锁升级(Lock Escalations)非常非常不好,因为最后你会是在表级别有排它或共享锁。在表级别放上这样的限制锁会降低你的并发和数据库的吞吐量。
今天我不想讨论锁升级的基本信息,今天我想详细谈下当锁升级触发时,SQL Server的这种锁行为对执行计划情况的影响。
筛选器(Filter)运算符——你的敌人!
假设我们有如下非常简单的查询:
1 SELECT * FROM Sales.SalesOrderDetail 2 WHERE ModifiedDate > '20200501' 3 GO
如你所见,我就从Sales.SalesOrderDetail表请求ModifiedDate晚于2020年5月1日的记录。当然,这个查询不会返回任何记录,因为选择的日期是将来的。
但当你查看执行计划时,你会看到查询优化器选择了完整的聚集索引扫描运算符,紧接着是筛选运算符。
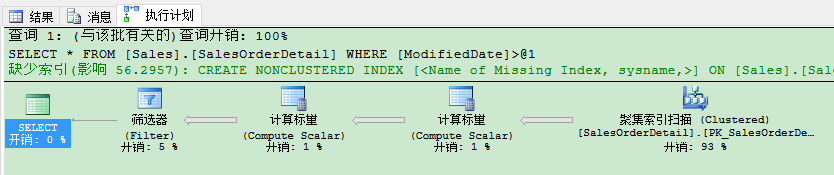
在执行计划里,一个完整的聚集索引扫描运算符,紧接着是一个筛选器运算符真的是一个不好的模式。它意味着一开始(在扫描运算符),你就读取大量的数据,接下来(在筛选器运算符)你剔除不符合的数据。物理上你读取的记录数比你逻辑请求的数多很多。在这个例子里,我从Sales.SalesOrderDetail表读取了121317条记录,但没有1条记录符合我的查询谓语(基于ModifiedDate列)。因此所有列在筛选器运算符被剔除。
现在假设你在像可重复读(Repeatable Read)这样更多限制的事务隔离级别运行这个查询。在这个情况下,SQL Server必须把持共享锁直到事务结束。也就是说,当你读取超过5000条记录时,在聚集索引扫描期间,SQL Server会触发锁升级。这会很糟糕,因为事后读取的不符合的数据会在筛选器剔除。你啥也没做就触发了锁升级。
剩余谓语(Residual Predicate)——你的朋友!
你必须接受筛选器运算符非常不好。但我们可以做的更好么?当然,因为SQL Server也支持所谓的剩余谓语(Residual Predicate):当记录从数据页读取时,这个谓语会“直接”在存储引擎内部评估。当谓语满足时,行是在存储引擎外传入执行计划。如果谓语不满足,行会忽略并消失。在执行计划里,它不会移交给下个运算符。
这个和筛选器运算符完全不同!使用剩余谓语,你只处理在执行计划里逻辑请求的行(你还是要读取请求的数据页……)。当基于剩余谓语没有符合的行时,没有行在执行计划里运输。我们来看下面的查询。
1 SELECT * FROM Person.Person WITH (INDEX(1)) 2 WHERE ModifiedDate > '20200501' 3 GO
这里我从Person.Person表请求行,同样对于选择的查询谓语没有行返回。但这次SQL Server能把查询谓语以剩余谓语的方式压入存储引擎。因此查询谓语在存储引擎里直接评估:
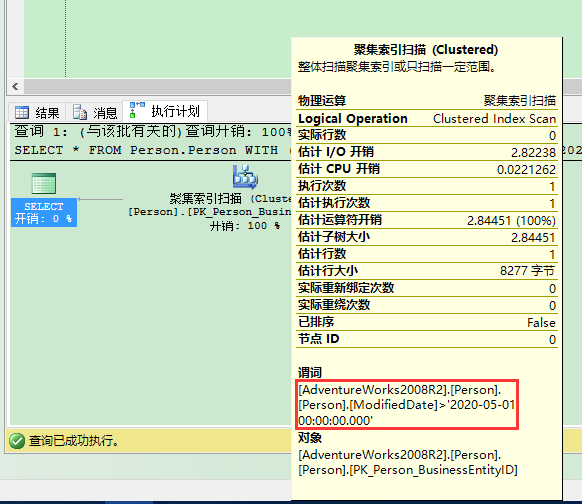
当你在可重复读(Repeatable Read)事务隔离级别里运行这个查询时,你不会再触发锁升级,因为在执行计划里你不处理任何行——在存储引擎里它们就被或略了。因此对于查询,你是否会触发锁升级取决与你的执行计划情况……
小结
如你在这篇文章里所见,执行计划情况会大大影响SQL Server的锁行为。剩余谓语就像帅选器运算符,但它是在存储引擎里,从数据页读取行后,直接评估。它是SQL Server雇佣的性能优化者。
在一些情况下,查询优化器可以把查询谓语作为剩余谓语压入存储引擎,但在一些情况下做不到,查询优化器只能引入筛选器运算符。不要问我什么情况是可以的,什么情况是不可以的。这个行为微软也没有文档说明……
感谢关注!
参考文章:
http://www.sqlpassion.at/archive/2016/02/29/lock-escalations-and-execution-plan-shapes/