有一个面试题目, 有一张表,如下:
event_type value time 2 5 12:42 4 -42 13:19 2 2 14:48 2 7 12:54 3 16 13:19 3 20 15:01
需要按照event_type排序,返回同一个event_type的,最近时间和次近时间的两个value的差值.
比如event_type为2的,最近时间是14:48,value值为2
接下来的次近时间是12:54,value值为7. 所以差值为 2-7 = -5
所以整个表按照这个规则的结果是
event_type value 2 -5 3 4
要实现这个功能,需要使用到SQL中的row_number()函数。 在MSDN上,row_number()函数语法如下:
ROW_NUMBER ( )
OVER ( [ PARTITION BY value_expression , ... [ n ] ] order_by_clause )
通过该语法可以看出,row_number的over里面有两个参数。一个是partition by, 另一个是order by
其中, partition by 是可选参数,可以写可以不写
order by 是必选参数,必须要有.
为了更好的明白如何使用它,我举个例子如下
表 TESTDB
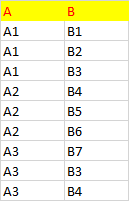
首先,仅仅使用ROW_NUMBER() 中的必选参数, SQL语句如下
SELECT *, ROW_NUMBER() OVER(ORDER BY A DESC) NUM FROM TESTDB
返回结果集如下:

可以看出,它就是单纯的按照A列进行降序排序,然后每一行加了一个行号
那么,如果加上partition by 之后呢 (partition的中文解释是: 划分,分开,分割,区分),会出现什么效果,语句如下:
SELECT *, ROW_NUMBER() OVER(PARTITION BY A ORDER BY A) NUM FROM TESTDB
返回结果集如下:

从这个结果可以看出,partition by A,是以A进行了分组划分。对于A=A1的那三行,标上行号1,2,3
对于A=A2的那三行,重新标上行号1,2,3 而不是接上A1的行号,变成4,5,6...
我们知道聚合函数Group by 也是可以用来分组,那和这里的PARTITION BY 有啥区别呢
Group by 聚合函数一般只有一条反映统计值的记录
而Partition by 能返回一个分组中的多条记录,partition by 用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组.
以下是一些使用ROW_NUMBER()函数的实例
1. 使用row_number()函数进行编号,eg:
select email, customerID, ROW_NUMBER() over(order by psd) as rows from QT_Customer
原理: 先按照psd进行排序,排序完成后,给每天数据进行编号
2. 在订单中按价格的升序进行排序,并给每条记录进行排序代码如下:
select DID, customerID, totalPrice, ROW_NUMBER() over(order by totalPrice) as rows from OP_Order
3. 统计出每一个客户的所有订单并按每一个客户下的订单的金额 升序排序,同时给每一个客户的订单进行编号。这样,就知道每个客户下几单了
select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows, customerID, totalPrice, DID from OP_Order
4. 统计每一个客户最近下的订单是第几次下的订单
with tabs as (select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows, customerID, totalPrice, DID from OP_Order) select MAX(rows) AS '下单次数', customerID from tabs group by customerID.
5. 统计每一个客户所有的订单中购买的金额最小,而且统计订单中,客户是第几次购买
思路: 利用临时表来执行这一个操作
1) 先按客户进行分组,然后按照客户的下单的时间进行排序,并进行编号
2) 然后利用子查询查找出每一个客户购买时的最小价格
3) 根据查找出每一个客户的最小价格来查找相应的记录
with tabs as (select ROW_NUMBER() over(partition by customerID order by insDT) as rows, customerID,totalPrice, DID from OP_Order)
select * from tabs where totalPrice in (select MIN(totalPrice) from tabs group by customerID)
6. 筛选出客户第一次下的订单
思路: 利用rows=1来查询客户第一次下的订单记录
with tabs as (select ROW_NUMBER() over(partition by customerID order by insDT) as rows, * from OP_Order)
select * from tabs where rows =1
7. 在使用over等开窗函数时,over里头的分组及排序的执行晚于"where,group by, order by"的执行
eg: select ROW_NUMBER() over(partition by customerID order by insDT) as rows, customerID, totalPrice, DID from OP_Order where insDT > '2011-07-22'
以上代码是先执行where子句,执行完后,再给每一条记录编号.
回到开头那个例子,SQL语句,应该写成如下:
SELECT bb.event_type, SUM(CASE BB.id WHEN 1 THEN BB.[value] ELSE 0 END) -SUM(CASE BB.id WHEN 2 THEN BB.[value] ELSE 0 END) num1 FROM ( SELECT row_number() over(partition by [event_type] order by [time] desc) as id,[event_type],[value],[time] FROM [MaxMindDB].[dbo].[Test] a WHERE EXISTS(SELECT 1 FROM ( SELECT count(*) AS num,[event_type] FROM [MaxMindDB].[dbo].[Test] GROUP BY [event_type]) AS AA WHERE AA.event_type=a.event_type AND AA.num>=2) ) BB GROUP BY BB.event_type