题目:https://leetcode-cn.com/problems/intersection-of-two-arrays/
想法:使用“unordered_set”来处理数组
代码:
C++版本: vector<int> intersection(vector<int>& nums1, vector<int>& nums2) { unordered_set<int> s1(nums1.begin(), nums1.end());//不存在重复数据 unordered_set<int> s2; for (auto it = nums2.begin(); it != nums2.end(); it++){ if (s1.find(*it) != s1.end()) s2.insert(*it); } vector<int> result; result.assign(s2.begin(), s2.end()); return result; }
知识点
1、常见的三种哈希结构:https://programmercarl.com/%E5%93%88%E5%B8%8C%E8%A1%A8%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%80.html#%E5%93%88%E5%B8%8C%E5%87%BD%E6%95%B0

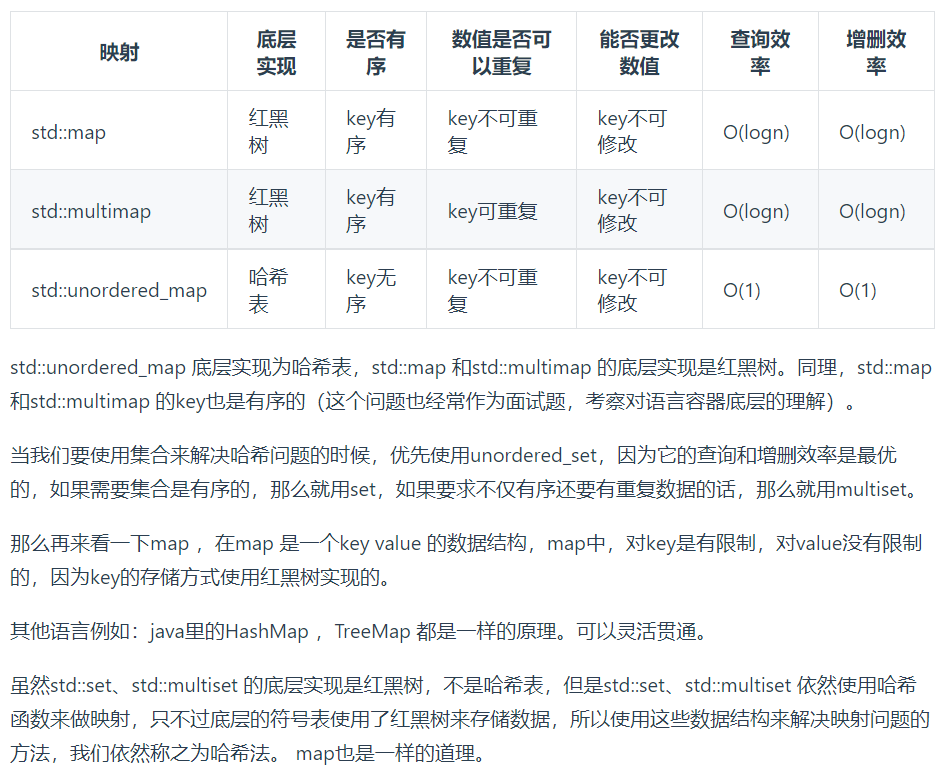
2、 C++11哈希集合set与向量vector的互转:https://blog.csdn.net/SL_World/article/details/114664645
3、C++ STL 之 unordered_set 使用(包括unordersd_map):https://blog.csdn.net/qq_32172673/article/details/85160180
官方解法:https://leetcode-cn.com/problems/intersection-of-two-arrays/solution/liang-ge-shu-zu-de-jiao-ji-by-leetcode-solution/
方法一:两个集合
计算两个数组的交集,直观的方法是遍历数组 nums1,对于其中的每个元素,遍历数组 nums2 判断该元素是否在数组 nums2 中,如果存在,则将该元素添加到返回值。假设数组 nums1 和 nums2 的长度分别是 m 和 n,则遍历数组 nums1 需要 O(m) 的时间,判断 nums1 中的每个元素是否在数组 nums2 中需要 O(n) 的时间,因此总时间复杂度是 O(mn)。
如果使用哈希集合存储元素,则可以在 O(1) 的时间内判断一个元素是否在集合中,从而降低时间复杂度。
首先使用两个集合分别存储两个数组中的元素,然后遍历较小的集合,判断其中的每个元素是否在另一个集合中,如果元素也在另一个集合中,则将该元素添加到返回值。该方法的时间复杂度可以降低到 O(m+n)。
C++版本: vector<int> getIntersection(unordered_set<int>& set1, unordered_set<int>& set2) { if (set1.size() > set2.size()) { return getIntersection(set2, set1); } vector<int> intersection; for (auto& num : set1) { if (set2.count(num)) {//如果set2中有num,返回1;否则返回0;set1和set2都不含重复的元素 intersection.push_back(num); } } return intersection; } vector<int> intersection(vector<int>& nums1, vector<int>& nums2) { unordered_set<int> set1, set2; for (auto& num : nums1) { set1.insert(num); } for (auto& num : nums2) { set2.insert(num); } return getIntersection(set1, set2); }
时间复杂度:O(m+n),其中 m 和 n 分别是两个数组的长度。使用两个集合分别存储两个数组中的元素需要O(m+n) 的时间,遍历较小的集合并判断元素是否在另一个集合中需要 O(min(m,n)) 的时间,因此总时间复杂度是 O(m+n)。
空间复杂度:O(m+n),其中 m 和 n 分别是两个数组的长度。空间复杂度主要取决于两个集合。
方法二:排序 + 双指针
如果两个数组是有序的,则可以使用双指针的方法得到两个数组的交集。
首先对两个数组进行排序,然后使用两个指针遍历两个数组。可以预见的是加入答案的数组的元素一定是递增的,为了保证加入元素的唯一性,我们需要额外记录变量 pre 表示上一次加入答案数组的元素。
初始时,两个指针分别指向两个数组的头部。每次比较两个指针指向的两个数组中的数字,如果两个数字不相等,则将指向较小数字的指针右移一位,如果两个数字相等,且该数字不等于 pre ,将该数字添加到答案并更新 pre 变量,同时将两个指针都右移一位。当至少有一个指针超出数组范围时,遍历结束。
C++版本: vector<int> intersection2(vector<int>& nums1, vector<int>& nums2) { sort(nums1.begin(), nums1.end()); sort(nums2.begin(), nums2.end()); int length1 = nums1.size(), length2 = nums2.size(); int index1 = 0, index2 = 0; vector<int> intersection; while (index1 < length1 && index2 < length2) { int num1 = nums1[index1], num2 = nums2[index2]; if (num1 == num2) { // 保证加入元素的唯一性 if (!intersection.size() || num1 != intersection.back()) { intersection.push_back(num1); } index1++; index2++; } else if (num1 < num2) { index1++; } else { index2++; } } return intersection; }
时间复杂度:O(mlogm+nlogn),其中 m 和 n 分别是两个数组的长度。对两个数组排序的时间复杂度分别是 O(mlogm) 和 O(nlogn),双指针寻找交集元素的时间复杂度是 O(m+n),因此总时间复杂度是 O(mlogm+nlogn)。
空间复杂度:O(logm+logn),其中 m 和 n 分别是两个数组的长度。空间复杂度主要取决于排序使用的额外空间。
代码随想录:https://programmercarl.com/0349.%E4%B8%A4%E4%B8%AA%E6%95%B0%E7%BB%84%E7%9A%84%E4%BA%A4%E9%9B%86.html#_349-%E4%B8%A4%E4%B8%AA%E6%95%B0%E7%BB%84%E7%9A%84%E4%BA%A4%E9%9B%86
思路:
这道题目,主要要学会使用一种哈希数据结构:unordered_set,这个数据结构可以解决很多类似的问题。
注意题目特意说明:输出结果中的每个元素一定是唯一的,也就是说输出的结果的去重的, 同时可以不考虑输出结果的顺序
这道题用暴力的解法时间复杂度是O(n^2),那来看看使用哈希法进一步优化。
那么用数组来做哈希表也是不错的选择,例如242. 有效的字母异位词(opens new window)
但是要注意,使用数组来做哈希的题目,是因为题目都限制了数值的大小。
而这道题目没有限制数值的大小,就无法使用数组来做哈希表了。
而且如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费。
此时就要使用另一种结构体了,set ,关于set,C++ 给提供了如下三种可用的数据结构:
- std::set
- std::multiset
- std::unordered_set
std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希表, 使用unordered_set 读写效率是最高的,并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。
思路如图所示:
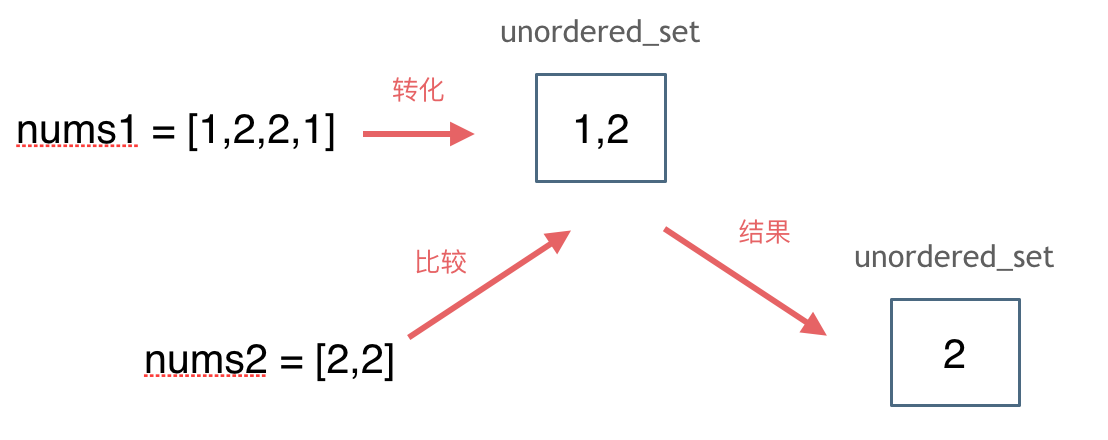
C++版本: vector<int> intersection(vector<int>& nums1, vector<int>& nums2) { unordered_set<int> result_set; // 存放结果 unordered_set<int> nums_set(nums1.begin(), nums1.end()); for (int num : nums2) { // 发现nums2的元素 在nums_set里又出现过 if (nums_set.find(num) != nums_set.end()) { result_set.insert(num); } } return vector<int>(result_set.begin(), result_set.end()); }
拓展:
那有同学可能问了,遇到哈希问题我直接都用set不就得了,用什么数组啊。
直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的。
不要小瞧 这个耗时,在数据量大的情况,差距是很明显的。