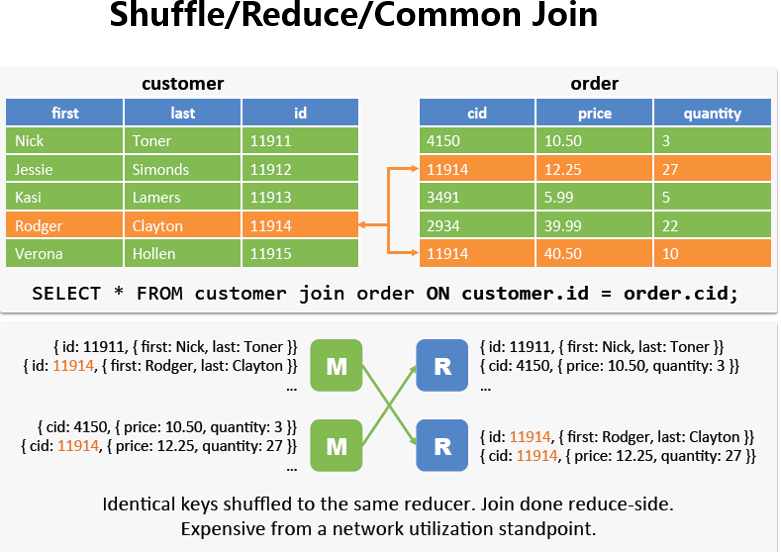
如果两边数据量都很大,它会进行把相同key的value合在一起,正好符合我们在sql中的join,然后再去组合,如图所示。
2.Map Join
- 1) 大小表连接:
- 如果一张表的数据很大,另外一张表很少(<1000行),那么我们可以将数据量少的那张表放到内存里面,在map端做join。
- Hive支持Map Join,用法如下
-
select /*+ MAPJOIN(time_dim) */ count(1) from store_sales join time_dim on (ss_sold_time_sk = t_time_sk)
2) 需要做不等值join操作(a.x < b.y 或者 a.x like b.y等)
-
这种操作如果直接使用join的话语法不支持不等于操作,hive语法解析会直接抛出错误
如果把不等于写到where里会造成笛卡尔积,数据异常增大,速度会很慢。甚至会任务无法跑成功~
根据mapjoin的计算原理,MapJoin会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配。这种情况下即使笛卡尔积也不会对任务运行速度造成太大的效率影响。
而且hive的where条件本身就是在map阶段进行的操作,所以在where里写入不等值比对的话,也不会造成额外负担。
select /*+ MAPJOIN(a) */ a.start_level, b.* from dim_level a join (select * from test) b where b.xx>=a.start_level and b.xx<end_level;
3) MAPJOIN 结合 UNIONALL
原始sql:select a.*,coalesce(c.categoryid,’NA’) as app_category from (select * from t_aa_pvid_ctr_hour_js_mes1 ) a left outer join (select * fromt_qd_cmfu_book_info_mes ) c on a.app_id=c.book_id;
速度很慢,老办法,先查下数据分布:
select * from (selectapp_id,count(1) cnt fromt_aa_pvid_ctr_hour_js_mes1 group by app_id) t order by cnt DESC limit 50;
数据分布如下:
NA 617370129 2 118293314 1 40673814 d 20151236 b 1846306 s 1124246 5 675240 8 642231 6 611104 t 596973 4 579473 3 489516 7 475999 9 373395 107580 10508
我们可以看到除了NA是有问题的异常值,还有appid=1~9的数据也很多,而这些数据是可以关联到的,所以这里不能简单的随机函数了。而t_qd_cmfu_book_info_mes这张app库表,又有几百万数据,太大以致不能放入内存使用mapjoin。
解决方:首先将appid=NA和1到9的数据存入一组,并使用mapjoin与维表(维表也限定appid=1~9,这样内存就放得下了)关联,而除此之外的数据存入另一组,使用普通的join,最后使用union all 放到一起。
select a.*,coalesce(c.categoryid,’NA’) as app_category from --if app_id is not number value or <=9,then not join (select * from t_aa_pvid_ctr_hour_js_mes1 where cast(app_id as int)>9 ) a left outer join (select * from t_qd_cmfu_book_info_mes where cast(book_id as int)>9) c on a.app_id=c.book_id union all select /*+ MAPJOIN(c)*/ a.*,coalesce(c.categoryid,’NA’) as app_category from --if app_id<=9,use map join (select * from t_aa_pvid_ctr_hour_js_mes1 where coalesce(cast(app_id as int),-999)<=9) a left outer join (select * fromt_qd_cmfu_book_info_mes where cast(book_id as int)<=9) c --if app_id is not number value,then not join on a.app_id=c.book_id;
- 设置:
-
当然也可以让hive自动识别,把join变成合适的Map Join如下所示
注:当设置为true的时候,hive会自动获取两张表的数据,判定哪个是小表,然后放在内存中
set hive.auto.convert.join=true; select count(*) from store_sales join time_dim on (ss_sold_time_sk = t_time_sk)
3.SMB(Sort-Merge-Buket) Join
- 场景:
-
大表对小表应该使用MapJoin,但是如果是大表对大表,如果进行shuffle,那就要人命了啊,第一个慢不用说,第二个容易出异常,既然是两个表进行join,肯定有相同的字段吧。
-
tb_a - 5亿(按排序分成五份,每份1亿放在指定的数值范围内,类似于分区表)
a_id
100001 ~ 110000 - bucket-01-a -1亿
110001 ~ 120000
120001 ~ 130000
130001 ~ 140000
140001 ~ 150000 -
tb_b - 5亿(同上,同一个桶只能和对应的桶内数据做join)
b_id
100001 ~ 110000 - bucket-01-b -1亿
110001 ~ 120000
120001 ~ 130000
130001 ~ 140000
140001 ~ 150000 -
注:实际生产环境中,一天的数据可能有50G(举例子可以把数据弄大点,比如说10亿分成1000个bucket)。
- 原理:
-
在运行SMB Join的时候会重新创建两张表,当然这是在后台默认做的,不需要用户主动去创建,如下所示:
-

设置(默认是false):
set hive.auto.convert.sortmerge.join=true set hive.optimize.bucketmapjoin=true; set hive.optimize.bucketmapjoin.sortedmerge=true;
hive中 bucket mapjoin 与 SMB join(Sort-Merge-Bucket)区别:
1 bucket mapjoin
1.1 条件
1) set hive.optimize.bucketmapjoin = true;
2) 一个表的bucket数是另一个表bucket数的整数倍
3) bucket列 == join列
4) 必须是应用在map join的场景中1.2 注意
1)如果表不是bucket的,只是做普通join。
2 SMB join (针对bucket mapjoin 的一种优化)
2.1 条件
1)
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
2) 小表的bucket数=大表bucket数
3) Bucket 列 == Join 列 == sort 列
4) 必须是应用在bucket mapjoin 的场景中2.2 注意
hive并不检查两个join的表是否已经做好bucket且sorted,需要用户自己去保证join的表,否则可能数据不正确。有两个办法
1)hive.enforce.sorting 设置为true。
2)手动生成符合条件的数据,通过在sql中用distributed c1 sort by c1 或者 cluster by c1
表创建时必须是CLUSTERED且SORTED,如下
create table test_smb_2(mid string,age_id string)
CLUSTERED BY(mid) SORTED BY(mid) INTO 500 BUCKETS; -