· 掌握定向网络数据爬取和网页解析的基本能力
· The Website is the API… (Application Programming Interface,应用程序编程接口)
- Requests:自动爬取HTML页面,自动网络请求提交
- robots.txt:网络爬虫排除标准
- Beautiful Soup:解析HTML页面
- Projects:实战项目A/B
- Re:正则表达式详解,提取页面关键信息
- Scrapy:网络爬虫原理介绍,专业爬虫框架介绍
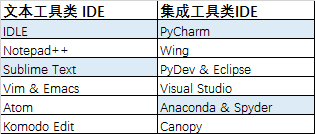
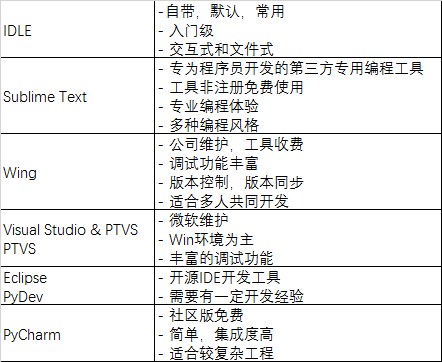
· 常用Python IDE工具
· 科学计算 与 数据分析
