前面一篇讲了cast,想必已经见识到了reshape2的强大,当然在使用cast时配合上melt这种强大的揉数据能力才能表现的淋漓尽致。
下面我们来看下,melt这个函数以及它的特点。
melt(data, ..., na.rm = FALSE, value.name = "value")
从这里来看函数的参数也相对比较简单,data表示要处理的数据,na.rm表示缺失值处理办法,value.name用于重命名值所在列的名称
另外,melt函数的难点在于,不同数据结构,用到的参数可能是不一样的。
首先,要融合的数据为数组、表以及矩阵,那么melt的表达式为:
melt(data, varnames = names(dimnames(data)), ..., na.rm = FALSE, as.is = FALSE, value.name = "value")
varnames用户命名变量名称
其次,要融合的数据为数据框,那么melt的表达式为:
melt(data, id.vars, measure.vars, variable.name = "variable", ..., na.rm = FALSE, value.name = "value", factorsAsStrings = TRUE)
id.vars 设置融合后单独显示的变量,可以用变量位置及名称表示,没写表示使用所有非measure.vars值
measure.vars 通常根据id.vars 设置的变化而变化
最后,要融合的数据为列表,那么melt的表达式为:
melt(data, ..., level = 1)
下面来看些具体的例子
data<- array(c(1:22, NA,"wo"), c(2,3,4)) data

melt(data)
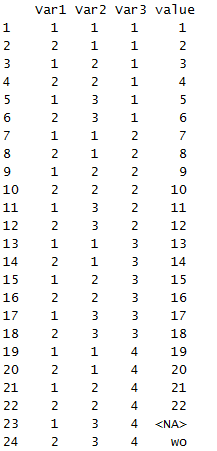
可以看出数据融合后,可读性比数组的情况下强了好多,var1表示数组的行,var2表示数组的列,var3表示数组序列。
比如,18位置就是第3数组,2行3列的位置,11则是第2数组,1行3列。
melt(a, na.rm = TRUE)

可以看到数组中的缺失值被移除了。
melt(data, varnames=c("hang","lie","Zu"))
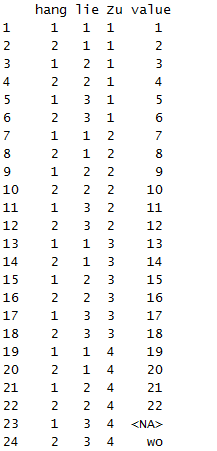
对融合后的每个变量进行重命名。
下面来看下数据为数据框的情况。
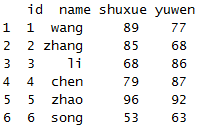
x<-data.frame(id=1:6,
name=c("wang","zhang","li","chen","zhao","song"),
shuxue=c(89,85,68,79,96,53),
yuwen=c(77,68,86,87,92,63))
x
melt(x,id=c("id","name"))
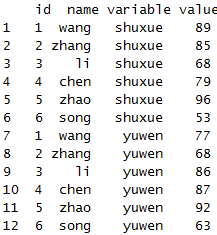
melt(x,id=1:2,variable.name="kemu",value.name="zhi")
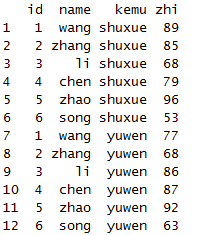
melt(x,measure.vars=c("id","name"))
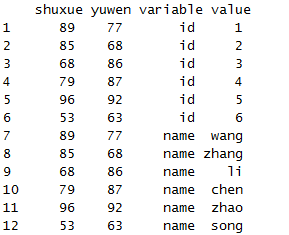
最后,来看下如果数据是列表的情况
shuju<- list(matrix(1:4, ncol=2), array(1:27, c(3,3,3)))
shuju

这个列表的机构比较复杂,读起来有点难度
下面melt融合后的结果
melt(shuju)
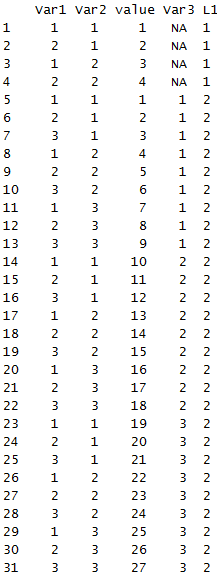
可以看出数据变得非常简洁。