一 、子查询
1、定义:子查询是 嵌套 在其他查询中的查询,子查询可以用在select查询语句的任何地方/
2、下面是子查询的两种应用方式
(1)在where 子句中 ,配合in ,not in 操作符 ,进行过滤
(2)作为计算字段使用子查询,在select字句中
作为计算字段时,子查询是与外部查询相关的,子查询要使用完全限定名, 需要重点关注子查询的执行次数(与外部表的查询检索出的数据 个数 相关)
举例:把左边的表count_1 变成右边的表
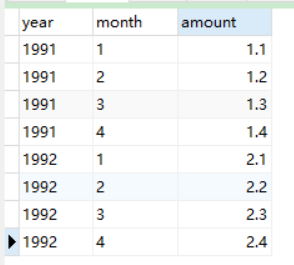

1 select year, 2 (select amount from count_1 a where month = 1 and a.year = b.year) m1, 3 (select amount from count_1 a where month = 2 and a.year = b.year) m2, 4 (select amount from count_1 a where month = 3 and a.year = b.year) m3, 5 (select amount from count_1 a where month = 4 and a.year = b.year) m4 6 from count_1 b 7 group by year (注:此语句也可以不写,而是在select 语句中 加 distinct关键字 ,即select distinct year ......)
第二种方法
1 select year,
2 sum(case when month=1 then amount else 0 end) m1,
3 sum(case when month=2 then amount else 0 end) m2,
4 sum(case when month=3 then amount else 0 end) m3,
5 sum(case when month=4 then amount else 0 end) m4
6 from count_1 b
7 group by year
3、用子查询建立和测试查询技巧—逐渐增加子查询
一般步骤:
(1)建立和测试最内层的查询
(2)用 硬编码数据 建立和测试外部结构
二 、 联结(join)
1、定义:表a 与 表b 联结,即是将 表a的每一行 与 表b 的每一行 配对,当没有联结条件时,返回笛卡尔积
在where字句中 建立 联结条件,以在运行时构造相应的关系(临时表),应该保证所有的联结都有where子句
2、on 和 where 的区别
on 作用于连接过程中,以外连接为例,会返回想要的所有内容,不符合连接条件的会被赋予空值
where 作用于连接之后生成的续表,不符合过滤条件的全部过滤掉
3、表 可以用 as关键字 取 别名,但是表别名 只在查询执行的过程中使用,不返回客户端(即不会显示在结果中)
4、4种不同联结
(1)等值连接
在where子句中 添加 等值条件
等值连接的联结条件:
如果是两张表的主、外键(主键 的所有值是不重复的),可以直接将两个表的相关信息连接到一起,连接的结果真实,可以直接使用
如果是其他的非主、外键的列,则连接的结果往往可能出现异常的,不符合实际的情况,或者存在大量重复的信息,往往还需要在where子句中 添加其他过滤条件
(2)自连接
在单条查询语句中 多次 使用 同一张表
(3)外连接
left ourer join 左外连接
right outer join 右外连接
outer oin 全外连接
三 、组合查询(union)
1、定义:union 将多条select查询语句组成一个整体,并指示mysql 执行每个select语句,将所有输出合成单个结果集
2、需要组合查询的两种基本情况
(1)在单个查询中从不同的表返回类似结构的数据
(2)对单个表执行多个查询,按单个查询返回数据
3、union规则
(1)按照一列,每两个select 语句间用 union连接
(2)每个查询包含相同的列、表达式和聚集函数(顺序可不同)
(3)列数据类型必须兼容,列数据类型不必完全相同,但必须保证DBMS可以隐含的转换为相同
(4)union 自动去除重复的结果,如何不需要去重,可以使用union all
4、排序
一个组合查询只能有一个 order by 子句,位于最后一个selece语句的后面,
四、更新表 update
1、可以更新某个记录的某个列的值、或者多列值;也可以更新多个记录
update tablename
set
where
set 子句 可以使用子查询
2、重命名
alter tablename
rename newname
五 、 视图
1、定义:一个虚拟的表,不包含数据,只包含一个查询,在使用时 动态的检索数据
优点: (1)极大的减化了复杂的查询
(2)一次性编写基础的sql ,多次使用
2、视图的创建和删除
创建视图
create view 视图名称 as 查询语句
删除视图
drop view 视图名称
更新视图
create or replace view 视图名称
3、更新视图
由于视图本身并不保存数据,视图的更新,其实是对基表的操作。并非所有的视图都是可更新的,在分组、联结、子查询、并、聚集函数、distinct,导出计算列等情况下不能更新视图
3、其他
(1)如果从视图检索数据时使用了一条where子句,那么这条where子句将自动和视图本身的where子句组合在一起
六、存储过程
1、定义:为了以后使用,而保存的一条或多天 mysql语句的集合。 可视为——批文件(跑批)
2、优点
(1)简化操作
(2)方便统一管理(可使应用程序、程序员都使用标准的操作),防止错误
(3)简化对变动的管理,存储过程的内容对使用人员可以是黑箱,当底层变化时,仅需要改动存储过程即可,不影响使用者的使用
(4)提高性能
缺点:
(1)编写复杂
(2)需要更严格 的管理,普通人员只有使用权限;mydql将编写 和 使用 区分开了
3、调用存储过程
(1)调用语句
call 存储过程的名称( a,
@b
);
注:a为需要传入的值,b 为存储输出结果的变量,mysql中变量都必须以@开始;
调用过程类似函数需要传入实参的过程,只不过存储过程还需要传入接收结果的变量
(2)查询返回的结果: 直接select查询接收结果的变量
select @b;
4、创建存储过程(本质上:存储过程是 一种函数 ,可以接收参数,函数体用begin ...end 包围)
(1)创建语句
create procedure 存储过程名称(
in/out/inout 变量名 变量类型,
)
begin
mysql语句
end;
注意事项:在命令行中创建存储过程时,由于过程体内的语句会用到语句分隔符‘ ;’ ,使得存储过程无法编写成功。所以,在编写之前要改变语句分隔符,如下
delimiter // 将语句分隔符改为 //
定义存储过程
delimiter ; 将语句分隔符改回 ;
(2)其他规定
-- :过程体内行注释
comment '注释内容':紧跟参数列表之后,为整个存储过程添加注释
5、存储过程参数
(1)参数变量类型
传入参数:in
传出参数:out
传入传出参数 :inout
将检索值存入传出变量 : into 传出变量(参数)
6、删除存储过程
drop procedure if exists 存储过程名称;
7、检查存储过程
show create procedure 存储过程名称;