堆
概念
- 堆是一个完全二叉树;
- 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
- 根据节点值跟子树的大小关系分为:大顶堆和小顶堆。
如何实现
- 如何存储
- 二叉树章节有讲到完全二叉树适合用数组存储,所以用数组来存储堆
- 有哪些操作
- 插入一个元素(O(logn))--插入到数组结尾,执行从下往上堆化:从下往上沿着向堆顶的路径,逐个比较,不满足就交换,满足则结束。
-
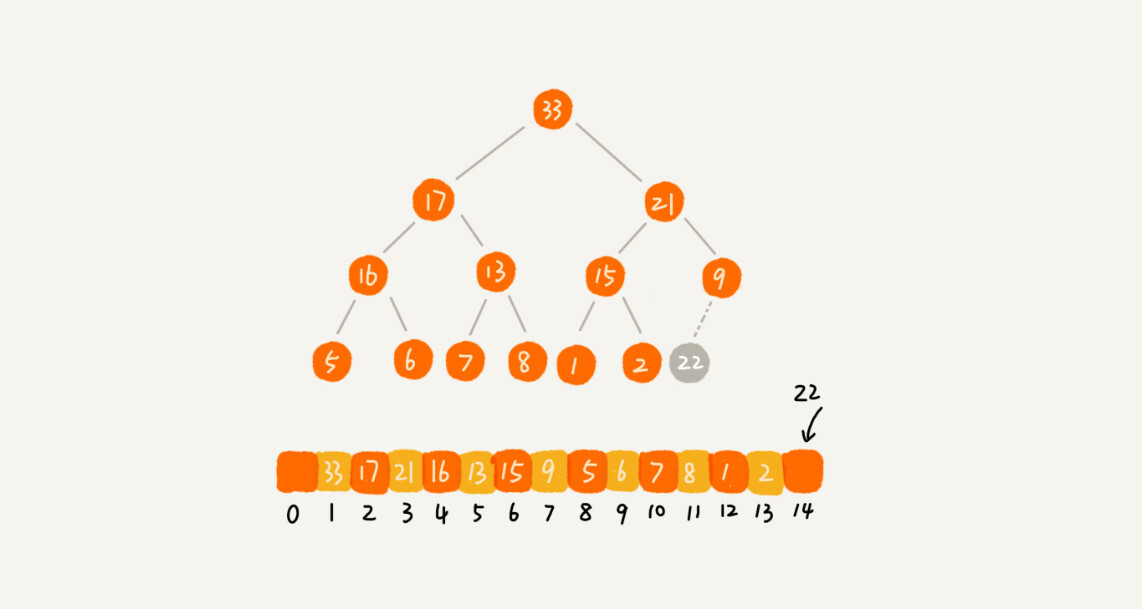
public class Heap { private int[] a; // 数组,从下标1开始存储数据 private int n; // 堆可以存储的最大数据个数 private int count; // 堆中已经存储的数据个数 public Heap(int capacity) { a = new int[capacity + 1]; n = capacity; count = 0; } public void insert(int data) { if (count >= n) return; // 堆满了 ++count; a[count] = data; int i = count; while (i/2 > 0 && a[i] > a[i/2]) { // 自下往上堆化 swap(a, i, i/2); // swap()函数作用:交换下标为i和i/2的两个元素 i = i/2; } } } - 删除堆顶元素(O(logn))--把最后一个节点替换放到堆顶,然后利用同样的父子节点对比方法。对于不满足父子节点大小关系的,互换两个节点,并且重复进行这个过程,直到父子节点之间满足大小关系为止。这就是从上往下的堆化方法。
-
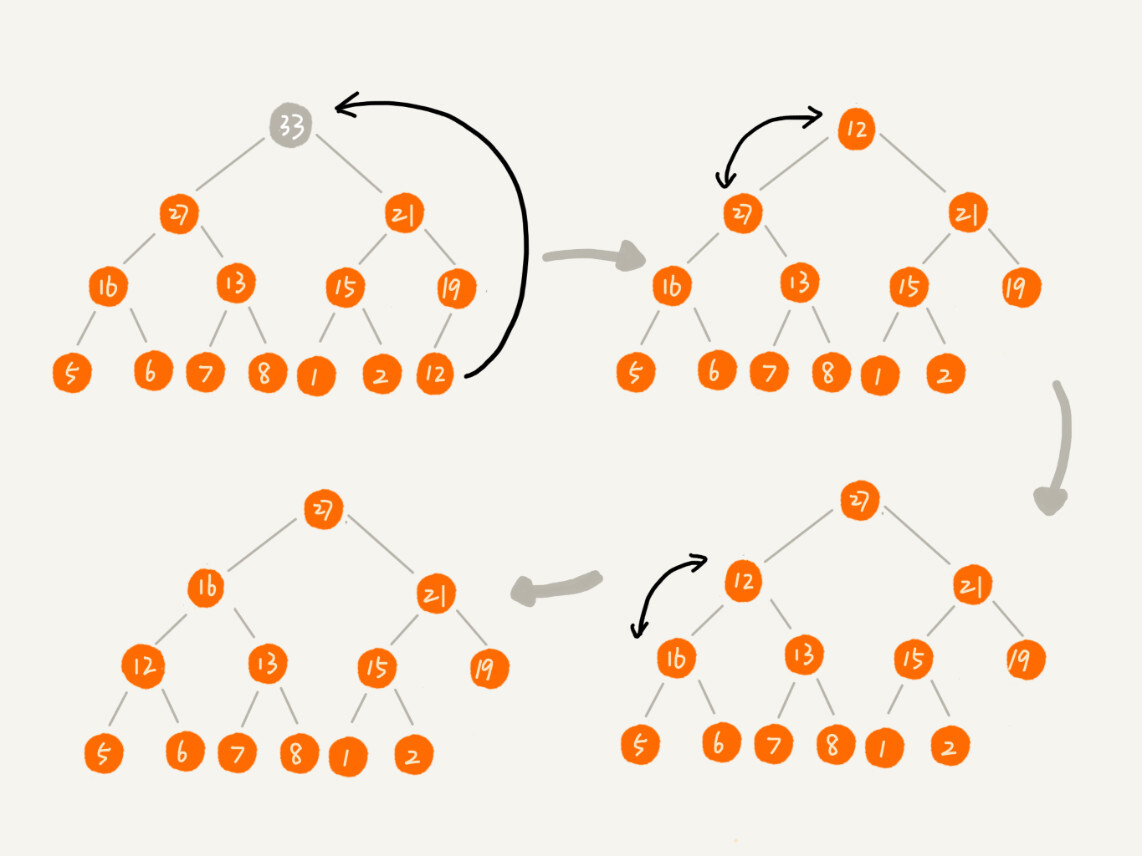
public void removeMax() { if (count == 0) return -1; // 堆中没有数据 a[1] = a[count]; --count; heapify(a, count, 1); } private void heapify(int[] a, int n, int i) { // 自上往下堆化 while (true) { int maxPos = i; if (i*2 <= n && a[i] < a[i*2]) maxPos = i*2; if (i*2+1 <= n && a[maxPos] < a[i*2+1]) maxPos = i*2+1; if (maxPos == i) break; swap(a, i, maxPos); i = maxPos; } }
如何基于堆实现排序?
1. 建堆(时间复杂度就是 O(n))
从后往前处理数组,并且每个数据都是从上往下堆化,从第一个非叶子节点开始,依次堆化,分解图:
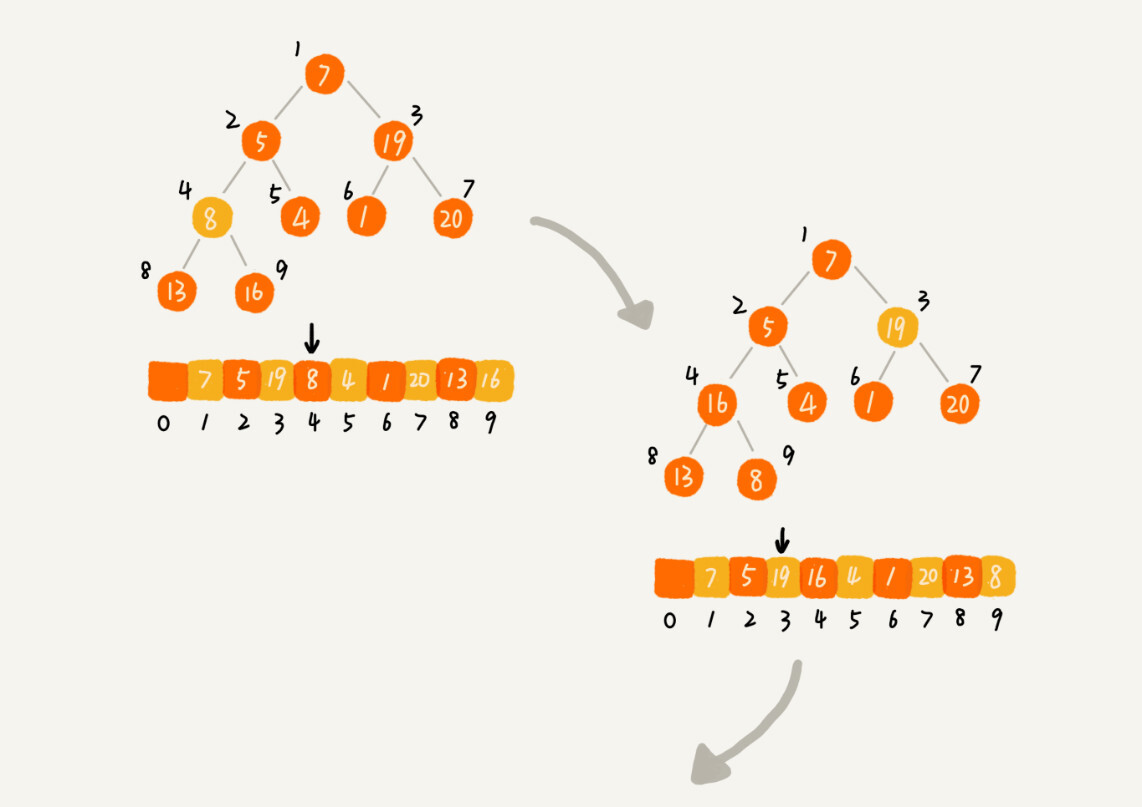
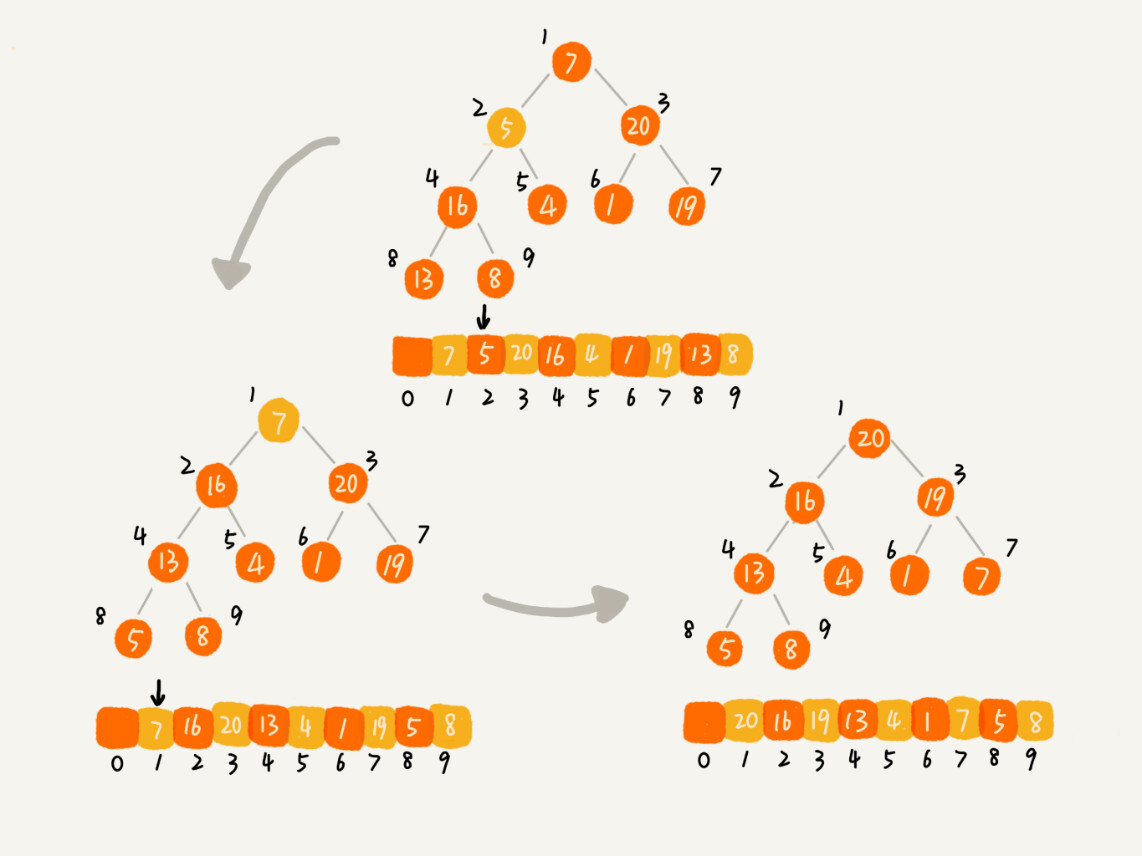
代码:在这段代码中,我们对下标从 2n 开始到 1 的数据进行堆化,下标是 2/n+1 到 n 的节点是叶子节点,我们不需要堆化。实际上,对于完全二叉树来说,下标从 2/n+1 到 n 的节点都是叶子节点。
private static void buildHeap(int[] a, int n) { for (int i = n/2; i >= 1; --i) { heapify(a, n, i); } } private static void heapify(int[] a, int n, int i) { while (true) { int maxPos = i; if (i*2 <= n && a[i] < a[i*2]) maxPos = i*2; if (i*2+1 <= n && a[maxPos] < a[i*2+1]) maxPos = i*2+1; if (maxPos == i) break; swap(a, i, maxPos); i = maxPos; } }
2. 排序
类似删除堆顶元素的操作,从后向前,把当前元素放到堆顶再执行从上至下堆化处理
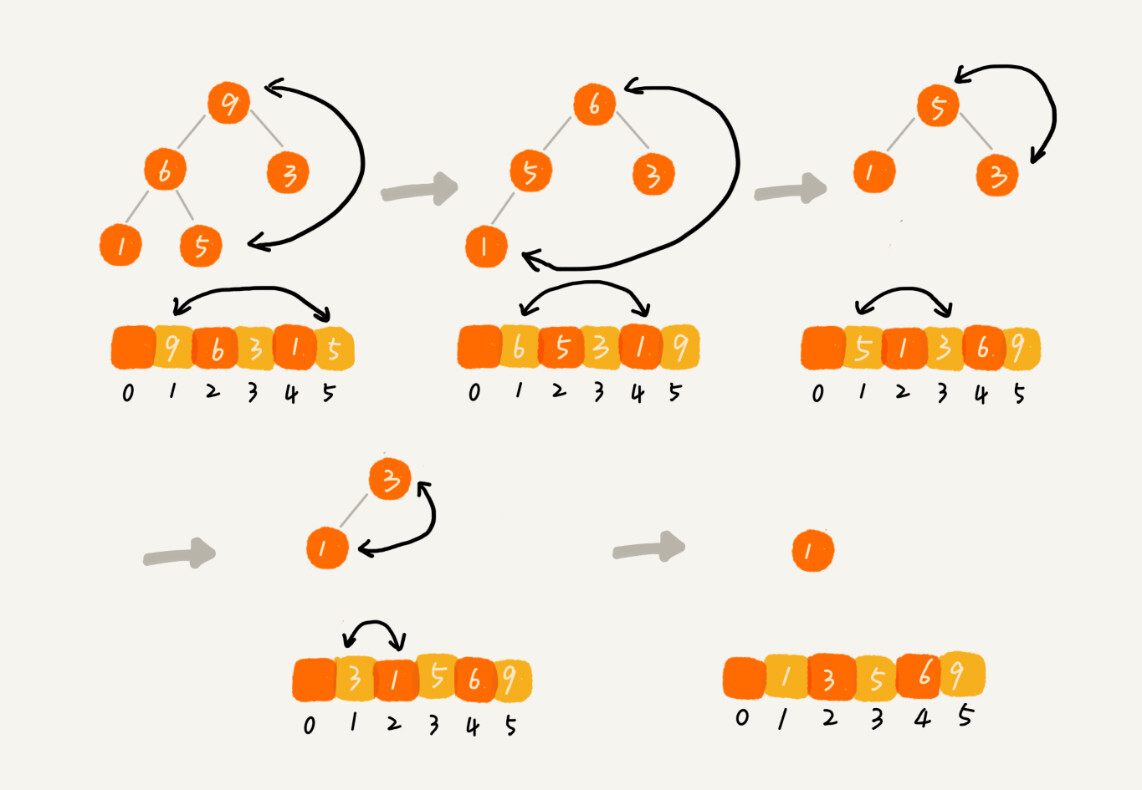
// n表示数据的个数,数组a中的数据从下标1到n的位置。 public static void sort(int[] a, int n) { buildHeap(a, n); int k = n; while (k > 1) { swap(a, 1, k); --k; heapify(a, k, 1); } }
- 排序时间复杂度分析
建堆过程的时间复杂度是 O(n),排序过程的时间复杂度是 O(nlogn),所以,堆排序整体的时间复杂度是 O(nlogn)。
- 稳定性
堆排序不是稳定的排序算法:因为在排序的过程,存在将堆的最后一个节点跟堆顶节点互换的操作,所以就有可能改变值相同数据的原始相对顺序。
为什么快速排序要比堆排序性能好?
- 堆排序数据访问的方式没有快速排序友好:堆化过程,会依次访问数组下标是 1,2,4,8 的元素,而不是像快速排序那样,局部顺序访问,所以,这样对 CPU缓存是不友好的。
- 对于同样的数据,在排序过程中,堆排序算法的数据交换次数要多于快速排序。
堆的应用一:优先级队列
- 合并有序小文件--优先级队列思想:
- 1.取各小文件最小值组成小顶堆
- 2.将堆顶元素插入大文件
- 3.删除堆顶元素,取堆顶元素所在文件中下一个值插入堆
- 4.循环执行步骤2,3,直至堆元素个数为0。
- 高性能定时器
- 多个定时任务,按时间大小组成小顶堆
- 每次执行堆顶任务(也就是最早时间),比每次循环所有任务要效率高( O(logn)<O(n) )
堆的应用二:利用堆求 Top K
- 维护一个大小为 K 的小顶堆,
- 顺序遍历数组,从数组中取出数据与堆顶元素比较。
- 如果比堆顶元素大,我们就把堆顶元素删除,并且将这个元素插入到堆中;
- 如果比堆顶元素小,则不做处理,继续遍历数组。
- 这样等数组中的数据都遍历完之后,堆中的数据就是前 K 大数据了
堆的应用三:利用堆求中位数
- 对于静态数据可先排序,取n/2位置元素,边际成本小。
- 对于动态数据则不适合每次都排序
- 借助堆这种数据结构,我们不用排序,就可以非常高效地实现求中位数操作。我们来看看,它是如何做到的?
- 维护两个堆,一个大顶堆,一个小顶堆。大顶堆中存储前半部分数据,小顶堆中存储后半部分数据,且小顶堆中的数据都大于大顶堆中的数据。
- 新加入的数据小于等于大顶堆的堆顶元素,我们就将这个新数据插入到大顶堆;否则,我们就将这个新数据插入到小顶堆
- 利用两个堆不仅可以快速求出中位数,还可以快速求其他百分位的数据,原理是类似的。