之前我们爬取的都是那些无需登录就要可以使用的网站但是当我们想爬取自己或他人的个人中心时就需要做登录,一般进入登录页面有两种 ,一个是独立页面登陆,另一个是弹窗,我们先不管验证码登陆的问题 ,现在试一下直接登陆的爬取:
爬虫是模拟人的行为来请求网页读取数据的现在我们划分一下过程,从登陆到获取:
先看一下我们到个人中心的过程:
登陆界面->输入账号密码->进入个人中心
1 进入登陆页面 可以说是第一次请求 此时会产生相应的COOKIE值,因为你只要先进入到页面才可以进行密码输入等行为
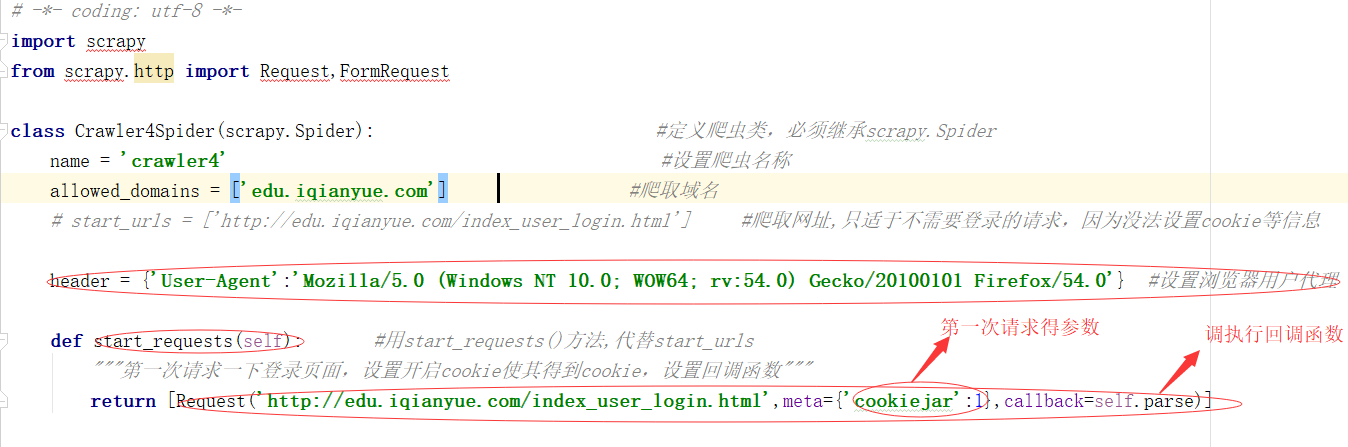
cookiejar:1表示开启COOKIE记录
现在看下回调函数:
2 进入登陆页面后需要进行输入数据行为,方式为POST请求,传输的数据在NETWORK里找一下字段 ,一般都是NUMBER,USERNAME什么的 作为POST携带的数据

看下结果

3 之前请求的是登陆页面用的是GET请求,现在需要做一步登陆的过程就变成了POST请求,也就是第二步请求,同样的是在parse函数里执行了
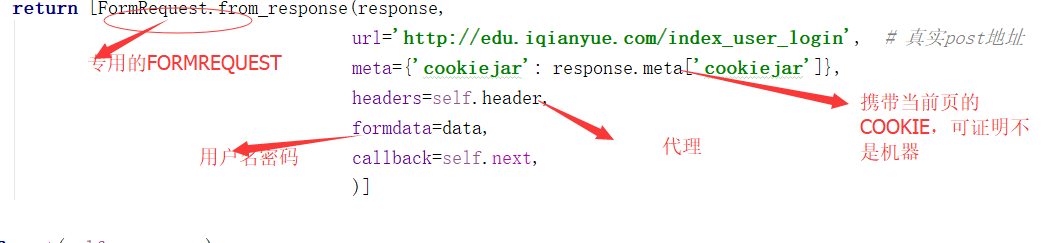
4 meta={'cookiejar':True}表示使用授权后的cookie访问需要登录查看的页面

5 获取请求后的COOKIE,响应COOKIE,然后进行获取个人中心:
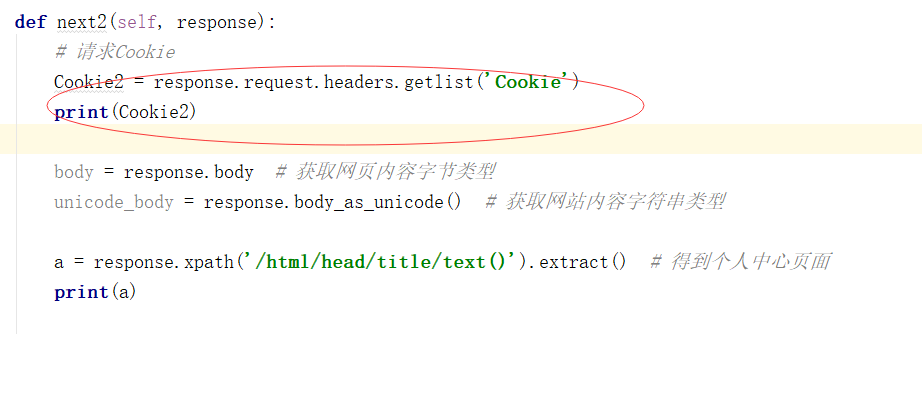
看下结果:
