在R中,我们通常需要对数据列进行各种各样的操作,比如选取某一列、重命名某一列等。
dplyr中的select函数子在数据列的操作上也同样表现了它的简洁性,而且各种操作眼花缭乱。
select(.data, ...)
参数主要在于如何添加条件。配合select()进行使用的函数有:
starts_with()
ends_with()
contains()
matches()
num_range()
one_of()
everything()
配合以上这些函数,使得select()的使用更加的灵活。
除了选择列以外,我们还可以添加一列,使用函数mutate()或transmute()
mutate(.data, ...)
transmute(.data, ...)
下面来看些具体的例子
library(dplyr)
x<-data.frame(id=1:6,
name=c("wang","zhang","li","chen","zhao","song"),
shuxue=c(89,85,68,79,96,53),
yuwen=c(77,68,86,87,92,63),
shengwu=c(85,68,78,68,98,96))
x
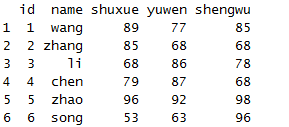
select(x,name)

选取单列
select(x,starts_with("s"))
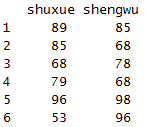
选取包好以“s”开头的列
select(x,ends_with("e"))
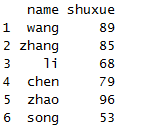
选取以“e”结尾的列。
select(x,matches(".e."))

匹配中间含有“e”的列
select(x,contains("e"))

匹配所有名称中包含“e”的列
select(x,-name)
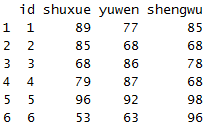
在名字前面加个“-”,表示出了这一列以外,其他的列都显示
select(x,1:3)

也可以直接用列的编号表示要选择的列
select(x,mz=name)

选择列的时候,同时对列名进行重命名
select(x,cmm=starts_with("s"))

同样的可以对多列进行重命名,并选择
select(x,name,everything())

可以对数据进行排序,列较多的情况下把不需要排序的列用evything()直接列出。
下面使用mutate()函数对数据进行增加列。
mutate(x,yingyu=shuxue*1.2)
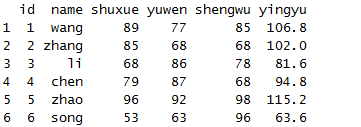
transmute(x,yingyu=shuxue*1.2)

可以看到,使用matate是在原来列的基础上增加一列,而使用transmute是新建一个数据框。
mutate(x,shuxue=NULL)
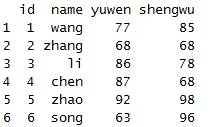
除了,增加列以外还可以把NULL赋值给列,已达到删除列的效果。