Hadoop是apache用来“处理海量数据存储和海量数据分析”的分布式系统基础架构,更广义的是指hadoop生态圈。
Hadoop的优势
高可靠性:hadoop底层维护多个数据副本,即使某个计算单元故障,也不会导致数据丢失。
高扩展性:天然支持分布式,可方便的扩展至几千个节点。
高容错性:能够自动将失败的任务重新分配。
高效性:在mapReduce的思想下,hadoop是并行工作处理任务的。
Hadoop1.x和Hadoop2.x的区别

MapReduce架构概述
Mapreduce实际上就是将计算过程分类两个阶段:map和reduce
1)map阶段:并行处理计算数据
2)reduce阶段:对map结果进行汇总
HDFS架构概述
1. Name Node(nn) 就像一本书的目录。存储文件的元数据:如文件名,文件目录结构,文件属性(创建时间、副本数、文件权限),以及每个文件的块列表和块所在的dataNode等。
2. Data Node(dn) 就像一本书的详细类容。在本地文件系统存储文件块数据,以及数据的校验。
3. Seconddary Name Node(2nn) 2NN并非是NameNode热备,他的作用是,辅助namenode工作,定期合并镜像文件和编辑日志,紧急情况下恢复NameNode。个人理解就是,2nn帮助namenode完成edits向fsimage的合并工作。
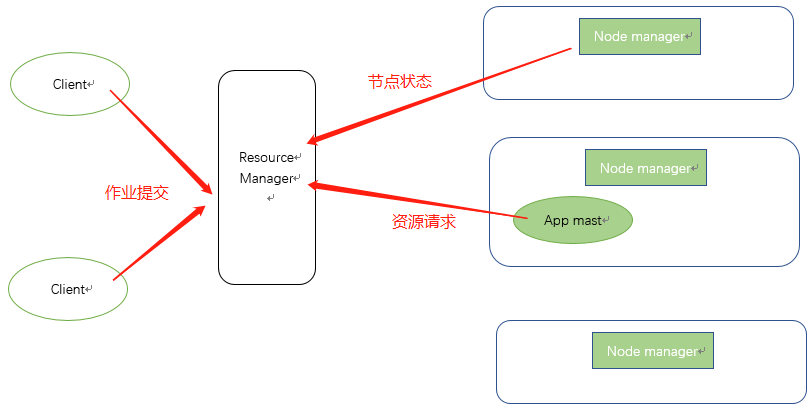
YARN架构概述
Yarn是管理内存调度和cpu资源分配的。
*NodeManager(NM):常驻进程,类似于团队里面的码农,主要作用如下:
1)管理单个节点的资源。(看禅道,完成自己每天的工作安排)
2)处理来自ResourceManager的命令。(完成技术经理分配的任务)
3)处理来自ApplicationMaster的命令。(完成项目组长分配的任务)
*ApplicationMaster(AM):是ResourceManager临时启用的一个节点,不是常驻进程,类似于一个技术小组长:
1)负责数据的切分,任务的监控与容错。(管理组内同事工作)
2)为应用程序申请资源分配给内部任务。(向领导为小组申请资源:人力、时间什么的)
*ResourceManager(RM) :常驻进程,一个集群只有一个,用来管理集群调度情况的,就像一个部门的技术经理一样,其作用如下:
1)处理客户端请求,进行资源分配与调度。(对接产品需求,分给手下的人)
2)监控nodeManager(管理团队成员每天的工作)
3)启动或监控applicationMaster(可能项目太小不想亲自动手,临时任命一个小组长)
*Container:非常驻进程,它是yarn中的资源抽象,他封装了某个节点上的多维度资源,入内存,CPU,磁盘网络等。Am就运行在这里面,Nm通过打开关闭Container开完成资源的调度。