例题1:有如下值li=[11,22,33,44,55,66,77,88,99,90],将所有大于66的值保存至字典的第一个key中
,将小于66的值保存至字典的第二个key中。即{'k1':大于66的所有值列表,'k2':小于66的所有值列表}
# 方法一
li = [11,22,33,44,55,66,77,88,99,90]
dic = {'k1':[],
'k2':[]
}
for i in li:
if i == 66:continue
if i < 66:
dic['k1'].append(i)
else:
dic['k2'].append(i)
print(dic)
# 方法二
li = [11,22,33,44,55,66,77,88,99,90]
dic = {}
li_greater = []
li_less = []
for i in li:
if i == 66:
continue
if i < 66:
li_less.append(i)
else:
li_greater.append(i)
dic.setdefault('k1',li_greater)
dic.setdefault('k2',li_less)
print(dic)
例题2:输出商品列表,用户输入序号,显示用户选中的商品。
商品 li=['手机','电脑','鼠标垫','键盘']
要求:1:页面显示 序号+商品名称,如:
1.手机
2.电脑
。。。
2:用户输入num_choose = input('请选择商品序号'),然后打印商品名称
3:如果用户输入的商品序号有误,则提示输入有误,并重新输入。
4:用户输入Q或q,推出程序
li=['手机','电脑','鼠标垫','键盘']
for i in li:
print('{} {}'.format(li.index(i)+1,i))
while 1:
sum_choose = input('输入的商品序号/输入R或者r退出')
if sum_choose.isdigit():
sum_choose = int(sum_choose)
if sum_choose > 0 and sum_choose <= len(li):
print(li[sum_choose-1])
else:
print('输入有误,并重新输入')
elif sum_choose.upper() == 'Q':
break
else:
print('请输入数字')
小知识点(了解就行):
# 1.一个=是赋值,两个等号是比较值是否相等;is是比较的意思,比较的是内存地址;id是内存地址的意思
li1 = [1,2,3]
li2 = li1
print(li1 is li2)
print(id(li1),id(li2))
# 2.当数字的范围在-5--256之间时,内存地址时一样的
i1 = 3
i2 = 3
print(id(i1),id(i2))
i3 = 295
i4 = 295
print(id(i3),id(i4)) # 在终端去试
# 3.字符串:1.不能含有特使字符/
# 2.str*20还是同一个地址,s*21以后都是两个地址
i5 = 'find'
i6 = 'find'
print(id(i5),id(i6))
i7 = '@fing'
i8 = '@fing'
print(id(i7),id(i8)) # 在终端去试
i9 = 'a'*20
i10 = 'a'*20
print(i9 is i10)
i9 = 'a'*21
i10 = 'a'*21
print(i9 is i10) # 在终端试
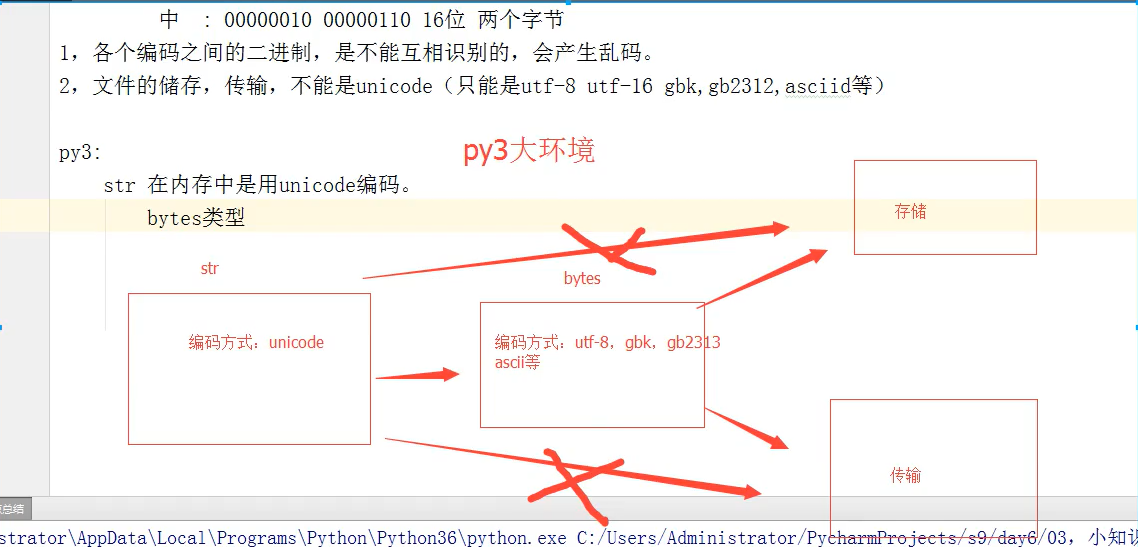
编码问题:
1.各个编码之间的二进制,是不能互相识别的,会产生乱码
2.文件的储存和传输不能是unicode(只能是utf-8,utf-16,gbk,gb2312,ascii等)
python3:
str在内存中是用unicode编码
bytes类型
对于英文:
str : 表现形式:s='alex'
编码方式: 00100101 unicode
bytes : 表现形式:s=b'alex'
编码方式:00100101 utf-8,jbk...
对于中文:
str : 表现形式:s='中国'
编码方式: 00100101 unicode
bytes : 表现形式:s=b'xe4xb8xadxe5x9bxbd'
编码方式:00100101 utf-8,jbk...
# encode:编码,如何将str --> bytes,可以设置编码方式
s1 = 'alex'
s1_1 = s1.encode('utf-8')
print(s1_1)
s2 = '中国'
s2_2 = s2.encode('utf-8')
print(s2_2)