C# 识别文字我试验过的有两种,
1.使用开源库tesseract,地址:https://github.com/tesseract-ocr/tesseract
tesseract训练的语言包:https://github.com/tesseract-ocr/tessdata
有专门针对C#的封装:https://github.com/charlesw/tesseract
C# Demo地址:https://github.com/charlesw/tesseract-samples
2.调用百度API,百度的API已经开源了:https://github.com/Baidu-AIP/dotnet-sdk
一、使用开源库tesseract
新建一个Winform的项目,打开Nuget程序管理包,搜索Tesseract,选择第一个,不要选择Tesseract.Net.SDK,因为这个是收费的!!!,等你用着用着就弹出框来提示收费!!!
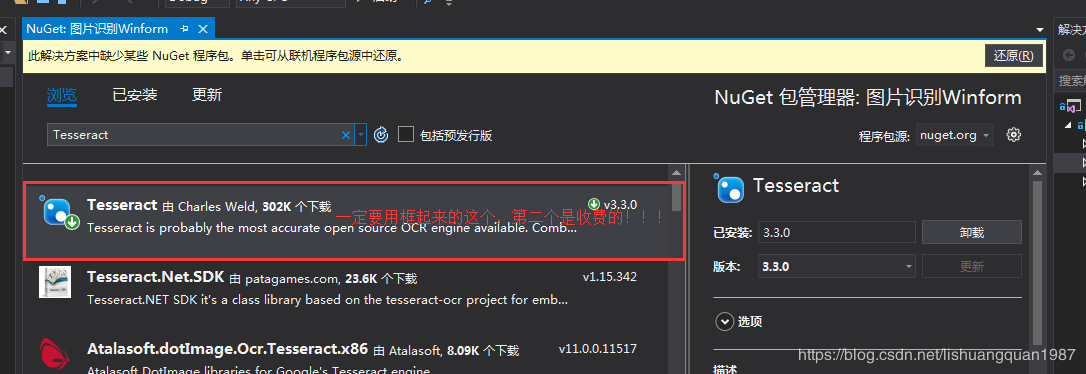
安装完毕之后,去上面的Github上面下载语言包:
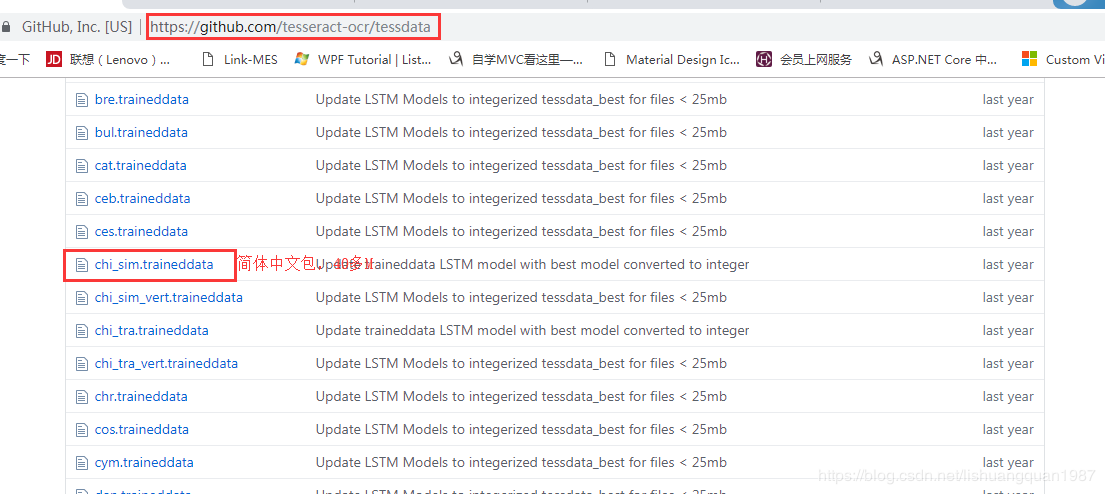
将语言包下载之后放在程序目录的tessdata文件夹下面:

下面开始写代码了,参考Demo里,来写一波:以下函数是识别图片里的商品号:
private List<string> GetProductNumberFromImage(string imagePath) { List<string> resultList = new List<string>(); using (var ocr = new TesseractEngine(Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "tessdata"), "chi_sim",EngineMode.Default)) { var pix = PixConverter.ToPix(new Bitmap(imagePath)); using (var page = ocr.Process(pix)) { string text = page.GetText(); if (!string.IsNullOrEmpty(text)) { string pattern = @"品号([sS])(d+)"; Regex regex = new Regex(pattern); var mathResult = regex.Matches(text); foreach (Match item in mathResult) { if (item.Groups.Count >= 2) { resultList.Add(item.Groups[2].Value); } else { resultList.Add(item.Value); } } } } } return resultList; }
识别的图片如下:
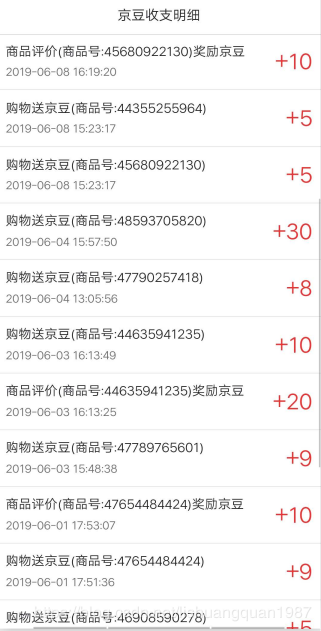
识别之后的文字如下:

识别效果不怎么好
二、使用百度API
要使用百度API,首先要有百度账号,然后登陆百度云,在这里登陆:https://login.bce.baidu.com/
登陆进去后,选择产品服务-》人工智能-》文字识别:
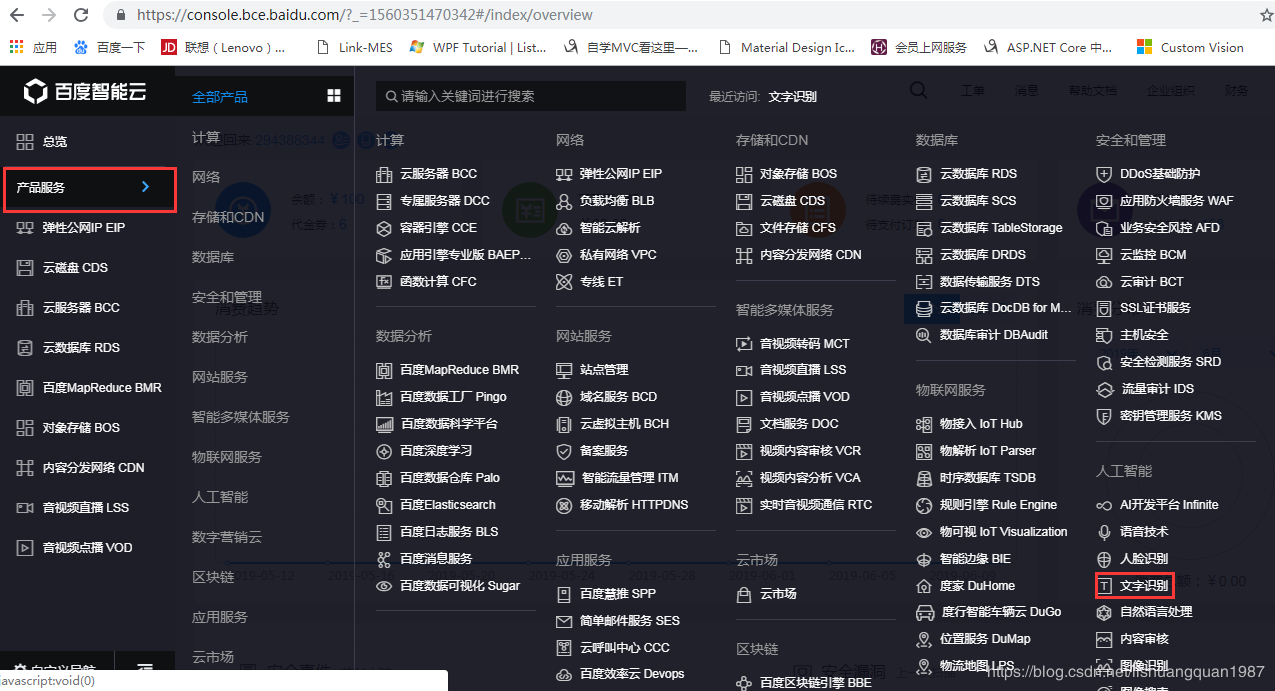
然后开通通用文字识别功能:
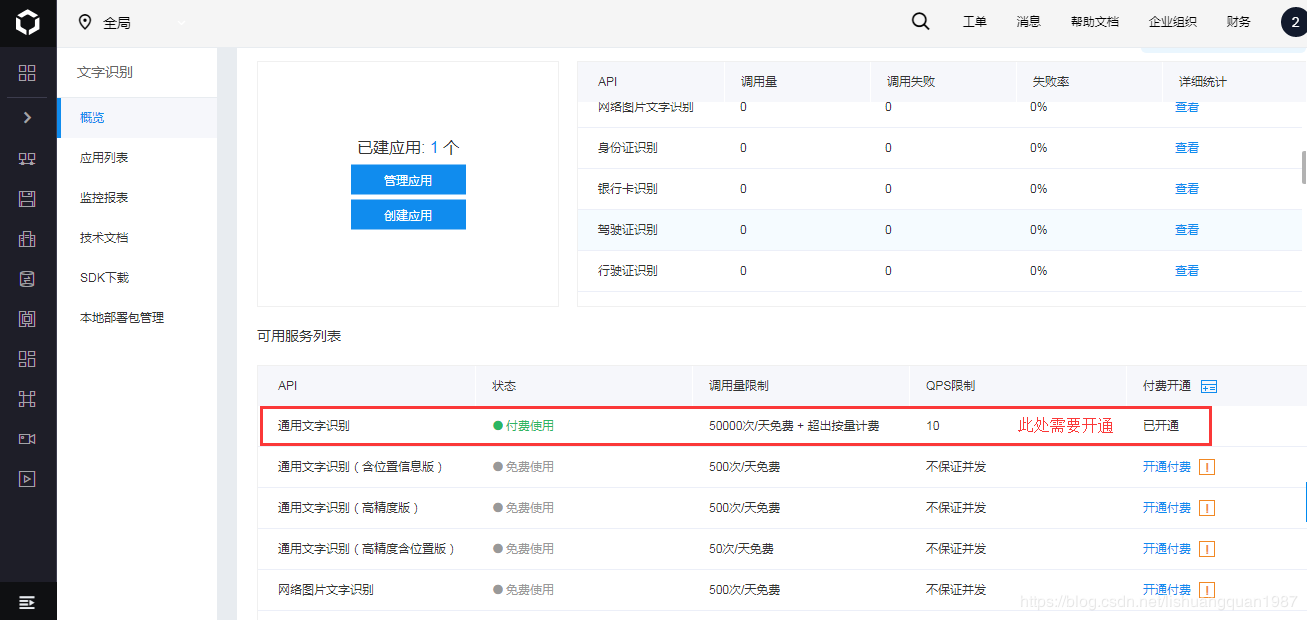
开通功能后,需要创建一个应用:文字识别包选择不需要
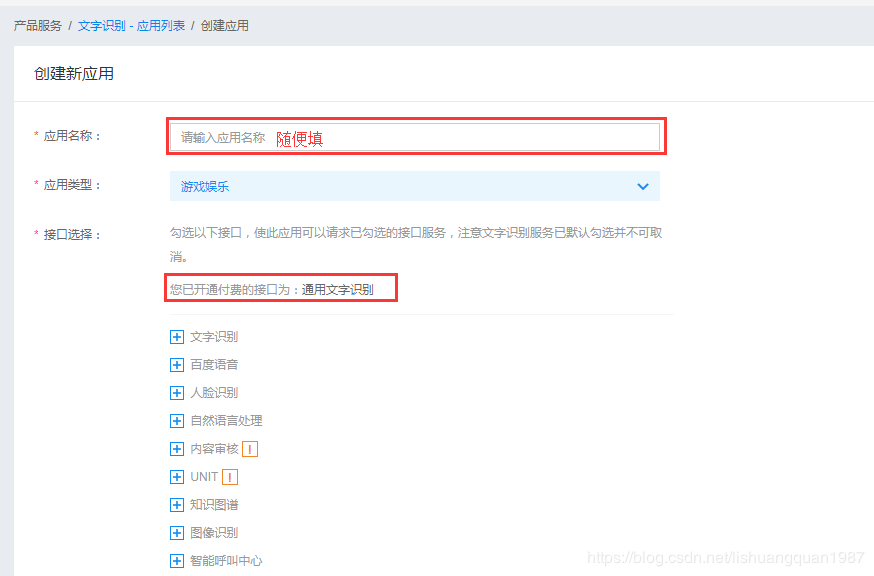
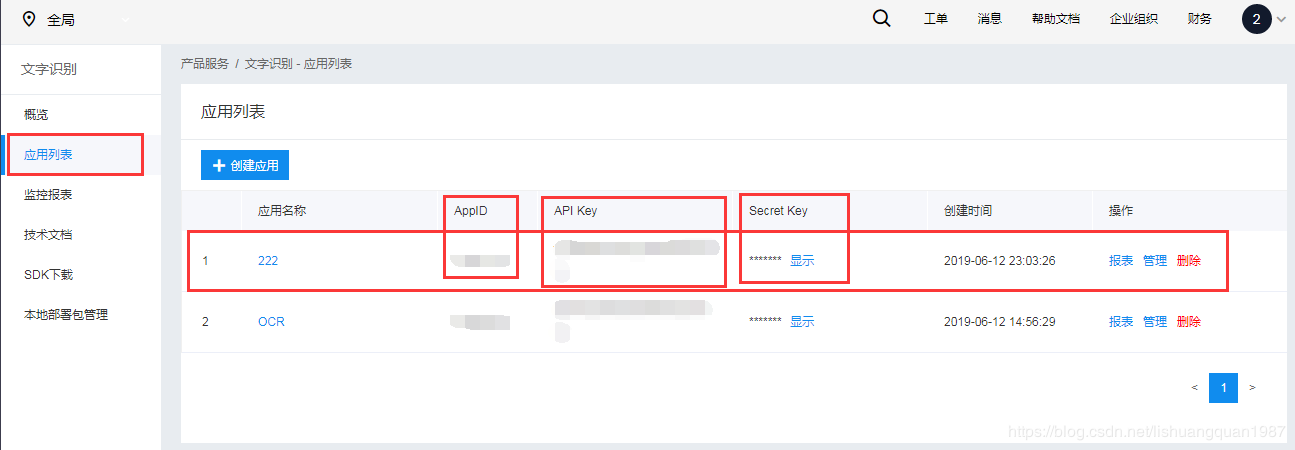
然后点确定,在应用列表中,可以看到你的应用:里面有API KEY/Secret Key
在VS中新建一个窗体应用程序,然后在Nuget中搜索Baidu:
点击安装,然后开始写代码了:
api_key, secret_key为上面网页中的API KEY/Secret Key字符串
初始化client:
var client = new Baidu.Aip.Ocr.Ocr(api_key, secret_key); client.Timeout = 60000;
识别图片中的文字:
var image = File.ReadAllBytes(imagePath); var result = client.GeneralBasic(image).ToString();
同样识别上面的图片,结果如下:
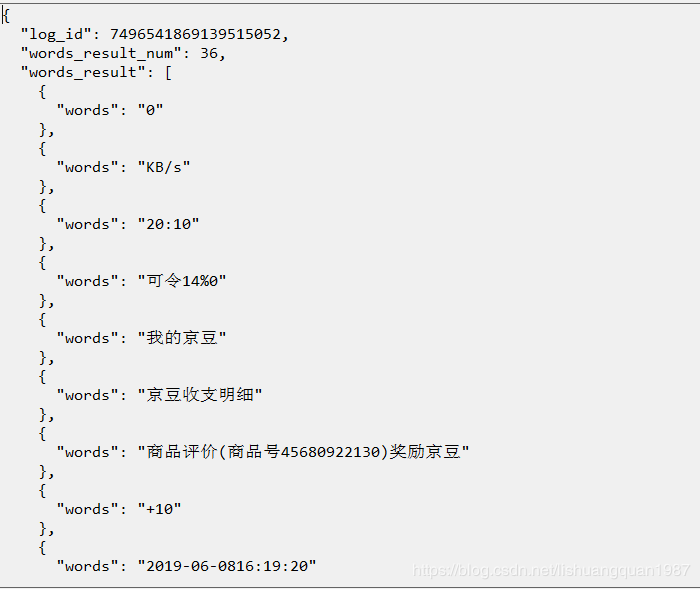
识别率高了很多,更多百度API使用,请参考百度官方文档:
https://cloud.baidu.com/doc/OCR/OCR-Csharp-SDK.html#.E9.80.9A.E7.94.A8.E6.96.87.E5.AD.97.E8.AF.86.E5.88.AB