全称 Hadoop Database
HBase 共有数据模型
RK: RowKey 行键
- 用来检索记录的主键,是一行数据的唯一标识
- 最长64KB,一般为10-100bytes。
CF:Column Family 列簇
- 在物理上包含了许多的列与值,每个列簇都有一些存储的属性可配置
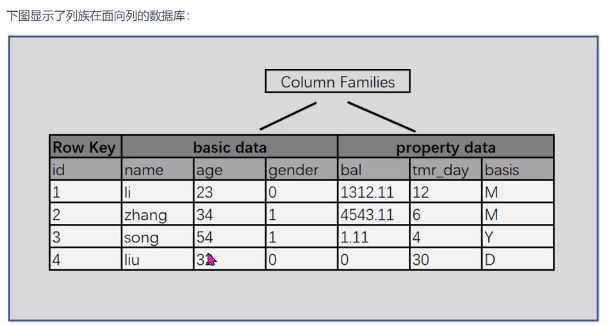
- 一般一个表中的列簇数不超过3个,列属于列簇,列簇属于表 。例如下表中的 basic data 和 property data。
CQ:Column Quallifier
- 列簇的限定词,理解为列的唯一标识。但是列标识是可以必变的,因此第一行可能有不同的列标识
- 使用的时候必须列簇:列 ,eg basic_data:name,不同于mysql 直接取 name
- 列可以根据需求动态添加或者删除,同一个表中不同行的数据列都可以不同

Cell:
- 由 rk , cf,cq,version 组成
- Cell 中的数据是没有类型的,全部是字节码形式存储,因为HDFS上的数据都是字节组成。
TS:Time Stamp
- 每个Cell 都保存着同一份数据的多个版本,版本通过时间戳来索引
- 时间戳的类型是64位整型,默认时间戳是精确到毫秒的当前系统时间,时间戳也可由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳
- 每个cell 中,不同版本的数据按照时间倒序排序 ,即最新的数据排在最前面。查询数据的时候,如果不指定版本数,默认显示版本号最新(高)的数据
- 为了避免数据存在过多版本中造成管理(包括存储和索引)负担,HBase 提供了两种数据版本回收方式:一是保存数据的最后n个版本; 二是保存最近一段时间内的版本(比如最近七天)
总结:
HBase 是一个稀疏的、分布式、持久、多维、排序的映射,它以行键(row key),列键(column key) 和时间戳(timestamp)为索引。
HBase 在存储数据的时候,有两个 SortedMap ,首先按照 rowkey进行字典排序 ,然后再对Column 进行字典排序。