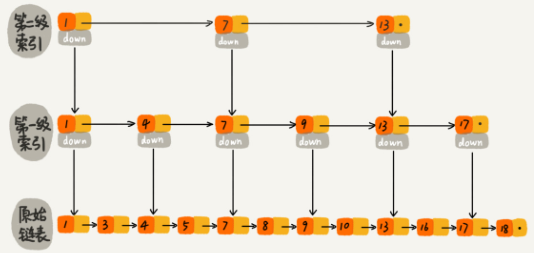
跳表
- 基于链表
- 提取节点,建立多级索引


跳表会否浪费内存
实际的软件开发中,原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引结点大很多时,那索引占用的额外空间就可以忽略了。
高效的动态插入和删除
跳表支持查找,及高效的动态的插入、删除操作,时间复杂度都是 O(logn)
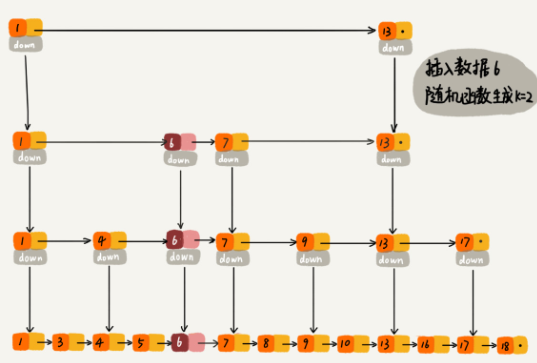
索引动态更新
作为一种动态数据结构,需要某种手段来维护索引与原始链表大小之间的平衡,也就是说,如果链表中结点多了,索引结点就相应地增加一些,避免复杂度退化,以及查找、插入、删除操作性能下降。
- 通过随机函数来维护前面提到的“平衡性”:
通过一个随机函数,来决定将这个结点插入到哪几级索引中,比如随机函数生成了值 K,那我们就将这个结点添加到第一级到第 K 级这 K 级索引中。
随机函数的选择很有讲究,从概率上来讲,能够保证跳表的索引大小和数据大小平衡性,不至于性能过度退化。
之前的总结:https://www.cnblogs.com/wod-Y/p/12021330.html