一、列表
定义列表:通过下标访问列表中的内容,从0开始
>>> name = ["zhang","wang","li","zhao"]
>>> print(name[0],name[2],name[-1],name[-2])
zhang li zhao li
切片


1 >>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"] 2 >>> names[1:4] 3 ['Tenglan', 'Eric', 'Rain'] 4 >>> names[1:-1] 5 ['Tenglan', 'Eric', 'Rain', 'Tom'] 6 >>> names[0:3] 7 ['Alex', 'Tenglan', 'Eric'] 8 >>> names[:3] 9 ['Alex', 'Tenglan', 'Eric'] 10 >>> names[3:-1] 11 ['Rain', 'Tom'] 12 >>> names[3:] 13 ['Rain', 'Tom', 'Amy'] 14 >>> names[0::2] 15 ['Alex', 'Eric', 'Tom'] 16 >>> names[::2] 17 ['Alex', 'Eric', 'Tom']
追加
1 >>> names 2 ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy'] 3 >>> names.append("New_user") 4 >>> names 5 ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', 'New_user']
插入
1 >>> names 2 ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', 'New_user'] 3 >>> names.insert(2,'Insert_newuser') 4 >>> names 5 ['Alex', 'Tenglan', 'Insert_newuser', 'Eric', 'Rain', 'Tom', 'Amy', 'New_user']
修改
1 >>> names 2 ['Alex', 'Tenglan', 'Insert_newuser', 'Eric', 'Rain', 'Tom', 'Amy', 'New_user'] 3 >>> names[1] = "Modify" 4 >>> names 5 ['Alex', 'Modify', 'Insert_newuser', 'Eric', 'Rain', 'Tom', 'Amy', 'New_user']
删除
1 >>> names 2 ['Alex', 'Modify', 'Insert_newuser', 'Eric', 'Rain', 'Tom', 'Amy', 'New_user'] 3 4 >>> del names[1] #下标删除 5 >>> names 6 ['Alex', 'Insert_newuser', 'Eric', 'Rain', 'Tom', 'Amy', 'New_user'] 7 8 >>> names.remove('Eric') #删除指定元素 9 >>> names 10 ['Alex', 'Insert_newuser', 'Rain', 'Tom', 'Amy', 'New_user'] 11 12 >>> names.pop() #删除列表最后一个值 13 'New_user' 14 >>> names 15 ['Alex', 'Insert_newuser', 'Rain', 'Tom', 'Amy']
扩展
1 >>> names 2 ['Alex', 'Insert_newuser', 'Rain', 'Tom', 'Amy'] 3 >>> b = [1,2,3] 4 >>> names.extend(b) 5 >>> names 6 ['Alex', 'Insert_newuser', 'Rain', 'Tom', 'Amy', 1, 2, 3]
统计
1 >>> names = [2,3,1,4,2,2] 2 >>> names.count(2) 3 3
排序&翻转&清空
1 >>> names = ['Alex', 'Insert_newuser', 'Rain', 'Tom', 'Amy', 1, 2, 3] 2 >>> names 3 ['Alex', 'Insert_newuser', 'Rain', 'Tom', 'Amy', 1, 2, 3] 4 >>> names.sort() 5 Traceback (most recent call last): 6 File "<stdin>", line 1, in <module> 7 TypeError: '<' not supported between instances of 'int' and 'str' 8 >>> names[-3] = '1' 9 >>> names[-2] = '1' 10 >>> names[-2] = '2' 11 >>> names[-1] = '3' 12 >>> names 13 ['Alex', 'Amy', 'Insert_newuser', 'Rain', 'Tom', '1', '2', '3'] 14 >>> names.sort() 15 >>> names 16 ['1', '2', '3', 'Alex', 'Amy', 'Insert_newuser', 'Rain', 'Tom'] 17 >>> names.reverse() 18 >>> names 19 ['Tom', 'Rain', 'Insert_newuser', 'Amy', 'Alex', '3', '2', '1'] 20 >>> names.clear() 21 >>> names 22 []
获取下标
1 >>> names = ['Alex', 'Insert_newuser', 'Rain', 'Tom', 'Amy', 1, 2, 3] 2 >>> names.index('Rain') 3 2 4 >>>
复制:分为浅复制和深复制
浅copy:
s = [[1,2],3,4]
s1 = s.copy()
s1[1] = 'oliver'
s1[0][1] = 'hello'
print('列表s:',s)
print('列表s1:',s1)
执行结果:
列表s: [[1, 'hello'], 3, 4]
列表s1: [[1, 'hello'], 'oliver', 4]
如下图所示,使用列表内置的copy方法,是将新列表中的元素指向了与原列表相同的内存空间。但是,如果列表中嵌套了列表,拷贝后的列表中嵌套的列表元素指针,指向原列表中嵌套列表的整体地址,而不是指向嵌套列表中元素的内存地址。
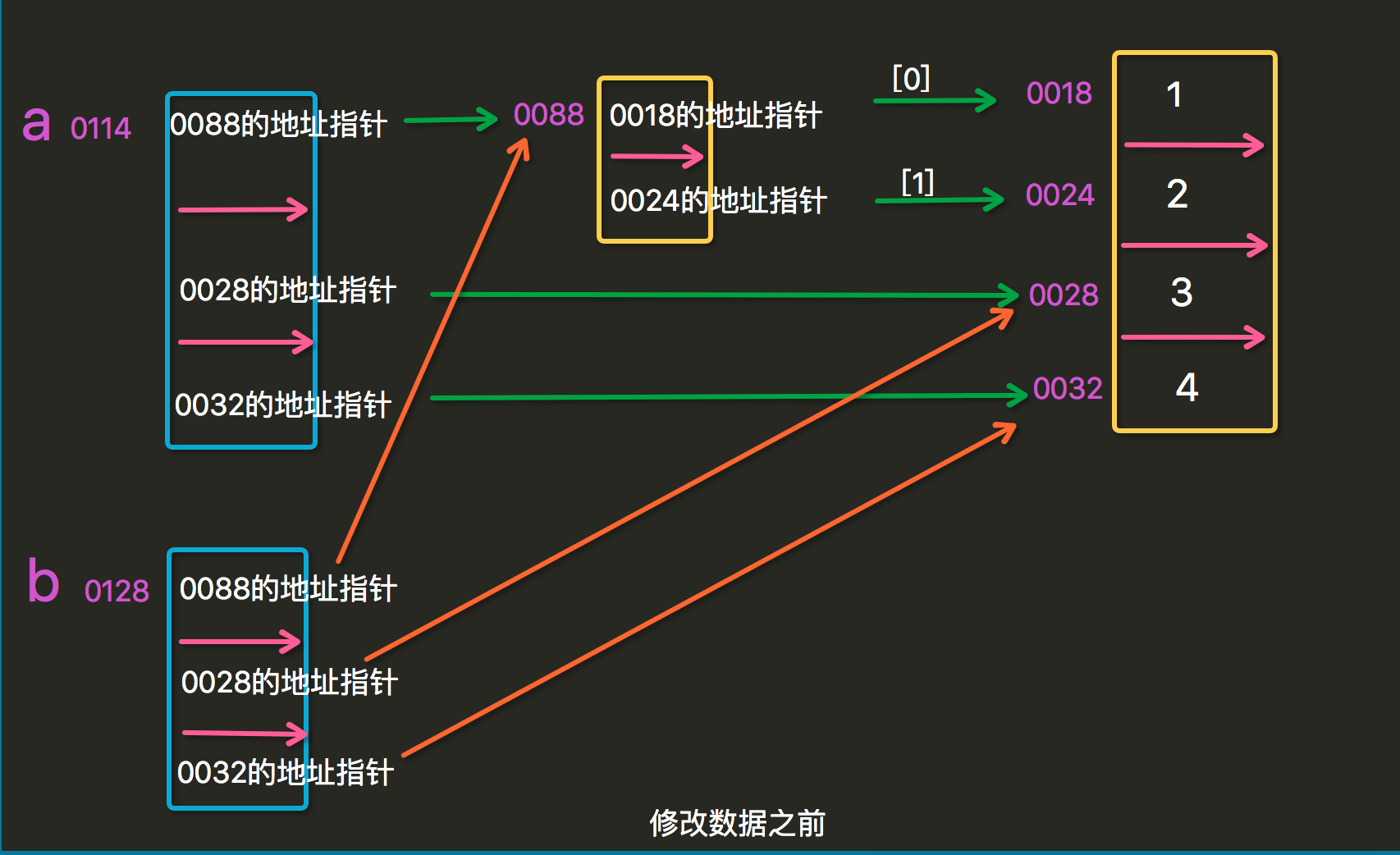

深copy:
1 import copy 2 s = [[1,2],3,4] 3 s2 = copy.deepcopy(s) 4 s2[0][1] = 'abc' 5 print('列表s:',s) 6 print('列表s2',s2)
执行结果:
列表s: [[1, 2], 3, 4]
列表s2 [[1, 'abc'], 3, 4]
总结:
1、浅拷贝只能拷贝最外层,修改内层则原列表和新列表都会变化。
2、深拷贝是指将原列表完全克隆一份新的。
二、字符串
特性:不可修改
>>> name = "my name is alex"
>>> print(name.capitalize()) #首字母大写
My name is alex
>>> print(name.expandtabs()) #首字母小写
my name is alex
>>> print(name.count("a")) #计算'a'的个数
2
>>> print(name.center(50,'-')) #添加-,一共50个字符
-----------------my name is alex------------------
>>> print(name.ljust(50,'*'))
my name is alex***********************************
>>> print(name.rjust(50,'*'))
***********************************my name is alex
>>> print(name.encode())
b'my name is alex'
>>> print(name.endswith('ex')) #判断是否以ex结尾
True


三、字典:key-value的数据类型
字典的特性:
- dict是无序的
- key必须是唯一的,so 天生去重
定义字典:
1 >>> info = { 2 ... 'stu1101':'Tenglan Wu', 3 ... 'stu1102':'Long', 4 ... 'stu1103':'xiaoze' 5 ... } 6 >>> print(info) 7 {'stu1101': 'Tenglan Wu', 'stu1102': 'Long', 'stu1103': 'xiaoze'}
增加:
1 >>> info['stu1104'] = "Cang" 2 >>> info 3 {'stu1101': 'Tenglan Wu', 'stu1102': 'Long', 'stu1103': 'xiaoze', 'stu1104': 'Ca 4 ng'}
删除:
1 #三种删除的方式 2 >>> info.pop('stu1101') #标准删除 3 'Tenglan Wu' 4 >>> info 5 {'stu1102': 'Long', 'stu1103': 'xiaoze', 'stu1104': 'Cang'} 6 >>> del info['stu1102'] #删除具体元素 7 >>> info 8 {'stu1103': 'xiaoze', 'stu1104': 'Cang'} 9 >>> info.popitem() #随机删除 10 ('stu1104', 'Cang') 11 >>> info 12 {'stu1103': 'xiaoze'}
修改:
1 >>> info['stu1103'] = 'oulu' 2 >>> info 3 {'stu1103': 'oulu'} 4 >>>
查询:
1 >>> info = {'stu1101': 'Tenglan Wu', 'stu1102': 'Long', 'stu1103': 'xiaoze'} 2 >>> 'stu1101' in info #标准用法 3 True 4 >>> info.get('stu1102') #获取 5 'Long' 6 >>> info['stu1102'] #同上 7 'Long' 8 >>> info['stu1106'] #如果元素不存在,则报错;而get却不会 9 Traceback (most recent call last): 10 File "<stdin>", line 1, in <module> 11 KeyError: 'stu1106'
多级字典嵌套及操作:
1 av_catalog = { 2 "欧美":{ 3 "www.youporn.com": ["很多免费的,世界最大的","质量一般"], 4 "www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"], 5 "letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"], 6 "x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"] 7 }, 8 "日韩":{ 9 "tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"] 10 }, 11 "大陆":{ 12 "1024":["全部免费,真好,好人一生平安","服务器在国外,慢"] 13 } 14 } 15 16 av_catalog["大陆"]["1024"][1] += ",可以用爬虫爬下来" 17 print(av_catalog["大陆"]["1024"]) 18 执行结果: 19 ['全部免费,真好,好人一生平安', '服务器在国外,慢,可以用爬虫爬下来']
1.打印value:
print(av_catalog.values())
dict_values([{'www.youporn.com': ['很多免费的,世界最大的', '质量一般'], 'www.pornhub.com': ['很多免费的,也很大', '质量比yourporn高点'], 'letmedothistoyou.com': ['多是自拍,高质量图片很多', '资源不多,更新慢'], 'x-art.com': ['质量很高,真的很高', '全部收费,屌比请绕过']}, {'tokyo-hot': ['质量怎样不清楚,个人已经不喜欢日韩范了', '听说是收费的']}, {'1024': ['全部免费,真好,好人一生平安', '服务器在国外,慢,可以用爬虫爬下来']}])
2.#setdefault:如果值存在,就不做任何东西;如果不存在,则创建
av_catalog.setdefault('taiwan',{'www.baidu.com':[1,2]})
print(av_catalog)
{'欧美': {'www.youporn.com': ['很多免费的,世界最大的', '质量一般'], 'www.pornhub.com': ['很多免费的,也很大', '质量比yourporn高点'], 'letmedothistoyou.com': ['多是自拍,高质量图片很多', '资源不多,更新慢'], 'x-art.com': ['质量很高,真的很高', '全部收费,屌比请绕过']}, '日韩': {'tokyo-hot': ['质量怎样不清楚,个人已经不喜欢日韩范了', '听说是收费的']}, '大陆': {'1024': ['全部免费,真好,好人一生平安', '服务器在国外,慢,可以用爬虫爬下来']}, 'taiwan': {'www.baidu.com': [1, 2]}}
3.字典拼接
1 info={ 2 'stu1101':"TengLanWu", 3 'stu1102':"LongZeLuola", 4 'stu1103':"XiaoZeMaliya", 5 } 6 b={ 7 'stu1101':"alex", 8 1:3, 9 2:5, 10 } 11 info.update(b) 12 print(info) 13 执行结果: 14 {'stu1101': 'alex', 'stu1102': 'LongZeLuola', 'stu1103': 'XiaoZeMaliya', 1: 3, 2: 5}
4.字典转换成列表
1 print(info.items()) 2 dict_items([('stu1101', 'alex'), ('stu1102', 'LongZeLuola'), ('stu1103', 'XiaoZeMaliya'), (1, 3), (2, 5)])
5.初始化字典
1 >>> c = dict.fromkeys([6,7,8]) 2 >>> print(c) 3 {6: None, 7: None, 8: None} 4 >>> c = dict.fromkeys('test',[6,7,8]) 5 >>> print(c) 6 {'t': [6, 7, 8], 'e': [6, 7, 8], 's': [6, 7, 8]} 7 >>> c = dict.fromkeys([6,7,8],[1,{'name':'alex'},444]) 8 >>> print(c) 9 {6: [1, {'name': 'alex'}, 444], 7: [1, {'name': 'alex'}, 444], 8: [1, {'name': ' 10 alex'}, 444]} 11 12 #修改了全部值 13 >>> c[7][1]['name'] = 'JackChen' 14 >>> print(c) 15 {6: [1, {'name': 'JackChen'}, 444], 7: [1, {'name': 'JackChen'}, 444], 8: [1, {' 16 name': 'JackChen'}, 444]}
6.字典循环
1 >>> print(info) 2 {'stu1101': 'Tenglan Wu', 'stu1102': 'Long', 'stu1103': 'xiaoze'} 3 >>> 4 >>> 5 >>> 6 >>> for key in info: #建议用 7 ... print(key,info[key]) 8 ... 9 stu1101 Tenglan Wu 10 stu1102 Long 11 stu1103 xiaoze 12 13 >>> for k,v in info.items(): #多了字典转换列表的过程,数据量大时莫用 14 ... print(k,v) 15 ... 16 stu1101 Tenglan Wu 17 stu1102 Long 18 stu1103 xiaoze
四、集合
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
创建集合
1 >>> s = set([3,5,7,9,3,5]) 2 >>> s 3 {9, 3, 5, 7} 4 >>> t = set("hello") 5 >>> t 6 {'l', 'h', 'o', 'e'}
关系型测试:交差并对称集合
1 a = t | s # t 和 s的并集 2 3 b = t & s # t 和 s的交集 4 5 c = t – s # 求差集(项在t中,但不在s中) 6 7 d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中)
1 创建集合: 2 list_1=[1,4,5,6,7,4,9] 3 list_1=set(list_1) 4 list_2=set([2,6,0,66,22,8,4]) 5 print(list_1,list_2) 6 {1, 4, 5, 6, 7, 9} {0, 2, 66, 4, 6, 8, 22} 7 8 #求交集 9 print(list_1.intersection(list_2)) 10 {4, 6} 11 #求并集 12 print(list_1.union(list_2)) 13 {0, 1, 2, 66, 4, 5, 6, 7, 8, 9, 22} 14 #求差集(我有你没有的) 15 print(list_1.difference(list_2)) list_1有的list_2没有的 16 {1, 5, 9, 7} 17 #求子集 18 list_3=set([1,5,9]) 19 print(list_3.issubset(list_1)) 20 True 21 #求父集 22 print(list_1.issuperset(list_3)) 23 True 24 #对称差集:把各自没有的取出来放在一块 25 print(list_1.symmetric_difference(list_2)) 26 {0, 1, 2, 66, 5, 7, 8, 9, 22} 27 28 list_4=set([3,2,8]) 29 print(list_3.isdisjoint(list_4)) 30 True 31 #当两个集合没有交集的时候,返回True 32 33 list2.copy()集合跟列表是一样的,浅copy 34 35 list_1.add(999) 添加 36 list_1.update([888,777,555]) 多项添加 37 print(list_1) 38 {1, 4, 5, 6, 7, 999, 9, 777, 555, 888} 39 40 删除 41 list_1.remove(999) 42 list_1.discard(999) 区别是:删除一个不存在的元素时,remove会报错,discard不会报错 43 list_1.pop() 随机删除 44 45 len(s) 46 set 的长度 47 48 x in s 49 测试 x 是否是 s 的成员 50 51 x not in s 52 测试 x 是否不是 s 的成员 53 54 s.issubset(t) 55 s <= t 56 测试是否 s 中的每一个元素都在 t 中 57 58 s.issuperset(t) 59 s >= t 60 测试是否 t 中的每一个元素都在 s 中 61 62 s.union(t) 63 s | t 64 返回一个新的 set 包含 s 和 t 中的每一个元素 65 66 s.intersection(t) 67 s & t 68 返回一个新的 set 包含 s 和 t 中的公共元素 69 70 s.difference(t) 71 s - t 72 返回一个新的 set 包含 s 中有但是 t 中没有的元素 73 74 s.symmetric_difference(t) 75 s ^ t 76 返回一个新的 set 包含 s 和 t 中不重复的元素 77 78 s.copy() 79 返回 set “s”的一个浅复制