2019年1月8日,付哥给了我一份公司以前的一份SQL优化方案文档。十分感谢。记录了许多在公司以前优化的案例。
--------------------------------------------------------------------------------------------------------------------------------------------------------
一、表TMP_c(58分钟)
表来源:
1.IML_a 这张表在2018年11月某一天的数据量是22025054
2.TMP_b 这表数据量是12条
优化点:
1.两张表关联的时候把BATCH_DATE的字段放在on后面,不要放在where后面。
2.大表关联小表可以使用MAPJOIN,指定MAPJOIN使用/*+mapjoin(b)+/
3.代码使用了三层嵌套查询,还可以把每一层提出放到临时表并行运行
第一点以前也用过但是具体为什么一直也没注意。今天要总结一下:
通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。
在使用left jion时,on和where条件的区别如下:
我们假设有如下两张表

两条SQL:
1、select * form tab1 left join tab2 on (tab1.size = tab2.size) where tab2.name=’AAA’
2、select * form tab1 left join tab2 on (tab1.size = tab2.size and tab2.name=’AAA’)
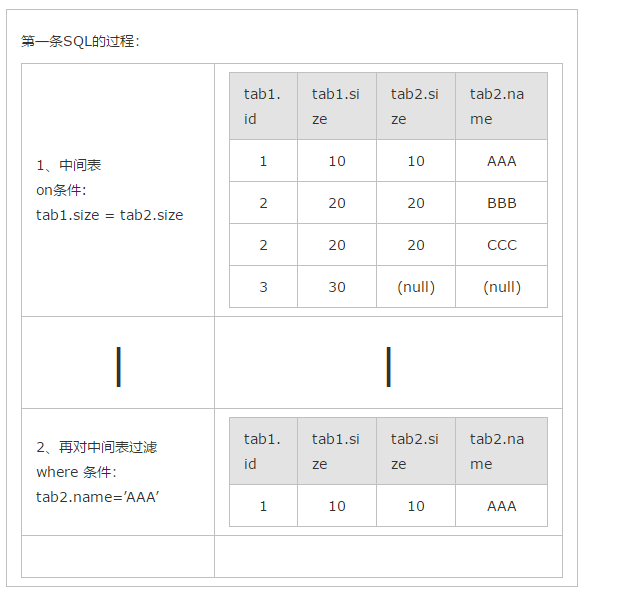
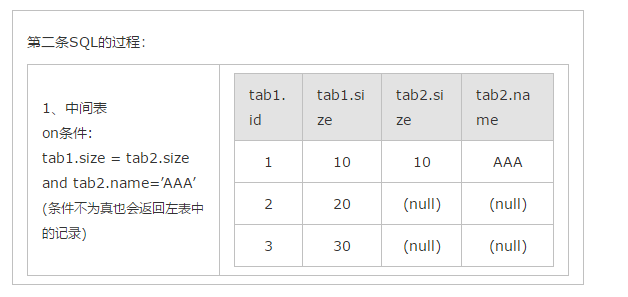
其实以上结果的关键原因就是left join,right join,full join的特殊性,不管on上的条件是否为真都会返回left或right表中的记录,full则具有left和right的特性的并集。
而inner jion没这个特殊性,则条件放在on中和where中,返回的结果集是相同的。
使用第二种中间表确实小了很多。减少了内存使用。======》》》可能是这样吧。
二、表TMP_c(58分钟)