1. Rocketmq消费模型(实时性)
常见的数据同步方式有这几种:
push:producer发送消息后,broker马上把消息投递给consumer。这种方式好在实时性比较高,但是会增加broker的负载;而且消费端能力不同,如果push推送过快,消费端会出现很多问题。
pull:producer发送消息后,broker什么也不做,等着consumer自己来读取。它的优点在于主动权在消费者端,可控性好;但是间隔时间不好设置,间隔太短浪费资源,间隔太长又会消费不及时。
长轮询:当consumer过来请求时,broker会保持当前连接一段时间 默认15s,如果这段时间内有消息到达,则立刻返回给consumer;15s没消息的话则返回空然后重新请求。这种方式的缺点就是服务端要保存consumer状态,客户端过多会一直占用资源。
RocketMQ默认是采用pushConsumer方式消费的,从概念上来说是推送给消费者,它的本质是pull+长轮询。这样既通过长轮询达到了push的实时性,又有了pull的可控性。系统收到消息后会自动处理消息和offset(消息偏移量),如果期间有新的consumer加入会自动做负载均衡(集群模式下offset存在broker中; 广播模式下offset存在consumer里)。当然我们也可以设置为pullConsumer模式,这样灵活性会提高,但是代码却会很复杂,需要手动维护offset,消息存储和状态。
* offset:简单粗暴的理解就是数组下标。message queue是无限长的数组,每次消息进来就会涨1,下标就是offset。consumer可以通过指定offse位置开始读取数据。queue的maxOffset是消息的最大offset,不是最新消息的offset 而是最新消息的offset+1,minOffset则是现存的最小offset。
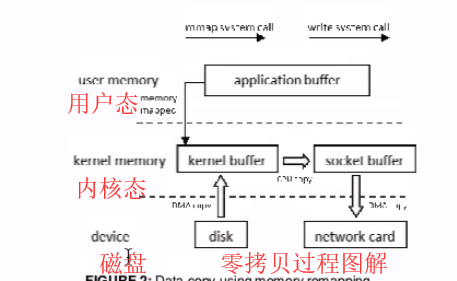
2. Rocketmq消息存储(顺序写,随机读)
消息存储是由ConsumeQueue和CommitLog配合完成的。一个Topic里面有多个MessageQueue,每个MessageQueue对应一个ConsumeQueue.
默认地址:store/consumequeue/{topicName}/{queueid}/fileName
ConsumeQueue里记录着消息物理存储地址。(读:consumer根据消息的consumeQueue找到消息存储具体路径,从而读取里面信息)
CommitLog就存储文件具体的字节信息。(写:文件大小默认1g,文件名称20位数 左边补0右边为偏移量。消息顺序写入文件,文件满了则写入下一个文件)
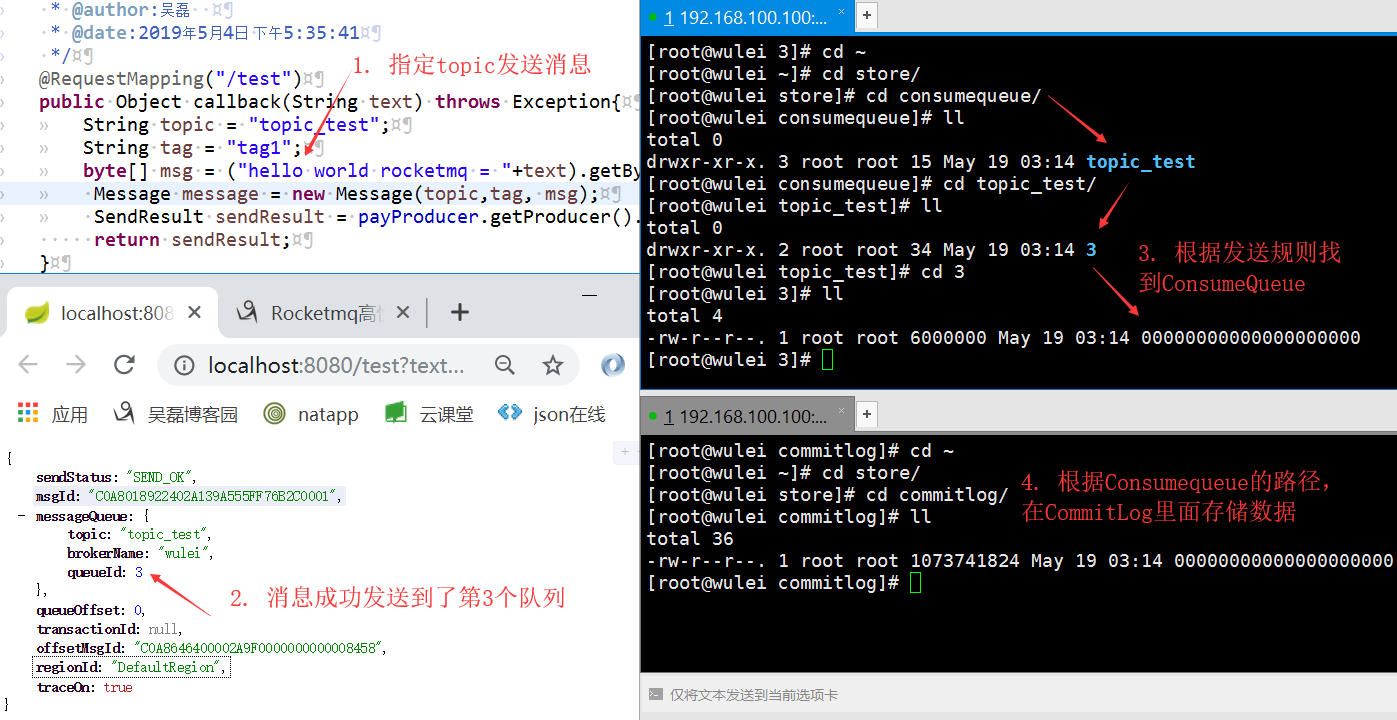
3. ZeroCopy高性能零拷贝
linux有两个上下文(内核态、用户态), 传统的将一个file读取并发送出去会经历4个过程。
read时:
1. 将文件从磁盘copy到kernel(内核)态
2. cpu将kernrl态的数据copy到user(用户)态
write时:
3. user态的内容会copy到kernel态的socket的buffer中
4. 将kernel中buffer的数据copy到网卡中传送
我们可以发现2、3完全是多余的步骤,而且上下文之间的切换是很耗性能的。
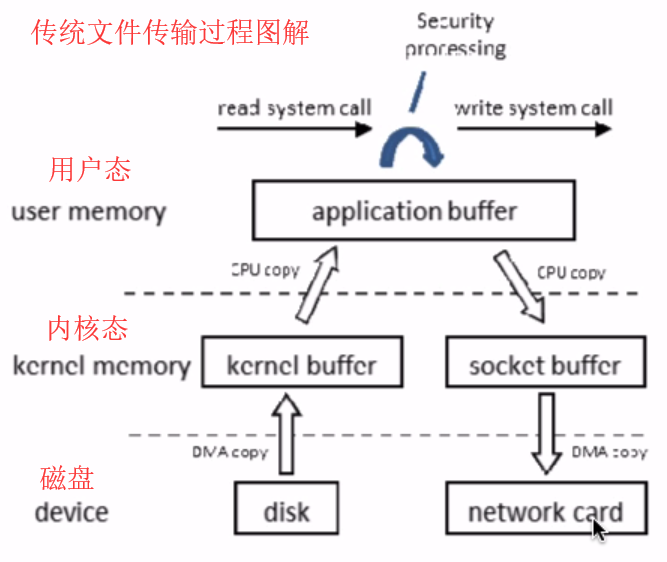
ZeroCopy:内核直接把磁盘的数据传输到socket,而不是通过应用程序去传输。减少了不必要的内核缓冲区和用户缓冲区间的拷贝,从而提升了性能。
零拷贝技术有mmap及sendfile;sendfile大文件传输快,mmap小文件传输快。MMQ发送的消息通常都很小,rocketmq就是以mmap+write方式实现的。像kafka、netty都采用了零拷贝技术。